This post is about randomized algorithms for problems in computational science and a powerful set of tools, known as concentration inequalities, which can be used to analyze why they work. I’ve discussed why randomization can help in solving computational problems in a previous post; this post continues this discussion by presenting an example of a computational problem where, somewhat surprisingly, a randomized algorithm proves effective. We shall then use concentration inequalities to analyze why this method works.
Triangle Counting
Let’s begin our discussion of concentration inequalities by means of an extended example. Consider the following question: How many triangles are there in the Facebook network? That is, how many trios of people are there who are all mutual friends? While seemingly silly at first sight, this is actually a natural and meaningful question about the structure of the Facebook social network and is related to similar questions such as “How likely are two friends of a person to also be friends with each other?”
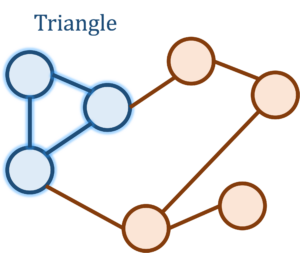
If there are  people on the Facebook graph, then the natural algorithm of iterating over all
people on the Facebook graph, then the natural algorithm of iterating over all  triplets and checking whether they form a triangle is far too computationally costly for the billions of Facebook accounts. Somehow, we want to do much faster than this, and to achieve this speed we would be willing to settle for an estimate of the triangle count up to some error.
triplets and checking whether they form a triangle is far too computationally costly for the billions of Facebook accounts. Somehow, we want to do much faster than this, and to achieve this speed we would be willing to settle for an estimate of the triangle count up to some error.
There are many approaches to this problem, but let’s describe a particularly surprising algorithm. Let  be an
be an  matrix where the
matrix where the  th entry of is
th entry of is  if users
if users  and
and  are friends and
are friends and  otherwise1All of the diagonal entries of are set to zero.; this matrix is called the adjacency matrix of the Facebook graph. A fact from graph theory is that the th entry of the cube
otherwise1All of the diagonal entries of are set to zero.; this matrix is called the adjacency matrix of the Facebook graph. A fact from graph theory is that the th entry of the cube  of the matrix counts the number of paths from user to user of length three.2By a path of length three, we mean a sequence of users
of the matrix counts the number of paths from user to user of length three.2By a path of length three, we mean a sequence of users  where and
where and  , and
, and  , and and are all friends. In particular, the
, and and are all friends. In particular, the  th entry of denotes the number of paths from to itself of length
th entry of denotes the number of paths from to itself of length  , which is twice the number of triangles incident on . (The paths
, which is twice the number of triangles incident on . (The paths  and
and  are both counted as paths of length 3 for a triangle consisting of , , and .) Therefore, the trace of , equal to the sum of its diagonal entries, is six times the number of triangles: The th entry of is twice the number of triangles incident on and each triangle
are both counted as paths of length 3 for a triangle consisting of , , and .) Therefore, the trace of , equal to the sum of its diagonal entries, is six times the number of triangles: The th entry of is twice the number of triangles incident on and each triangle  is counted thrice in the th,
is counted thrice in the th,  th, and
th, and  th entries of . In summary, we have
th entries of . In summary, we have

