I am delighted to share that my paper Randomized Kaczmarz with tail averaging, joint with Gil Goldshlager and Rob Webber, has been posted to arXiv. This paper in particular really benefited from a lot of feedback from discussions with friends, colleagues, and experts, and I’d like to thank everyone who gave us feedback on this paper.
In this post, I want to provide a different and complementary perspective on the results of this paper, and provide some more elementary results and derivations that didn’t make the main paper.
The randomized Kaczmarz (RK) method is an iterative method for solving systems of linear equations  , whose dimensions will be
, whose dimensions will be  throughout this post. Beginning from a trivial initial solution
throughout this post. Beginning from a trivial initial solution  , the method works by repeating the following two steps for
, the method works by repeating the following two steps for  :
:
- Randomly sample a row
 of
of  with probability
with probability
Throughout this post,![\[\prob\{ i_t = j\} = \frac{\norm{a_j}^2}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-81c1ff56386b62fc105c714e21f13f5c_l3.png "Rendered by QuickLaTeX.com")
 denotes the
denotes the  th row of .
th row of . - Orthogonally project
 onto the solution space of the equation
onto the solution space of the equation  , obtaining
, obtaining  .
.
The main selling point of RK is that it only interacts with the matrix through row accesses, which makes the method ideal for very large problems where only a few rows of can fit in memory at a time.
When applied to a consistent system of linear equations (i.e., a system possessing a solution  satisfying
satisfying  ), RK is geometrically convergent:
), RK is geometrically convergent:
(1) ![\[\expect\left[ \norm{x_t - x_\star}^2 \right] \le (1 - \kappa_{\rm dem}^{-2})^t \norm{x_\star}^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-02d23e54a2a02cf261b7ab8afc0f4b90_l3.png "Rendered by QuickLaTeX.com")
(2) ![\[\kappa_{\rm dem} = \frac{\norm{A}_{\rm F}}{\sigma_{\rm min}(A)} = \sqrt{\sum_i \left(\frac{\sigma_i(A)}{\sigma_{\rm min}(A)}\right)^2} \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0a01bce740f28deced2d1a8b4e6e1002_l3.png "Rendered by QuickLaTeX.com")
 are the singular values of .1Personally, I find it convenient to write the Demmel condition number as
are the singular values of .1Personally, I find it convenient to write the Demmel condition number as  , where
, where  is the ordinary condition number and
is the ordinary condition number and  is the stable rank of the matrix . The stable rank is a smooth proxy for the rank or dimensionality of the matrix . Using this parameter, the rate of convergence is roughly
is the stable rank of the matrix . The stable rank is a smooth proxy for the rank or dimensionality of the matrix . Using this parameter, the rate of convergence is roughly  , so it takes roughly
, so it takes roughly  row accesses to reduce the error by a constant factor. Compare this to gradient descent, which requires
row accesses to reduce the error by a constant factor. Compare this to gradient descent, which requires  row accesses. However, for inconsistent problems, RK does not converge at all. Indeed, since each step of RK updates the iterate such that an equation hold exactly and no solution satisfies all the equations simultaneously, the RK iterates continue to stochastically fluctuate no matter how long the algorithm is run.
row accesses. However, for inconsistent problems, RK does not converge at all. Indeed, since each step of RK updates the iterate such that an equation hold exactly and no solution satisfies all the equations simultaneously, the RK iterates continue to stochastically fluctuate no matter how long the algorithm is run.
However, while the RK iterates continue to randomly fluctuate when applied to an inconsistent system, their expected value does converge. In fact, it converges to the least-squares solution2If the matrix is rank-deficient, then we define to be the minimum-norm least-squares solution  , which can be expressed using the Moore–Penrose pseudoinverse
, which can be expressed using the Moore–Penrose pseudoinverse  . to the system, defined as
. to the system, defined as
![\[x_\star = \operatorname{argmin}_{x \in \real^d} \norm{b - Ax}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9052e54b28c6061d7a56c05ca254f154_l3.png "Rendered by QuickLaTeX.com")
as estimators to the least-squares solution converge to zero, and the rate of convergence is geometric. Specifically, we have the following theorem:
Theorem 1 (Exponentially Decreasing Bias): The RK iterates
(3)
![\[\norm{\mathbb{E}[x_t] - x_\star}^2 \le (1 - \kappa_{\rm dem}^{-2})^{2t} \norm{x_\star}^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a54409c570b03a8e2e3607c316004f4d_l3.png "Rendered by QuickLaTeX.com")
Observe that the rate of convergence (3) for the bias is twice as fast as the rate of convergence for the error in (1). This factor of two was previously observed by Gower and Richtarik in the context of consistent systems of equations.
