In the last post, we looked at the Nyström approximation to an  positive semidefinite (psd) matrix
positive semidefinite (psd) matrix  . A special case was the column Nyström approximation, defined to be1We use Matlab index notation to indicate submatrices of .
. A special case was the column Nyström approximation, defined to be1We use Matlab index notation to indicate submatrices of .
(Nys) ![\[\hat{A} = A(:,S) \, A(S,S)^{-1} \, A(S,:), \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-83dad2a726f818fda82b8a1c428de9fe_l3.png "Rendered by QuickLaTeX.com")
where  identifies a subset of
identifies a subset of  columns of . Provided
columns of . Provided  , this allowed us to approximate all
, this allowed us to approximate all  entries of the matrix using only the
entries of the matrix using only the  entries in columns
entries in columns  of , a huge savings of computational effort!
of , a huge savings of computational effort!
With the column Nyström approximation presented just as such, many questions remain:
- Why this formula?
- Where did it come from?
- How do we pick the columns ?
- What is the residual
 of the approximation?
of the approximation?
In this post, we will answer all of these questions by drawing a connection between low-rank approximation by Nyström approximation and solving linear systems of equations by Gaussian elimination. The connection between these two seemingly unrelated areas of matrix computations will pay dividends, leading to effective algorithms to compute Nyström approximations by the (partial) Cholesky factorization of a positive (semi)definite matrix and an elegant description of the residual of the Nyström approximation as the Schur complement.
Cholesky: Solving Linear Systems
Suppose we want solve the system of linear equations  , where is a real invertible matrix and
, where is a real invertible matrix and  is a vector of length
is a vector of length  . The standard way of doing this in modern practice (at least for non-huge matrices ) is by means of Gaussian elimination/LU factorization. We factor the matrix as a product
. The standard way of doing this in modern practice (at least for non-huge matrices ) is by means of Gaussian elimination/LU factorization. We factor the matrix as a product  of a lower triangular matrix
of a lower triangular matrix  and an upper triangular matrix
and an upper triangular matrix  .2To make this accurate, we usually have to reorder the rows of the matrix as well. Thus, we actually compute a factorization
.2To make this accurate, we usually have to reorder the rows of the matrix as well. Thus, we actually compute a factorization  where
where  is a permutation matrix and and are triangular. The system is solved by first solving
is a permutation matrix and and are triangular. The system is solved by first solving  for
for  and then
and then  for
for  ; the triangularity of and make solving the associated systems of linear equations easy.
; the triangularity of and make solving the associated systems of linear equations easy.
For real symmetric positive definite matrix , a simplification is possible. In this case, one can compute an LU factorization where the matrices and are transposes of each other,  . This factorization
. This factorization  is known as a Cholesky factorization of the matrix .
is known as a Cholesky factorization of the matrix .
The Cholesky factorization can be easily generalized to allow the matrix to be complex-valued. For a complex-valued positive definite matrix , its Cholesky decomposition takes the form  , where is again a lower triangular matrix. All that has changed is that the transpose
, where is again a lower triangular matrix. All that has changed is that the transpose  has been replaced by the conjugate transpose
has been replaced by the conjugate transpose  . We shall work with the more general complex case going forward, though the reader is free to imagine all matrices as real and interpret the operation as ordinary transposition if they so choose.
. We shall work with the more general complex case going forward, though the reader is free to imagine all matrices as real and interpret the operation as ordinary transposition if they so choose.
Schur: Computing the Cholesky Factorization
Here’s one way of computing the Cholesky factorization using recursion. Write the matrix in block form as
![\[A = \twobytwo{A_{11}}{A_{12}}{A_{21}}{A_{22}}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ae6ce117b98f97e989edc3581edf3798_l3.png "Rendered by QuickLaTeX.com")
Our first step will be “block Cholesky factorize” the matrix , factoring as a product of matrices which are only block triangular. Then, we’ll “upgrade” this block factorization into a full Cholesky factorization.