Therefore, the triangle counting problem is equivalent to computing the trace of . Unfortunately, the problem of computing is, in general, very computationally costly. Therefore, we seek ways of estimating the trace of a matrix without forming it.
Randomized Trace Estimation
Motivated by the triangle counting problem from the previous section, we consider the problem of estimating the trace of a matrix  . We assume that we only have access to the matrix through matrix–vector products; that is, we can efficiently compute
. We assume that we only have access to the matrix through matrix–vector products; that is, we can efficiently compute  for a vector
for a vector  . For instance, in the previous example, the Facebook graph has many fewer friend relations (edges)
. For instance, in the previous example, the Facebook graph has many fewer friend relations (edges)  than the maximum possible amount of
than the maximum possible amount of  . Therefore, the matrix is sparse; in particular, matrix–vector multiplications with can be computed in around operations. To compute matrix–vector products with
. Therefore, the matrix is sparse; in particular, matrix–vector multiplications with can be computed in around operations. To compute matrix–vector products with  , we simply compute matrix–vector products with three times,
, we simply compute matrix–vector products with three times,  .
.
Here’s a very nifty idea to estimate the trace of using only matrix–vector products, originally due to Didier A. Girard and Michael F. Hutchinson. Choose to be a random vector whose entries are independent  -values, where each value
-values, where each value  and
and  occurs with equal
occurs with equal  probability. Then if one forms the expression
probability. Then if one forms the expression  . Since the entries of
. Since the entries of  and
and  are independent, the expectation of
are independent, the expectation of  is for
is for  and for
and for  . Consequently, by linearity of expectation, the expected value of
. Consequently, by linearity of expectation, the expected value of  is
is
![\begin{equation*} \mathbb{E} \, x^\top M x = \sum_{i,j=1}^n M_{ij} \mathbb{E} [x_ix_j] = \sum_{i = 1}^n M_{ii} = \operatorname{tr}(M). \end{equation*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-17a6a7cacc94a45f13853dc8f34f1e3a_l3.png "Rendered by QuickLaTeX.com")
The average value of is equal to the trace of ! In the language of statistics, we might say that is an unbiased estimator for  . Thus, the efficiently computable quantity can serve as a (crude) estimate for .
. Thus, the efficiently computable quantity can serve as a (crude) estimate for .
While the expectation of  equals , any random realization of can deviate from by a non-neligible amount. Thus, to reduce the variability of the estimator , it is appropriate to take an average of multiple copies of this random estimate. Specifically, we draw random vectors with independent random entries
equals , any random realization of can deviate from by a non-neligible amount. Thus, to reduce the variability of the estimator , it is appropriate to take an average of multiple copies of this random estimate. Specifically, we draw random vectors with independent random entries  and compute the averaged trace estimator
and compute the averaged trace estimator
(1) 
The -sample trace estimator  remains an unbiased estimator for ,
remains an unbiased estimator for ,  , but with reduced variability. Quantitatively, the variance of is times smaller than the single-sample estimator :
, but with reduced variability. Quantitatively, the variance of is times smaller than the single-sample estimator :
(2) 
The Girard–Hutchinson trace estimator gives a natural way of estimating the trace of the matrix , a task which might otherwise be hard without randomness.3To illustrate what randomness is buying us here, it might be instructive to think about how one might try to estimate the trace of via matrix–vector products without the help of randomness. For the trace estimator to be a useful tool, an important question remains: How many samples are needed to compute to a given accuracy? Concentration inequalities answer questions of this nature.
Concentration Inequalities
