I’m excited to share that my paper Kernel quadrature with randomly pivoted Cholesky, joint with Elvira Moreno, has been accepted to NeurIPS 2023 as a spotlight.
Today, I want to share with you a little about the kernel quadrature problem. To avoid this post getting too long, I’m going to write this post assuming familiarity with the concepts of reproducing kernel Hilbert spaces and Gaussian processes.
Integration and Quadrature
Integration is one of the most widely used operations in mathematics and its applications. As such, it is a basic problem of wide interest to develop numerical methods for evaluating integrals.
In this post, we will consider a quite general integration problem. Let  be a domain and let
be a domain and let  be a (finite Borel) measure on
be a (finite Borel) measure on  . We consider the task of evaluating
. We consider the task of evaluating
![\[I[f] = \int_\Omega f(x) g(x) \, \mathrm{d}\mu(x).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4767401252e7558c87b5a518f3609468_l3.png "Rendered by QuickLaTeX.com")
 , , and are fixed, but we may want to evaluate this same integral
, , and are fixed, but we may want to evaluate this same integral ![I[f]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-603f22dedcf932b6f47e37160c09afd8_l3.png "Rendered by QuickLaTeX.com") for multiple different functions
for multiple different functions  .
.
To evaluate, we will design a quadrature approximation to the integral :
![\[\hat{I}_{w,s}[f] = \sum_{i=1}^n w_i f(s_i) \approx I[f].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4bb6a83827b630719dd50338a790b9c6_l3.png "Rendered by QuickLaTeX.com")
 and points
and points  such that the approximation
such that the approximation ![\hat{I}_{w,s}[f] \approx I[f]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-61580a8cc2043483ce9c1ab09e3ea85e_l3.png "Rendered by QuickLaTeX.com") is accurate.
is accurate.
Smoothness and Reproducing Kernel Hilbert Spaces
As is frequently the case in computational mathematics, the accuracy we can expect for this integration problem depends on the smoothness of the integrand . The more smooth is, the more accurately we can expect to compute for a given budget of computational effort.
In this post, will measure smoothness using the reproducing kernel Hilbert space (RKHS) formalism. Let  be an RKHS with norm
be an RKHS with norm  . We can interpret the norm as assigning a roughness
. We can interpret the norm as assigning a roughness  to each function . If is large, then is rough; if is small, then is smooth.
to each function . If is large, then is rough; if is small, then is smooth.
Associated to the RKHS is the titular reproducing kernel  . The kernel is a bivariate function
. The kernel is a bivariate function  . It is related to the RKHS inner product
. It is related to the RKHS inner product  by the reproducing property
by the reproducing property
![\[f(x)=\langle f, k(x,\cdot)\rangle \quad \text{for every }f\in\mathcal{H},x\in\Omega.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-276db3513a1ea34da49f342ad7f4a7ea_l3.png "Rendered by QuickLaTeX.com")
 represents the univariate function obtained by setting the first input of to be
represents the univariate function obtained by setting the first input of to be  .
.
The Ideal Weights
To design a quadrature rule, we have to set the nodes and weights  . Let’s first assume that the nodes
. Let’s first assume that the nodes  are fixed, and talk about how to pick the weights
are fixed, and talk about how to pick the weights  .
.
There’s one choice of weights  that we’ll called the ideal weights. There (at least) are five equivalent ways of characterizing the ideal weights. We’ll present all of them. As an exercise, you can try and convince yourself that these characterizations are equivalent, giving rise to the same weights.
that we’ll called the ideal weights. There (at least) are five equivalent ways of characterizing the ideal weights. We’ll present all of them. As an exercise, you can try and convince yourself that these characterizations are equivalent, giving rise to the same weights.
Interpretation 1: Exactness
A standard way of designing quadrature rules is to make them exact (i.e., error-free) for some class of functions. For instance, many classical quadrature rules are exact for polynomials of degree up to  .
.