The core idea of Gaussian elimination is to combine rows of a matrix to introduce zero entries. For our case, observe that multiplying the first block row of by  and subtracting this from the second block row introduces a matrix of zeros into the bottom left block of . (The matrix
and subtracting this from the second block row introduces a matrix of zeros into the bottom left block of . (The matrix  is a principal submatrix of and is therefore guaranteed to be positive definite and thus invertible.3To directly see is positive definite, for instance, observe that since is positive definite,
is a principal submatrix of and is therefore guaranteed to be positive definite and thus invertible.3To directly see is positive definite, for instance, observe that since is positive definite,  for every nonzero vector .) In matrix language,
for every nonzero vector .) In matrix language,
![\[\twobytwo{I}{0}{-A_{21}A_{11}^{-1}}{I}\twobytwo{A_{11}}{A_{12}}{A_{21}}{A_{22}} = \twobytwo{A_{11}}{A_{12}}{0}{A_{22} - A_{21}A_{11}^{-1}A_{12}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5ae1afb8327a292b2fe794be32f3593c_l3.png "Rendered by QuickLaTeX.com")
Isolating on the left-hand side of this equation by multiplying by
![\[\twobytwo{I}{0}{-A_{21}A_{11}^{-1}}{I}^{-1} = \twobytwo{I}{0}{A_{21}A_{11}^{-1}}{I}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1f9a1b531d93fe36130ddc2ddb47b404_l3.png "Rendered by QuickLaTeX.com")
yields the block triangular factorization
![\[A = \twobytwo{A_{11}}{A_{12}}{A_{21}}{A_{22}} = \twobytwo{I}{0}{A_{21}A_{11}^{-1}}{I} \twobytwo{A_{11}}{A_{12}}{0}{A_{22} - A_{21}A_{11}^{-1}A_{12}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4fdfe06a63d204e626cd2a3af6293560_l3.png "Rendered by QuickLaTeX.com")
We’ve factored into block triangular pieces, but these pieces are not (conjugate) transposes of each other. Thus, to make this equation more symmetrical, we can further decompose
(1) ![\[A = \twobytwo{A_{11}}{A_{12}}{A_{21}}{A_{22}} = \twobytwo{I}{0}{A_{21}A_{11}^{-1}}{I} \twobytwo{A_{11}}{0}{0}{A_{22} - A_{21}A_{11}^{-1}A_{12}} \twobytwo{I}{0}{A_{21}A_{11}^{-1}}{I}^*. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3513d20b54d99c02212552d42e55af1f_l3.png "Rendered by QuickLaTeX.com")
This is a block version of the Cholesky decomposition of the matrix taking the form  , where is a block lower triangular matrix and
, where is a block lower triangular matrix and  is a block diagonal matrix.
is a block diagonal matrix.
We’ve met the second of our main characters, the Schur complement
(Sch) ![\[S = A_{22} - A_{21}A_{11}^{-1}A_{12}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-28f855d43449bba094482c593a1613d3_l3.png "Rendered by QuickLaTeX.com")
This seemingly innocuous combination of matrices has a tendency to show up in surprising places when one works with matrices.4See my post on the Schur complement for more examples. It’s appearance in any one place is unremarkable, but the shear ubiquity of  in matrix theory makes it deserving of its special name, the Schur complement. To us for now, the Schur complement is just the matrix appearing in the bottom right corner of our block Cholesky factorization.
in matrix theory makes it deserving of its special name, the Schur complement. To us for now, the Schur complement is just the matrix appearing in the bottom right corner of our block Cholesky factorization.
The Schur complement enjoys the following property:5This property is a consequence of equation (1) together with the conjugation rule for positive (semi)definiteness, which I discussed in this previous post.
Positivity of the Schur complement: If
is positive (semi)definite, then the Schur complement
is positive (semi)definite.
As a consequence of this property, we conclude that both and  are positive definite.
are positive definite.