A concentration inequality provides a bound on the probability a random quantity is significantly larger or smaller than its typical value. Concentration inequalities are useful because they allow us to prove statements like “With at least 99% probability, the randomized trace estimator with 100 samples produces an approximation of the trace which is accurate up to error no larger than  .” In other words, concentration inequalities can provide quantitative estimates of the likely size of the error when a randomized algorithm is executed.
.” In other words, concentration inequalities can provide quantitative estimates of the likely size of the error when a randomized algorithm is executed.
In this section, we shall introduce a handful of useful concentration inequalities, which we will apply to the randomized trace estimator in the next section. We’ll then discuss how these and other concentration inequalities can be derived in the following section.
Markov’s Inequality
Markov’s inequality is the most fundamental concentration inequality. When used directly, it is a blunt instrument, requiring little insight to use and producing a crude but sometimes useful estimate. However, as we shall see later, all of the sophisticated concentration inequalities that will follow in this post can be derived from a careful use of Markov’s inequality.
The wide utility of Markov’s inequality is a consequence of the minimal assumptions needed for its use. Let  be any nonnegative random variable. Markov’s inequality states that the probability that exceeds a level
be any nonnegative random variable. Markov’s inequality states that the probability that exceeds a level  is bounded by the expected value of over
is bounded by the expected value of over  . In equations, we have
. In equations, we have
(3) 
We stress the fact that we make no assumptions on how the random quantity is generated other than that is nonnegative.
As a short example of Markov’s inequality, suppose we have a randomized algorithm which takes one second on average to run. Markov’s inequality then shows that the probability the algorithm takes more than 100 seconds to run is at most  . This small example shows both the power and the limitation of Markov’s inequality. On the negative side, our analysis suggests that we might have to wait as much as 100 times the average runtime for the algorithm to complete running with 99% probability; this large huge multiple of 100 seems quite pessimistic. On the other hand, we needed no information whatsoever about how the algorithm works to do this analysis. In general, Markov’s inequality cannot be improved without more assumptions on the random variable .4For instance, imagine an algorithm which 99% of the time completes instantly and 1% of the time takes 100 seconds. This algorithm does have an average runtime of 1 second, but the conclusion of Markov’s inequality that the runtime of the algorithm can be as much as 100 times the average runtime with 1% probability is true.
. This small example shows both the power and the limitation of Markov’s inequality. On the negative side, our analysis suggests that we might have to wait as much as 100 times the average runtime for the algorithm to complete running with 99% probability; this large huge multiple of 100 seems quite pessimistic. On the other hand, we needed no information whatsoever about how the algorithm works to do this analysis. In general, Markov’s inequality cannot be improved without more assumptions on the random variable .4For instance, imagine an algorithm which 99% of the time completes instantly and 1% of the time takes 100 seconds. This algorithm does have an average runtime of 1 second, but the conclusion of Markov’s inequality that the runtime of the algorithm can be as much as 100 times the average runtime with 1% probability is true.
Chebyshev’s Inequality and Averages
The variance of a random variable describes the expected size of a random variable’s deviation from its expected value. As such, we would expect that the variance should provide a bound on the probability a random variable is far from its expectation. This intuition indeed is correct and is manifested by Chebyshev’s inequality. Let be a random variable (with finite expected value) and . Chebyshev’s inequality states that the probability that deviates from its expected value by more than is at most  :
:
(4) 
Chebyshev’s inequality is frequently applied to sums or averages of independent random quantities. Suppose  are independent and identically distributed random variables with mean
are independent and identically distributed random variables with mean  and variance
and variance  and let
and let  denote the average
denote the average