The proof of Theorem 1 is straightforward, and we will present it at the bottom of this post. First, we will discuss a couple of implications. First, we develop convergent versions of the RK algorithm using tail averaging. Second, we explore what happens when we implement RK with different sampling probabilities  .
.
Tail Averaging
It may seem like Theorem 1 has little implication for practice. After all, just because the expected value of becomes closer and closer to , it need not be the case that is close to  . However, we can improve the quality of the approximate solution by averaging.
. However, we can improve the quality of the approximate solution by averaging.
There are multiple different possible ways we could use averaging. A first idea would be to run RK multiple times, obtaining multiple solutions  which could then be averaged together. This approach is inefficient as each solution
which could then be averaged together. This approach is inefficient as each solution  is computed separately.
is computed separately.
A better strategy is tail averaging. Fix a burn-in time  , chosen so that the bias
, chosen so that the bias ![\norm{\expect[x_{t_{\rm b}}] - x_\star}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-03b1f60b09d6e66904287aa5e6cd6009_l3.png "Rendered by QuickLaTeX.com") is small. For each
is small. For each  ,
,  is a nearly unbiased approximation to the least-squares solution . To reduce variance, we can average these estimators together
is a nearly unbiased approximation to the least-squares solution . To reduce variance, we can average these estimators together
![\[\overline{x}_t = \frac{x_{t_{\rm b} +1} + x_{t_{\rm b}+2} + \cdots + x_t}{t-t_{\rm b}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-53375d695acfc74d6ea111d3a1b32d29_l3.png "Rendered by QuickLaTeX.com")
 is the tail-averaged randomized Kaczmarz (TARK) estimator. By Theorem 1, we know the TARK estimator has an exponentially small bias:
is the tail-averaged randomized Kaczmarz (TARK) estimator. By Theorem 1, we know the TARK estimator has an exponentially small bias: ![\[\norm{\expect[\overline{x}_t] - x_\star} \le (1 - \kappa_{\rm dem}^{-2})^{2(t_{\rm b}+1)} \norm{x_\star}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-89806db87c210bfdd9cbd0e800d65e85_l3.png "Rendered by QuickLaTeX.com")
![\[\expect [\norm{\overline{x}_t - x_\star}^2] \le (1-\kappa_{\rm dem}^{-2})^{t_{\rm b}+1} \norm{x_\star}^2 + \frac{2\kappa_{\rm dem}^4}{t-t_{\rm b}} \frac{\norm{b-Ax_\star}^2}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d30cb224e4284f0840a46a9757196abf_l3.png "Rendered by QuickLaTeX.com")
and occurs at an algebraic, Monte Carlo, rate in the final time  . While the Monte Carlo rate of convergence may be unappealing, it is known that this rate of convergence is optimal for any method that accesses row–entry pairs
. While the Monte Carlo rate of convergence may be unappealing, it is known that this rate of convergence is optimal for any method that accesses row–entry pairs  ; see our paper for a new derivation of this fact.
; see our paper for a new derivation of this fact.