With the positive definiteness of the Schur complement in hand, we now return to our Cholesky factorization algorithm. Continue by recursively6As always with recursion, one needs to specify the base case. For us, the base case is just that Cholesky decomposition of a  matrix is
matrix is  . computing Cholesky factorizations of the diagonal blocks
. computing Cholesky factorizations of the diagonal blocks
![\[A_{11} = L_{11}^{\vphantom{*}}L_{11}^*, \quad S = L_{22}^{\vphantom{*}}L_{22}^*.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-285220ef3b41cb3fec33809df5491a3e_l3.png "Rendered by QuickLaTeX.com")
Inserting these into the block  factorization (1) and simplifying gives a Cholesky factorization, as desired:
factorization (1) and simplifying gives a Cholesky factorization, as desired:
![\[A = \twobytwo{L_{11}}{0}{A_{21}^{\vphantom{*}}(L_{11}^{*})^{-1}}{L_{22}}\twobytwo{L_{11}}{0}{A_{21}^{\vphantom{*}}(L_{11}^{*})^{-1}}{L_{22}}^* =: LL^*.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4674c5a860b79de116a1626dbdba5bdf_l3.png "Rendered by QuickLaTeX.com")
Voilà, we have obtained a Cholesky factorization of a positive definite matrix !
By unwinding the recursions (and always choosing the top left block to be of size ), our recursive Cholesky algorithm becomes the following iterative algorithm: Initialize to be the zero matrix. For  , perform the following steps:
, perform the following steps:
- Update . Set the
 th column of :
th column of : ![\[L(j:N,j) \leftarrow A(j:N,j)/\sqrt{a_{jj}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6b8a0d317668f3a7c98d93f7fa796853_l3.png "Rendered by QuickLaTeX.com")
- Update . Update the bottom right portion of to be the Schur complement:
![\[A(j+1:N,j+1:N)\leftarrow A(j+1:N,j+1:N) - \frac{A(j+1:N,j)A(j,j+1:N)}{a_{jj}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a39a6cf3aca3921ed37cf7236e920a16_l3.png "Rendered by QuickLaTeX.com")
This iterative algorithm is how Cholesky factorization is typically presented in textbooks.
Nyström: Using Cholesky Factorization for Low-Rank Approximation
Our motivating interest in studying the Cholesky factorization was the solution of linear systems of equations for a positive definite matrix . We can also use the Cholesky factorization for a very different task, low-rank approximation.
Let’s first look at things through the lense of the recursive form of the Cholesky factorization. The first step of the factorization was to form the block Cholesky factorization
![\[A = \twobytwo{I}{0}{A_{21}A_{11}^{-1}}{I} \twobytwo{A_{11}}{0}{0}{A_{22} - A_{21}A_{11}^{-1}A_{12}} \twobytwo{I}{0}{A_{21}A_{11}^{-1}}{I}^*.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0678dfc0f316a4983dee04390c09c4e0_l3.png "Rendered by QuickLaTeX.com")
Suppose that we choose the top left block to be of size  , where is much smaller than . The most expensive part of the Cholesky factorization will be the recursive factorization of the Schur complement
, where is much smaller than . The most expensive part of the Cholesky factorization will be the recursive factorization of the Schur complement  , which is a large matrix of size
, which is a large matrix of size  .
.