Since the random variables are independent,5In fact, this calculation works if are only pairwise independent or even pairwise uncorrelated. For algorithmic applications, this means that don’t have to be fully independent of each other; we just need any pair of them to be uncorrelated. This allows many randomized algorithms to be “derandomized“, reducing the amount of “true” randomness needed to execute an algorithm. the properties of variance entail that

where we use the fact that  . Therefore, by Chebyshev’s inequality,
. Therefore, by Chebyshev’s inequality,
(5) 
Suppose we want to estimate the mean by up to error  and are willing to tolerate a failure probability of
and are willing to tolerate a failure probability of  . Then setting the right-hand side of (5) to , Chebyshev’s inequality suggests that we need at most
. Then setting the right-hand side of (5) to , Chebyshev’s inequality suggests that we need at most
(6) 
samples to achieve this goal.
Exponential Concentration: Hoeffding and Bernstein
How happy should we be with the result (6) of applying Chebyshev’s inequality the average ? The central limit theorem suggests that should be approximately normally distributed with mean and variance  . Normal random variables have an exponentially small probability of being more than a few standard deviations above their mean, so it is natural to expect this should be true of as well. Specifically, we expect a bound roughly like
. Normal random variables have an exponentially small probability of being more than a few standard deviations above their mean, so it is natural to expect this should be true of as well. Specifically, we expect a bound roughly like
(7) 
Unfortunately, we don’t have a general result quite this nice without additional assumptions, but there are a diverse array of exponential concentration inequalities available which are quite useful in analyzing sums (or averages) of independent random variables that appear in applications.
Hoeffding’s inequality is one such bound. Let be independent (but not necessarily identically distributed) random variables and consider the average  . Hoeffding’s inequality makes the assumption that the summands are bounded, say within an interval
. Hoeffding’s inequality makes the assumption that the summands are bounded, say within an interval ![[a,b]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-336bb22d4b2092329486008f6665b888_l3.png "Rendered by QuickLaTeX.com") .6There are also more general versions of Hoeffding’s inequality where the bound on each random variable is different. Hoeffding’s inequality then states that
.6There are also more general versions of Hoeffding’s inequality where the bound on each random variable is different. Hoeffding’s inequality then states that
(8) 
Hoeffding’s inequality is quite similar to the ideal concentration result (7) except with the variance  replaced by the potentially much larger quantity7Note that is always smaller than or equal to
replaced by the potentially much larger quantity7Note that is always smaller than or equal to  . .
. .
Bernstein’s inequality fixes this deficit in Hoeffding’s inequality at a small cost. Now, instead of assuming are bounded within the interval , we make the alternate boundedness assumption  for every
for every  . We continue to denote so that if are identically distributed, denotes the variance of each of . Bernstein’s inequality states that
. We continue to denote so that if are identically distributed, denotes the variance of each of . Bernstein’s inequality states that
(9) 
For small values of , Bernstein’s inequality yields exactly the kind of concentration that we would hope for from our central limit theorem heuristic (7). However, for large values of , we have

which is exponentially small in rather than  . We conclude that Bernstein’s inequality provides sharper bounds then Hoeffding’s inequality for smaller values of but weaker bounds for larger values of .
. We conclude that Bernstein’s inequality provides sharper bounds then Hoeffding’s inequality for smaller values of but weaker bounds for larger values of .
Chebyshev vs. Hoeffding vs. Bernstein
Let’s return to the situation where we seek to estimate the mean of independent and identically distributed random variables each with variance by using the averaged value . Our goal is to bound how many samples we need to estimate up to error ,  , except with failure probability at most . Using Chebyshev’s inequality, we showed that (see (7))
, except with failure probability at most . Using Chebyshev’s inequality, we showed that (see (7))

Now, let’s try using Hoeffding’s inequality. Suppose that are bounded in the interval . Then Hoeffding’s inequality (8) shows that

Bernstein’s inequality states that if lie in the interval ![[\mu-B,\mu+B]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bada0c6b976891e43bcc4c3b7508e96e_l3.png "Rendered by QuickLaTeX.com") for every
for every  , then
, then
(10) 
Hoeffding’s and Bernstein’s inequality show that we need roughly proportional to  samples are needed rather than proportional to
samples are needed rather than proportional to  . The fact that we need proportional to
. The fact that we need proportional to  samples to achieve error is a consequence of the central limit theorem and is something we would not be able to improve with any concentration inequality. What exponential concentration inequalities allow us to do is to improve the dependence on the failure probability from proportional to
samples to achieve error is a consequence of the central limit theorem and is something we would not be able to improve with any concentration inequality. What exponential concentration inequalities allow us to do is to improve the dependence on the failure probability from proportional to  to
to  , which is a huge improvement.
, which is a huge improvement.
Hoeffding’s and Bernstein’s inequalities both have a small drawback. For Hoeffding’s inequality, the constant of proportionality is rather than the true variance of the summands. Bernstein’s inequality gives us the “correct” constant of proportionality but adds a second term proportional to  ; for small values of , this term is dominated by the term proportional to but the second term can be relevant for larger values of .
; for small values of , this term is dominated by the term proportional to but the second term can be relevant for larger values of .
There are a panoply of additional concentration inequalities than the few we’ve mentioned. We give a selected overview in the following optional section.
Analysis of Randomized Trace Estimation
Let us apply some of the concentration inequalities we introduced in last section to analyze the randomized trace estimator. Our goal is not to provide the best possible analysis of the trace estimator,8More precise estimation for trace estimation applied to positive semidefinite matrices was developed by Gratton and Titley-Peloquin; see Theorem 4.5 of the following survey. but to demonstrate how the general concentration inequalities we’ve developed can be useful “out of the box” in analyzing algorithms.
In order to apply Chebyshev’s and Berstein’s inequalities, we shall need to compute or bound the variance of the single-sample trace estimtor , where is a random vector of independent -values. This is a straightforward task using properties of the variance:

Here,  is the covariance and
is the covariance and  is the matrix Frobenius norm. Chebyshev’s inequality (5), then gives
is the matrix Frobenius norm. Chebyshev’s inequality (5), then gives

Let’s now try applying an exponential concentration inequality. We shall use Bernstein’s inequality, for which we need to bound  . By the Courant–Fischer minimax principle, we know that is between
. By the Courant–Fischer minimax principle, we know that is between  and
and  where
where  and
and  are the smallest and largest eigenvalues of and
are the smallest and largest eigenvalues of and  is the Euclidean norm of the vector . Since all the entries of have absolute value , we have
is the Euclidean norm of the vector . Since all the entries of have absolute value , we have  so is between
so is between  and
and  . Since the trace equals the sum of the eigenvalues of , is also between and . Therefore,
. Since the trace equals the sum of the eigenvalues of , is also between and . Therefore,

where  denotes the matrix spectral norm. Therefore, by Bernstein’s inequality (9), we have
denotes the matrix spectral norm. Therefore, by Bernstein’s inequality (9), we have

In particular, (10) shows that

samples suffice to estimate to error with failure probability at most . Concentration inequalities easily furnish estimates for the number of samples needed for the randomized trace estimator.
We have now accomplished our main goal of using concentration inequalities to analyze the randomized trace estimator, which in turn can be used to solve the triangle counting problem. We leave some additional comments on trace estimation and triangle counting in the following bonus section.
 and
and  . Since we often don’t know good bounds for and
. Since we often don’t know good bounds for and  , one should really use the trace estimator together with an a posteriori error estimates for the trace estimator, which provide a confidence interval for the trace rather than a point estimate; see sections 4.5 and 4.6 in this survey for details.
, one should really use the trace estimator together with an a posteriori error estimates for the trace estimator, which provide a confidence interval for the trace rather than a point estimate; see sections 4.5 and 4.6 in this survey for details.
One can improve on the Girard–Hutchinson trace estimator by using a variance reduction technique. One such variance reduction technique was recently proposed under the name Hutch++, extending ideas by Arjun Singh Gambhir, Andreas Stathopoulos, and Kostas Orginos and Lin Lin. In effect, these techniques improve the number of samples needed to estimate the trace of a positive semidefinite matrix to relative error to proportional to  down from .
down from .
Several algorithms have been proposed for triangle counting, many of them randomized. This survey gives a comparison of different methods for the triangle counting problem, and also describes more motivation and applications for the problem.
Deriving Concentration Inequalities
Having introduced concentration inequalities and applied them to the randomized trace estimator, we now turn to the question of how to derive concentration inequalities. Learning how to derive concentration inequalities is more than a matter of mathematical completeness since one can often obtain better results by “hand-crafting” a concentration inequality for a particular application rather than applying a known concentration inequality. (Though standard concentration inequalities like Hoeffding’s and Bernstein’s often give perfectly adequate answers with much less work.)
Markov’s Inequality
At the most fundamental level, concentration inequalities require us to bound a probability by an expectation. In achieving this goal, we shall make a simple observation: The probability that is larger than or equal to is the expectation of a random variable  .9More generally, the probability of an event can be written as an expectation of the indicator random variable of that event. Here,