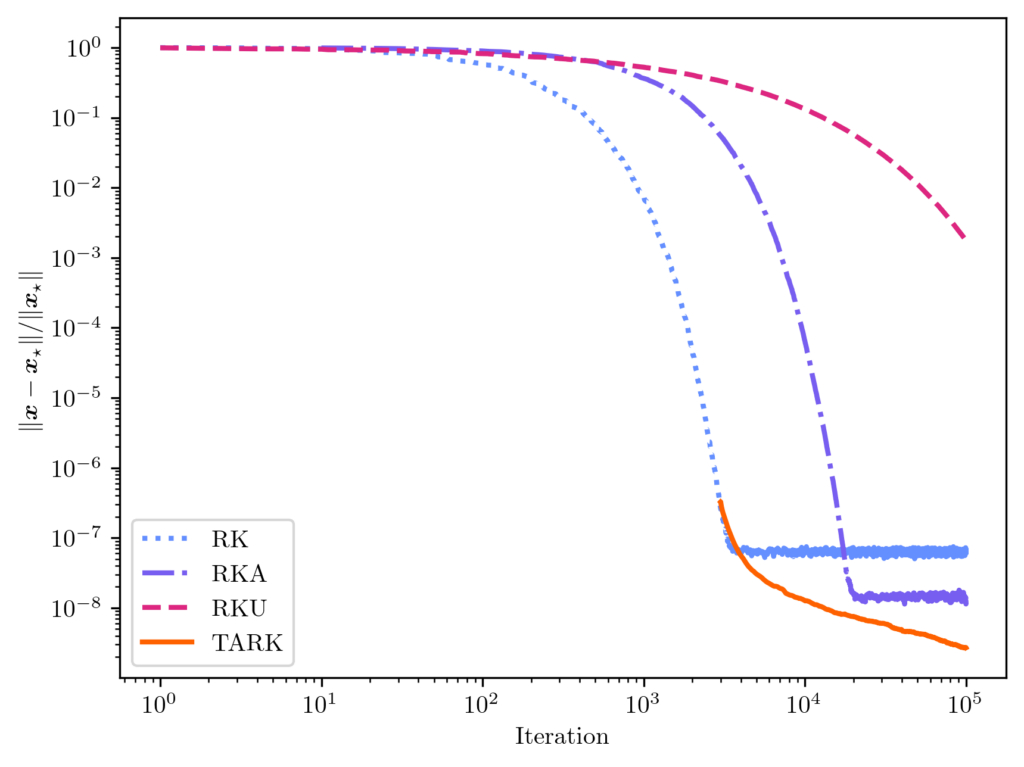
Tail averaging can be an effective method for squeezing a bit more accuracy out of the RK method for least-squares problems. The figure below shows the error of different RK methods applied to a random least-squares problem, including plain RK, RK with thread averaging (RKA), and RK with underrelaxation (RKU);3The number of threads is set to 10, and the underrelaxation parameter is  . We found this underrelaxation parameter to lead to a smaller error than the other popular underrelaxation parameter schedule
. We found this underrelaxation parameter to lead to a smaller error than the other popular underrelaxation parameter schedule  . see the paper’s Github for code. For this problem, tail-averaged randomized Kaczmarz achieves the lowest error of all of the methods considered, being 6× smaller than RKA, 22× smaller than RK, and 10⁶× smaller than RKU.
. see the paper’s Github for code. For this problem, tail-averaged randomized Kaczmarz achieves the lowest error of all of the methods considered, being 6× smaller than RKA, 22× smaller than RK, and 10⁶× smaller than RKU.
What Least-Squares Solution Are We Converging To?
A second implication of Theorem 1 comes from reanalyzing the RK algorithm if we change the sampling probabilities. Recall that the standard RK algorithm draws random row indices using squared row norm sampling:
![\[\prob \{ i_t = j \} = \frac{\norm{a_j}^2}{\norm{A}_{\rm F}^2} \eqqcolon p^{\rm RK}_j.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-072dd81a7e854128bf0258a1836003de_l3.png "Rendered by QuickLaTeX.com")
as  .
.
Using the standard RK sampling procedure can sometimes be difficult. To implement it directly, we must make a full pass through the matrix to compute the sampling probabilities.4If we have an upper bound on the squared row norms, there is an alternative procedure based on rejection sampling that avoids this precomputation step. It can be much more convenient to sample rows uniformly at random  .
.