To reduce computational cost, we ask the provocative question: What if we simply didn’t factorize the Schur complement? Observe that we can write the block Cholesky factorization as a sum of two terms
(2) ![\[A = \twobyone{I}{A_{21}{A_{11}^{-1}}} A_{11} \twobyone{I}{A_{22}{A_{11}^{-1}}}^* + \twobytwo{0}{0}{0}{A_{22}-A_{21}A_{11}^{-1}A_{12}}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-034c2475b75c273396ed98bec4994b19_l3.png "Rendered by QuickLaTeX.com")
We can use the first term of this sum as a rank- approximation to the matrix . The low-rank approximation, which we can write out more conveniently as
![\[\hat{A} = \twobyone{A_{11}}{A_{21}} A_{11}^{-1} \onebytwo{A_{11}}{A_{12}} = \twobytwo{A_{11}}{A_{12}}{A_{21}}{A_{21}A_{11}^{-1}A_{12}},\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8693172c386656c773ff58b159f8b9f4_l3.png "Rendered by QuickLaTeX.com")
is the column Nyström approximation (Nys) to associated with the index set  and is the final of our three titular characters. The residual of the Nyström approximation is the second term in (2), which is none other than the Schur complement (Sch), padded by rows and columns of zeros:
and is the final of our three titular characters. The residual of the Nyström approximation is the second term in (2), which is none other than the Schur complement (Sch), padded by rows and columns of zeros:
![\[A - \hat{A} = \twobytwo{0}{0}{0}{A_{22}-A_{21}A_{11}^{-1}A_{12}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-45ce841e22a8d43c239a34b556cf3042_l3.png "Rendered by QuickLaTeX.com")
Observe that the approximation  is obtained from the process of terminating a Cholesky factorization midway through algorithm execution, so we say that the Nyström approximation results from a partial Cholesky factorization of the matrix .
is obtained from the process of terminating a Cholesky factorization midway through algorithm execution, so we say that the Nyström approximation results from a partial Cholesky factorization of the matrix .
Summing things up:
If we perform a partial Cholesky factorization on a positive (semi)definite matrix, we obtain a low-rank approximation known as the column Nyström approximation. The residual of this approximation is the Schur complement, padded by rows and columns of zeros.
The idea of obtaining a low-rank approximation from a partial matrix factorization is very common in matrix computations. Indeed, the optimal low-rank approximation to a real symmetric matrix is obtained by truncating its eigenvalue decomposition and the optimal low-rank approximation to a general matrix is obtained by truncating its singular value decomposition. While the column Nyström approximation is not the optimal rank- approximation to (though it does satisfy a weaker notion of optimality, as discussed in this previous post), it has a killer feature not possessed by the optimal approximation:
The column Nyström approximation is formed from only
Unfortunately there’s not a free lunch here. The column Nyström is only a good low-rank approximation if the Schur complement has small entries. In general, this need not be the case. Fortunately, we can improve our situation by means of pivoting.
Our iterative Cholesky algorithm first performs elimination using the entry in position  followed by position
followed by position  and so on. There’s no need to insist on this exact ordering of elimination steps. Indeed, at each step of the Cholesky algorithm, we can choose whichever diagonal position
and so on. There’s no need to insist on this exact ordering of elimination steps. Indeed, at each step of the Cholesky algorithm, we can choose whichever diagonal position  that we want to perform elimination. The entry we choose to perform elimination with is called a pivot.
that we want to perform elimination. The entry we choose to perform elimination with is called a pivot.
Obtaining good column Nyström approximations requires identifying the a good choice for the pivots to reduce the size of the entries of the Schur complement at each step of the algorithm. With general pivot selection, an iterative algorithm for computing a column Nyström approximation by partial Cholesky factorization proceeds as follows: Initialize an  matrix
matrix  to store the column Nyström approximation
to store the column Nyström approximation  , in factored form. For
, in factored form. For  , perform the following steps:
, perform the following steps:
- Select pivot. Choose a pivot
 .
. - Update the approximation.
 .
. - Update the residual.
 .
.
This procedure results in the Nyström approximation (Nys) with column set  :
:
![\[\hat{A} = FF^* = A(:,S) \, A(S,S)^{-1} \, A(S,:).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0f8c4bf0d007a5d80119576ec96843c6_l3.png "Rendered by QuickLaTeX.com")
The pivoted Cholesky steps 1–3 requires updating the entire matrix at every step. With a little more cleverness, we can optimize this procedure to only update the entries of the matrix we need to form the approximation . See Algorithm 2 in this preprint of my coauthors and I for details.
How should we choose the pivots? Two simple strategies immediately suggest themselves:
- Uniformly random. At each step , select uniformly at random from among the un-selected pivot indices.