.9More generally, the probability of an event can be written as an expectation of the indicator random variable of that event. Here,  is an indicator function which outputs one if its input is larger than or equal to and zero otherwise.
is an indicator function which outputs one if its input is larger than or equal to and zero otherwise.
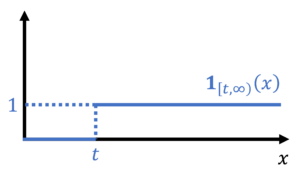
As promised, the probability is larger than is the expectation of :
(11) ![\begin{equation*} \mathbb{P}\{X \ge t \} = \mathbb{E}[\mathbf{1}_{[t,\infty)}(X)]. \end{equation*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-070609e7e86c3846db2eec810355d5f4_l3.png "Rendered by QuickLaTeX.com")
We can now obtain bounds on the probability that  by bounding its corresponding indicator function. In particular, we have the inequality
by bounding its corresponding indicator function. In particular, we have the inequality
(12) 
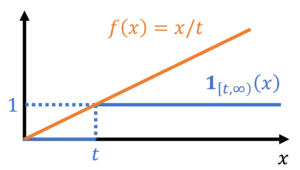
Since is nonnegative, combining equations (11) and (12) gives Markov’s inequality:
![\begin{equation*} \mathbb{P}\{ X \ge t \} = \mathbb{E}[\mathbf{1}_{[t,\infty)}(X)] \le \mathbb{E} \left[ \frac{X}{t} \right] = \frac{\mathbb{E} X}{t}. \end{equation*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-49a753eda4e591b364f5d4f3e24a0b9b_l3.png "Rendered by QuickLaTeX.com")
Chebyshev’s Inequality
Before we get to Chebyshev’s inequality proper, let’s think about how we can push Markov’s inequality further. Suppose we find a bound on the indicator function of the form
(13) 
A bound of this form immediately to bounds on  by (11). To obtain sharp and useful bounds on
by (11). To obtain sharp and useful bounds on  we seek bounding functions
we seek bounding functions  in (13) with three properties:
in (13) with three properties:
- For
 ,
,  should be close to zero,
should be close to zero, - For
 , should be close to one, and
, should be close to one, and - We need
 to be easily computable or boundable.
to be easily computable or boundable.
These three objectives are in tension with each other. To meet criterion 3, we must restrict our attention to pedestrian functions such as powers  or exponentials
or exponentials  for which we have hopes of computing or bounding for random variables we encounter in practical applications. But these candidate functions have the undesirable property that making the function smaller on
for which we have hopes of computing or bounding for random variables we encounter in practical applications. But these candidate functions have the undesirable property that making the function smaller on  (by increasing
(by increasing  ) to meet point 1 makes the function larger on
) to meet point 1 makes the function larger on  , detracting from our ability to achieve point 2. We shall eventually come up with a best-possible resolution to this dilemma by formulating this as an optimization problem to determine the best choice of the parameter
, detracting from our ability to achieve point 2. We shall eventually come up with a best-possible resolution to this dilemma by formulating this as an optimization problem to determine the best choice of the parameter  to obtain the best possible candidate function of the given form.
to obtain the best possible candidate function of the given form.
Before we get ahead of ourselves, let us use a specific choice for different than we used to prove Markov’s inequality. We readily verify that  satisfies the bound (13), and thus by (12),
satisfies the bound (13), and thus by (12),
(14) 
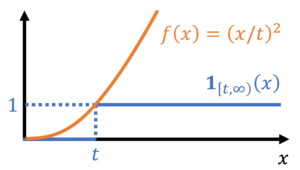
This inequality holds for any nonnegative random variable . In particular, now consider a random variable which we do not assume to be nonnegative. Then ‘s deviation from its expectation,  , is a nonnegative random variable. Thus applying (14) gives
, is a nonnegative random variable. Thus applying (14) gives

We have derived Chebyshev’s inequality! Alternatively, one can derive Chebyshev’s inequality by noting that  if, and only if,
if, and only if,  . Therefore, by Markov’s inequality,
. Therefore, by Markov’s inequality,