To do the following analysis in generality, consider performing RK using general sampling probabilities  :
:
![\[\prob \{i_t = j\} = p_j.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-95b2f6411ef8d9b8c9b5b61acf6bc928_l3.png "Rendered by QuickLaTeX.com")
Define a diagonal matrix
![\[D \coloneqq \diag\left( \sqrt{\frac{p_j}{p_j^{\rm RK}}} : j =1,\ldots,n\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bc930770f7b4e20afffe903a4ab372ba_l3.png "Rendered by QuickLaTeX.com")
 is equivalent to the standard RK algorithm run on the diagonally reweighted least-squares problem
is equivalent to the standard RK algorithm run on the diagonally reweighted least-squares problem ![\[x_{\rm weighted} = \argmin_{x\in\real^d} \norm{Db-(DA)x}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3e1818420a485f35a47361344560d2b1_l3.png "Rendered by QuickLaTeX.com")
will converge to the weighted least-squares problem  rather than the original least-squares solution .
rather than the original least-squares solution .
I find this very interesting. In the standard RK method, the squared row norm sampling distribution is chosen to ensure rapid convergence of the RK iterates to the solution of a consistent system of linear equations. However, for a consistent system, the RK method will always converge to the same solution no matter what row sampling strategy is chosen (as long as every non-zero row has a positive probability of being picked). In the least-squares context, however, the conclusion is very different: the choice of row sampling distribution not only affects the rate of convergence, but also which solution is being converged to!
As the plot below demonstrates, the original least-squares solution and re-weighted least-squares solution can sometimes be quite different from each other. This plot shows the results of fitting a function with many kinks (show as a black dashed curve) using a polynomial function  [mfn}Note that, for this experiment we represent the polynomial
[mfn}Note that, for this experiment we represent the polynomial  using its monomial coefficients
using its monomial coefficients  , which has issues with numerical stability. It’s better to use a representation using Chebyshev polynomials. We use this example only to illustrate the difference between the weighted and original least-squares solution.[/mfn} at
, which has issues with numerical stability. It’s better to use a representation using Chebyshev polynomials. We use this example only to illustrate the difference between the weighted and original least-squares solution.[/mfn} at  equispaced points. We compare the unweighted least-squares solution (orange solid curve) to the weighted least-squares solution using uniform RK weights
equispaced points. We compare the unweighted least-squares solution (orange solid curve) to the weighted least-squares solution using uniform RK weights  (blue dash-dotted curve). These two curves differ meaningfully, with the weighted least-squares solution having higher error at the ends of the interval but more accuracy in the middle. These differences can be explained looking at the weights (diagonal entries of
(blue dash-dotted curve). These two curves differ meaningfully, with the weighted least-squares solution having higher error at the ends of the interval but more accuracy in the middle. These differences can be explained looking at the weights (diagonal entries of  , grey dotted curve), which are lower at the ends of the interval than in the center.