For kernel quadrature, it makes sense to design the quadrature rule to be exact for the kernel function at the selected nodes. That is, we require
![\[\hat{I}_{w_\star,s}[k(s_i,\cdot)]=I[k(s_i,\cdot)] \quad \text{for } i=1,2,\ldots,n.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-52bf51e5f4ddb42195d5896ff71ebe02_l3.png "Rendered by QuickLaTeX.com")
 linear equations for the unknowns
linear equations for the unknowns  :
: ![\[\sum_{j=1}^n k(s_i,s_j)w^\star_j = \int_\Omega k(s_i,x) g(x)\,\mathrm{d}\mu(x) \quad \text{for }i=1,2,\ldots,n.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1a5ca36966f56dae9d994e208f9ef036_l3.png "Rendered by QuickLaTeX.com")
 is the ideal weights.
is the ideal weights.
Interpretation 2: Interpolate and Integrate
Here’s another very classical way of designing a quadrature rule. First, interpolate the function values  at the nodes, obtaining an interpolant
at the nodes, obtaining an interpolant  . Then, obtain an approximation to the integral by integrating the interpolant:
. Then, obtain an approximation to the integral by integrating the interpolant:
![\[\hat{I}_{w^\star,s}[f] \coloneqq \int_\Omega \hat{f}(x) g(x) \, \mathrm{d}\mu(x).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0c68060fdf085f41d9cbdd9cc5c16e31_l3.png "Rendered by QuickLaTeX.com")
In our context, the appropriate interpolation method is kernel interpolation.1Kernel interpolation is also called Gaussian process regression or kriging though (confusingly) these terms can also refer to slightly different methods. It is the regularization-free limit of kernel ridge regression. The kernel interpolant is defined to be the minimum-norm function
that interpolates the data: ![\[\hat{f} = \argmin \{ \norm{h} : h(s_i) = f(s_i) \text{ for } i=1,\ldots,n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5619a986180c554d2a079e5156a97571_l3.png "Rendered by QuickLaTeX.com")
is the unique function of the form ![\[\hat{f} = \sum_{i=1}^n \alpha_i k(\cdot,s_i)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0abcded0eda92deac99b904817afdf5b_l3.png "Rendered by QuickLaTeX.com")
on the points  .With a little algebra, you can show that the integral of is
.With a little algebra, you can show that the integral of is ![\[I[\hat{f}] = \sum_{i=1}^n w^\star_i f(s_i),\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f0da23bc7dc97894b0a6702b6bf6ddfb_l3.png "Rendered by QuickLaTeX.com")
are the ideal weights.
Interpretation 3: Minimizing the Worst-Case Error
Define the worst-case error of weights and nodes to be
![\[\operatorname{Err}(w,s)=\sup_{\norm{f}\le 1}\left| I[f] - \hat{I}_{w,s}[f]\right|.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6e46307dc4cdac54a3ab010b36ed7858_l3.png "Rendered by QuickLaTeX.com")
 is the highest possible quadrature error for a function
is the highest possible quadrature error for a function  of norm at most 1.
of norm at most 1.
Having defined the worst-case error, the ideal weights are precisely the weights that minimize this quantity
![\[w^\star=\operatorname*{argmin}_{w\in\real^n}\operatorname{Err}(w,s).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-06e68886b8279d9d592cae3775d4295f_l3.png "Rendered by QuickLaTeX.com")
Interpretation 4: Minimizing the Mean-Square Error
The next two interpretations of the ideal weights will adopt a probabilistic framing. A Gaussian process is a random function such that ’s values at any collection of points are (jointly) Gaussian random variables. We write  for a mean-zero Gaussian process with covariance function :
for a mean-zero Gaussian process with covariance function :
![\[\Cov(f(x),f(y))=k(x,y)\quad \text{for every } x,y\in\Omega.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-19fea8ea8406c891c0d6bab2166dc4a4_l3.png "Rendered by QuickLaTeX.com")
Define the mean-square quadrature error of weights
and nodes to be ![\[\operatorname{MSE}(w,s)\coloneqq \expect_{f\sim\operatorname{GP}(0,k)} \left( I[f] - \hat{I}_{w,s}[f] \right)^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4741e0bcba7276b0a3a9266cd61b54c0_l3.png "Rendered by QuickLaTeX.com")
drawn from a Gaussian process with covariance function .