The Laplace Transform Method
We shall now realize the plan outlined earlier where we shall choose an optimal bounding function from the family of exponential functions  , where is a parameter which we shall optimize over. This method shall allow us to derive exponential concentration inequalities like Hoeffding’s and Bernstein’s. Note that the exponential function bounds the indicator function for all real numbers , so we shall no longer require the random variable to be nonnegative. Therefore, by (11),
, where is a parameter which we shall optimize over. This method shall allow us to derive exponential concentration inequalities like Hoeffding’s and Bernstein’s. Note that the exponential function bounds the indicator function for all real numbers , so we shall no longer require the random variable to be nonnegative. Therefore, by (11),
(15) 
The functions

are known as the moment generating function and cumulant generating function of the random variable .10These functions are so-named because they are the (exponential) generating functions of the (polynomial) moments  ,
,  , and the cumulants of . With these notations, (15) can be written
, and the cumulants of . With these notations, (15) can be written
(16) 
The moment generating function coincides with the Laplace transform  up to the sign of the parameter , so one name for this approach to deriving concentration inequalities is the Laplace transform method. (This method is also known as the Cramér–Chernoff method.)
up to the sign of the parameter , so one name for this approach to deriving concentration inequalities is the Laplace transform method. (This method is also known as the Cramér–Chernoff method.)
The cumulant generating function has an important property for deriving concentration inequalities for sums or averages of independent random variables: If are independent random variables, than the cumulant generating function is additive:11For proof, we compute  . Taking logarithms proves the additivity.
. Taking logarithms proves the additivity.
(17) 
Proving Hoeffding’s Inequality
For us to use the Laplace transform method, we need to either compute or bound the cumulant generating function. Since we are interested in general concentration inequalities which hold under minimal assumptions such as boundedness, we opt for the latter. Suppose  and consider the cumulant generating function of
and consider the cumulant generating function of  . Then one can show the cumulant generating function bound12The bound (18) is somewhat tricky to establish, but we can establish the same result with a larger constant than
. Then one can show the cumulant generating function bound12The bound (18) is somewhat tricky to establish, but we can establish the same result with a larger constant than  . We have
. We have  . Since the function
. Since the function  is convex, we have the bound
is convex, we have the bound  . Taking expectations, we have
. Taking expectations, we have  . One can show by comparing Taylor series that
. One can show by comparing Taylor series that  . Therefore, we have
. Therefore, we have  .
.
(18) 
Using the additivity of the cumulant generating function (17), we obtain the bound

Plugging this into the probability bound (16), we obtain the concentration bound
(19) 
We want to obtain the smallest possible upper bound on this probability, so it behooves us to pick the value of which makes the right-hand side of this inequality as small as possible. To do this, we differentiate the contents of the exponential and set to zero, obtaining

Plugging this value for into the bound (19) gives A bound for being larger than  :
:
(20) 
To get the bound on being smaller than  , we can apply a small trick. If we apply (20) to the summands
, we can apply a small trick. If we apply (20) to the summands  instead of , we obtain the bounds
instead of , we obtain the bounds
(21) 
We can now combine the upper tail bound (19) with the lower tail bound (21) to obtain a “symmetric” bound on the probability that  . The means of doing often this goes by the fancy name union bound, but the idea is very simple:
. The means of doing often this goes by the fancy name union bound, but the idea is very simple:

Thus, applying this union bound idea with the upper and lower tail bounds (20) and (21), we obtain Hoeffding’s inequality, exactly as it appeared above as (8):

Voilà! Hoeffding’s inequality has been proven! Bernstein’s inequality is proven essentially the same way except that, instead of (17), we have the cumulant generating function bound

for a random variable  with mean zero and satisfying the bound
with mean zero and satisfying the bound  .
.
Upshot: Randomness can be a very effective tool for solving computational problems, even those which seemingly no connection to probability like triangle counting. Concentration inequalities are a powerful tool for assessing how many samples are needed for an algorithm based on random sampling to work. Some of the most useful concentration inequalities are exponential concentration inequalities like Hoeffding and Bernstein, which show that an average of bounded random quantities are close to their average except with exponentially small probability.
i think you might have the direction of the inequality wrong in equation 3
Hm… seems right to me? https://en.wikipedia.org/wiki/Markov%27s_inequality#Statement