, grey dotted curve), which are lower at the ends of the interval than in the center.
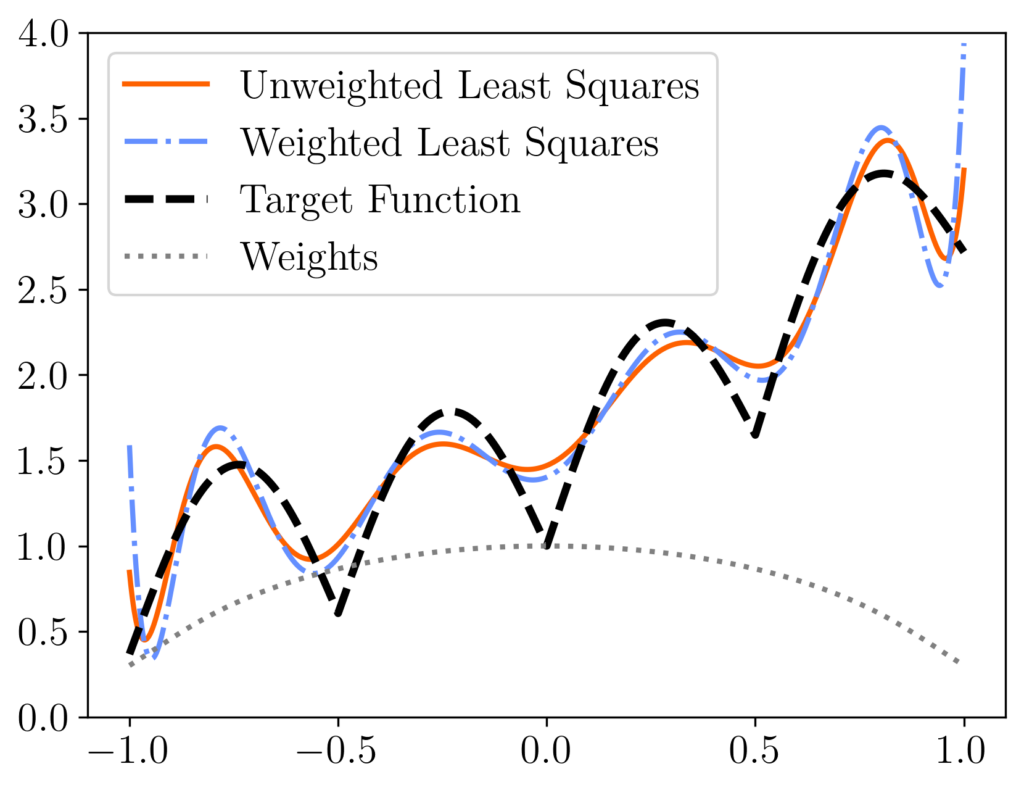
Does this diagonal rescaling issue matter? Sometimes not. In many applications, the weighted and un-weighted least squares solutions will both be fine. Indeed, in the above example, neither the weighted nor un-weighted solutions are the “right” one; the weighted solution is more accurate in the interior of the domain and less accurate at the boundary. However, sometimes getting the true least-squares solution matters, or the amount of reweighting done by uniform sampling is too aggressive for a problem. In these cases, using the classical RK sampling probabilities may be necessary. Fortunately, rejection sampling can often be used to perform squared row norm sampling; see this blog post of mine for details.
Proof of Theorem 1
Let us now prove Theorem 1, the asymptotic unbiasedness of randomized Kaczmarz. We will assume throughout that is full-rank; the rank-deficient case is similar but requires a bit more care.
Begin by rewriting the update rule in the following way
![\[x_{t+1} = \left( I - \frac{a_{i_t}^{\vphantom{\top}}a_{i_t}^\top}{\norm{a_{i_t}}^2} \right)x_t + \frac{b_{i_t}a_{i_t}}{\norm{a_{i_t}}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cccfb54762bb990499c96331e7019309_l3.png "Rendered by QuickLaTeX.com")
 denote the average over the random index , we compute
denote the average over the random index , we compute
![\begin{align*}\expect_{i_t}[x_{t+1}] &= \sum_{j=1}^n \left[\left( I - \frac{a_j^{\vphantom{\top}} a_j^\top}{\norm{a_j}^2} \right)x_t + \frac{b_ja_j}{\norm{a_j}^2}\right] \prob\{i_t=j\}\\ &=\sum_{j=1}^n \left[\left( \frac{\norm{a_j}^2}{\norm{A}_{\rm F}^2}I - \frac{a_j^{\vphantom{\top}} a_j^\top}{\norm{A}_{\rm F}^2} \right)x_t + \frac{b_ja_j}{\norm{A}_{\rm F}^2}\right].\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0a7f7b3bfad51b7094348db94d2d4254_l3.png "Rendered by QuickLaTeX.com")
We can evaluate the sums  and
and  directly. Therefore, we obtain
directly. Therefore, we obtain
![\[\expect_{i_t}[x_{t+1}] = \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right) x_t + \frac{A^\top b}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-de4ded17daf001dde92c26025e9c14f3_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[x_{t+1}] = \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right) \expect[x_t] + \frac{A^\top b}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-24c5bfe6c1ea70293055deb68a3df117_l3.png "Rendered by QuickLaTeX.com")
 , we obtain
, we obtain (4) ![\[\expect[x_t] = \left[\sum_{i=0}^{t-1} \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i \right]\cdot\frac{A^\top b}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-eb47c96091b1187b53c318589b696693_l3.png "Rendered by QuickLaTeX.com")
The equation (4) expresses the expected RK iterate
![\expect[x_t]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fa98c6708608ae4bf5513cf53e74597c_l3.png "Rendered by QuickLaTeX.com") using a matrix geometric series. Recall that the infinite geometric series with a scalar ratio
using a matrix geometric series. Recall that the infinite geometric series with a scalar ratio  satisfies the formula
satisfies the formula ![\[\sum_{i=0}^\infty y^i = (1-y)^{-1}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2d95246c2816e550018d080c58c60240_l3.png "Rendered by QuickLaTeX.com")
 , we get
, we get ![\[\sum_{i=0}^\infty (1-x)^i = x^{-1}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-726e8fae76877e0ec1f03efab333ec2e_l3.png "Rendered by QuickLaTeX.com")