Pleasantly, the mean-square error is equal ro the square of the worst-case error
![\[\operatorname{MSE}(w,s)=\operatorname{Err}(w,s)^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-dc387f1211b9e5a070f2778a8205c022_l3.png "Rendered by QuickLaTeX.com")
![\[w^\star=\operatorname*{argmin}_{w\in\real^n}\operatorname{MSE}(w,s).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-32506adbc7176da52a920dbf4c373149_l3.png "Rendered by QuickLaTeX.com")
Interpretation 5: Conditional Expectation
For our last interpretation, again consider a Gaussian process  . The integral of this random function
. The integral of this random function ![I[h]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e47eba0764d69669e85367cf245d71d3_l3.png "Rendered by QuickLaTeX.com") is a random variable. To numerically integrate a function , compute the expectation of conditional on
is a random variable. To numerically integrate a function , compute the expectation of conditional on  agreeing with at the quadrature nodes:
agreeing with at the quadrature nodes:
![\[\hat{I}_{w^\star,s}[f]\coloneqq \expect_{h\sim\operatorname{GP}(0,k)}[I[h] \mid h(s_i)=f(s_i) \text{ for } i=1,\ldots,n].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ce1156fb9da612607ae0158770a34645_l3.png "Rendered by QuickLaTeX.com")
Conclusion
We’ve just seen five sensible ways of defining the ideal weights for quadrature in a general reproducing kernel Hilbert space. Remarkably, all five lead to exactly the same choice of weights. To me, these five equivalent characterizations give me more confidence that the ideal weights really are the “right” or “natural” choice for kernel quadrature.
That said, there are other reasonable requirements that we might want to impose on the weights. For instance, if is a probability measure and  , it is reasonable to add an additional constraint that the weights lie in the probability simplex
, it is reasonable to add an additional constraint that the weights lie in the probability simplex
![\[w\in\Delta\coloneqq \left\{ p\in\real^n_+ : \sum_{i=1}^n p_i = 1\right\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-55c593b2593abc9ea8c18d4f8edbccd3_l3.png "Rendered by QuickLaTeX.com")
against a discrete probability measure  ; thus, in effect, quadrature amounts to approximating one probability measure by another
; thus, in effect, quadrature amounts to approximating one probability measure by another  . Additional constraints such as these can easily be imposed when using the optimization characterizations 3 and 4 of the ideal weights. See this paper for details.
. Additional constraints such as these can easily be imposed when using the optimization characterizations 3 and 4 of the ideal weights. See this paper for details.
What About the Nodes?
We’ve spent a lot of time talking about how to pick the quadrature weights, but how should we pick the nodes  ? To pick the nodes, it seems sensible to try and minimize the worst-case error
? To pick the nodes, it seems sensible to try and minimize the worst-case error  with the ideal weights . For this purpose, we can use the following formula:
with the ideal weights . For this purpose, we can use the following formula:
![\[\operatorname{Err}(w^\star,s) = \norm{\int_\Omega (k(\cdot,x) - \hat{k}_s(\cdot,x)) g(x) \, \mathrm{d}\mu(x)}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f66a0cdfc8a943a944dad0fed98dbad9_l3.png "Rendered by QuickLaTeX.com")
 is the Nyström approximation to the kernel induced by the nodes , defined to be
is the Nyström approximation to the kernel induced by the nodes , defined to be ![\[\hat{k}_s(x,y) = k(x,s) k(s,s)^{-1} k(s,y).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9c55d13be5a7cdb27139303cb08ec19f_l3.png "Rendered by QuickLaTeX.com")
 for the kernel matrix with
for the kernel matrix with  entry
entry  and
and  and
and  for the row and column vectors with
for the row and column vectors with  th entry
th entry  and
and  .
.
I find the appearance of the Nyström approximation in this context to be surprising and delightful. Previously on this blog, we’ve seen (column) Nyström approximation in the context of matrix low-rank approximation. Now, a continuum analog of the matrix Nyström approximation has appeared in the error formula for numerical integration.