- Greedy.7The greedy pivoting selection is sometimes known as diagonal pivoting or complete pivoting in the numerical analysis literature. At each step , select according to the largest diagonal entry of the current residual :
![\[s_j = \argmax_{1\le k\le N} a_{kk}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-76574bc2621e4d22e766a5bb6eaf7372_l3.png "Rendered by QuickLaTeX.com")
The greedy strategy often (but not always) works well, and the uniformly random approach can work surprisingly well if the matrix is “incoherent”, with all rows and columns of the matrix possessing “similar importance”.
Despite often working fairly well, both the uniform and greedy schemes can fail significantly, producing very low-quality approximations. My research (joint with Yifan Chen, Joel A. Tropp, and Robert J. Webber) has investigated a third strategy striking a balance between these two approaches:
- Diagonally weighted random. At each step , select at random according to the probability weights based on the current diagonal of the matrix
![\[\mathbb{P} \{ s_j = k \} = \frac{a_{kk}}{\operatorname{tr} A}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6e578e1b3233b52f7c3f4313a9a2fa48_l3.png "Rendered by QuickLaTeX.com")
Our paper provides theoretical analysis and empirical evidence showing that this diagonally-weighted random pivot selection (which we call randomly pivoted Cholesky aka RPCholesky) performs well at approximating all positive semidefinite matrices , even those for which uniform random and greedy pivot selection fail. The success of this approach can be seen in the following examples (from Figure 1 in the paper), which shows RPCholesky can produce much smaller errors than the greedy and uniform methods.