 . With a little effort, one can check that the same formula
. With a little effort, one can check that the same formula ![\[\sum_{i=0}^\infty (I-X)^i = X^{-1}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1389cddfba9ee14bcbf4293f018c78c9_l3.png "Rendered by QuickLaTeX.com")
 satisfying
satisfying  . These conditions hold for the matrix
. These conditions hold for the matrix  since is full-rank, yielding
since is full-rank, yielding (5) ![\[\left(\frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^{-1} = \sum_{i=0}^\infty \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8d1be156303c168d2de83dbde76e44d6_l3.png "Rendered by QuickLaTeX.com")
(6) ![\[\left(\frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^{-1} = \sum_{i=0}^{t-1} \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i + \sum_{i=t}^\infty \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-08f4b1a705439315fe0fc038e059d01c_l3.png "Rendered by QuickLaTeX.com")
We are at the home stretch. Plugging (6) into (4) and using the normal equations  , we obtain
, we obtain
![\[\expect[x_t] = x_\star - \left[\sum_{i=t}^\infty \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i \right]\cdot\frac{A^\top b}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d973041dba49ba471bbfb6b3d4c2b463_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[x_t] - x_\star = - \left(I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^t \left[\sum_{i=0}^\infty \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i \right]\cdot\frac{A^\top b}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8238e65e7b7df2013504f2a6f71799e6_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[x_t] - x_\star = - \left(I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^t x_\star.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3cbe72663f8ef13c762213b5592bb5d2_l3.png "Rendered by QuickLaTeX.com")
(7) ![\[\norm{\expect[x_t] - x_\star}^2 \le \norm{I - \frac{A^\top A}{\norm{A}_{\rm F}^2}}^{2t} \norm{x}_\star^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e663370119bd02900da0aa4f7b6faf03_l3.png "Rendered by QuickLaTeX.com")
To complete the proof we must evaluate the norm of the matrix  . Let
. Let  be a (thin) singular value decomposition, where
be a (thin) singular value decomposition, where  . Then
. Then
![\[I - \frac{A^\top A}{\norm{A}_{\rm F}^2} = I - V \cdot\frac{\Sigma^2}{\norm{A}_{\rm F}^2} \cdot V^\top = V \left( I - \frac{\Sigma^2}{\norm{A}_{\rm F}^2}\right)V^\top.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-468566feb9b39f9e0dd616b47f324ad5_l3.png "Rendered by QuickLaTeX.com")
 and whose eigenvalues are the diagonal entries of the matrix
and whose eigenvalues are the diagonal entries of the matrix ![\[I - \Sigma^2/\norm{A}_{\rm F}^2 = \diag(1 - \sigma^2_{\rm max}(A)/\norm{A}_{\rm F}^2,\ldots,1-\sigma_{\rm min}^2(A)/\norm{A}_{\rm F}^2).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4bc7dac794d8913157b82fd0df23e41d_l3.png "Rendered by QuickLaTeX.com")
 . We have invoked the definition of the Demmel condition number (2). Therefore, plugging into (7), we obtain
. We have invoked the definition of the Demmel condition number (2). Therefore, plugging into (7), we obtain ![\[\norm{\expect[x_t] - x_\star}^2 \le \left(1-\kappa_{\rm dem}^{-2}\right)^{2t} \norm{x}_\star^2,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7c29ce0386ec23c163afab561f181af1_l3.png "Rendered by QuickLaTeX.com")
One thought on “Randomized Kaczmarz is Asympotically Unbiased for Least Squares”