The appearance of the Nyström approximation in the kernel quadrature error also suggests a strategy for picking the nodes.
Node selection strategy. We should pick the nodes
as accurate as possible.
The closer is to , the smaller the function  is and, thus, the smaller the error
is and, thus, the smaller the error
Indeed, all three of these algorithms—randomly pivoted Cholesky, ridge leverage score sampling, and determinantal point process sampling—have been studied for kernel quadrature. The first of these algorithms, randomly pivoted Cholesky, is the subject of our paper. We show that this simple, adaptive sampling method produces excellent nodes for kernel quadrature. Intuitively, randomly pivoted Cholesky is effective because it is repulsive: After having picked nodes  , it has a high probability of placing the next node
, it has a high probability of placing the next node  far from the previously selected nodes.
far from the previously selected nodes.
The following image shows 20 nodes selected by randomly pivoted Cholesky in a crescent-shaped region. The cyan–pink shading denotes the probability distribution for picking the next node. We see that the center of the crescent does not have any nodes, and thus is most likely to receive a node during the next round of sampling.
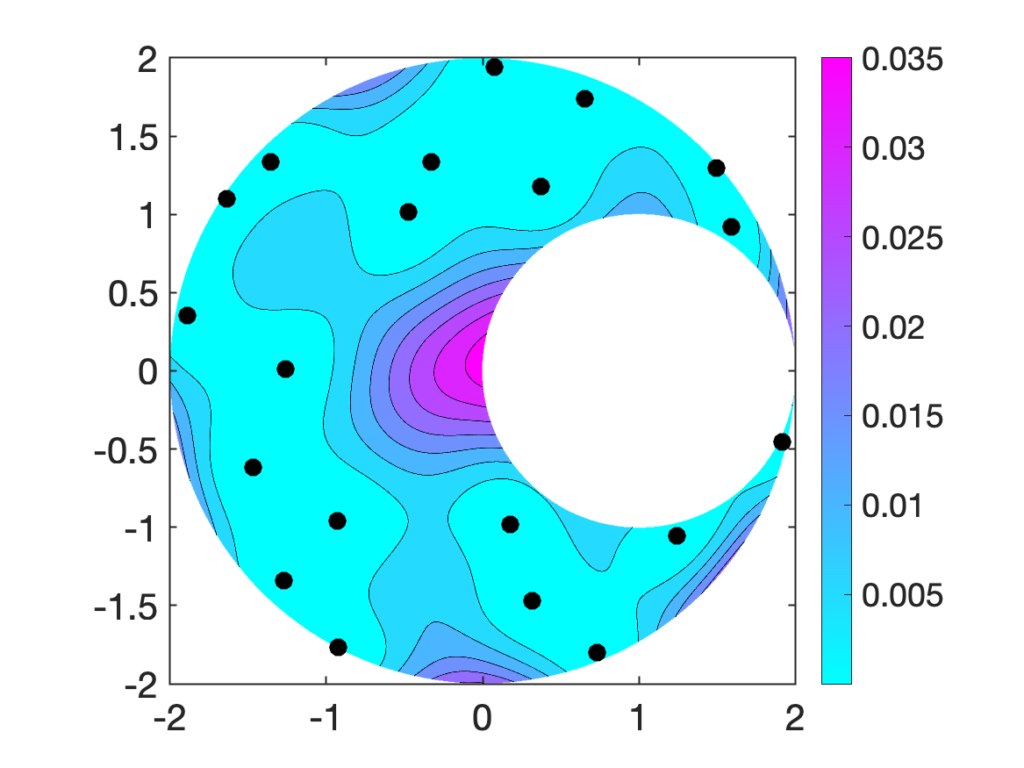
In our paper, we demonstrate—empirically and theoretically—that randomly pivoted Cholesky produces excellent nodes for quadrature. We also discuss efficient rejection sampling algorithms for sampling nodes with the randomly pivoted Cholesky distribution. Check out the paper for details!
One thought on “Five Interpretations of Kernel Quadrature”