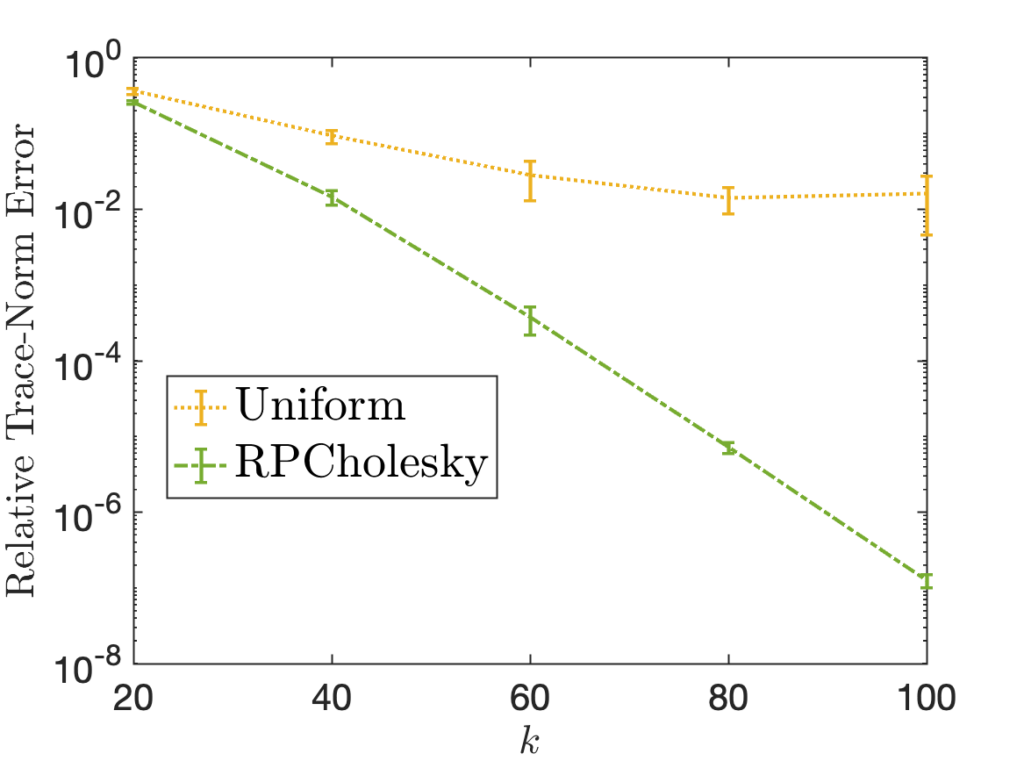
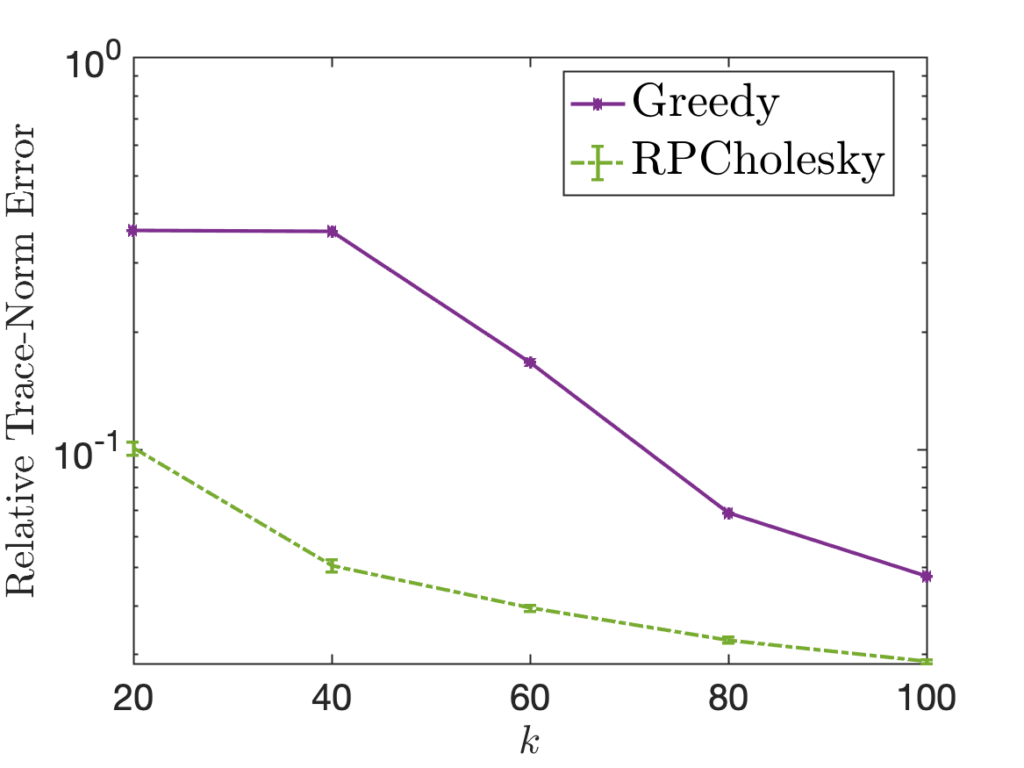
Conclusions
In this post, we’ve seen that a column Nyström approximation can be obtained from a partial Cholesky decomposition. The residual of the approximation is the Schur complement. I hope you agree that this is a very nice connection between these three ideas. But beyond its mathematical beauty, why do we care about this connection? Here are my reasons for caring:
- Analysis. Cholesky factorization and the Schur complement are very well-studied in matrix theory. We can use known facts about Cholesky factorization and Schur complements to prove things about the Nyström approximation, as we did when we invoked the positivity of the Schur complement.
- Algorithms. Cholesky factorization-based algorithms like randomly pivoted Cholesky are effective in practice at producing high-quality column Nyström approximations.
On a broader level, our tale of Nyström, Cholesky, and Schur demonstrates that there are rich connections between low-rank approximation and (partial versions of) classical matrix factorizations like LU (with partial pivoting), Cholesky, QR, eigendecomposition, and SVD for to full-rank matrices. These connections can be vital to analyzing low-rank approximation algorithms and developing improvements.
2 thoughts on “Low-Rank Approximation Toolbox: Nyström, Cholesky, and Schur”