The purpose of this note is to describe the Gaussian hypercontractivity inequality. As an application, we’ll obtain a weaker version of the Hanson–Wright inequality.
The Noise Operator
We begin our discussion with the following question:
Let
be a function. What happens to
, on average, if we perturb its inputs by a small amount of Gaussian noise?
Let’s be more specific about our noise model. Let  be an input to the function and fix a parameter
be an input to the function and fix a parameter  (think of
(think of  as close to 1). We’ll define the noise corruption of
as close to 1). We’ll define the noise corruption of  to be
to be
(1) ![\[\tilde{x}_\varrho = \varrho \cdot x + \sqrt{1-\varrho^2} \cdot g, \quad \text{where } g\sim \operatorname{Normal}(0,I). \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-041342b8b0a6caeb403940fb8e87dd6a_l3.png "Rendered by QuickLaTeX.com")
Here,  is the standard multivariate Gaussian distribution. In our definition of
is the standard multivariate Gaussian distribution. In our definition of  , we both add Gaussian noise
, we both add Gaussian noise  and shrink the vector by a factor . In particular, we highlight two extreme cases:
and shrink the vector by a factor . In particular, we highlight two extreme cases:
- No noise. If
 , then there is no noise and
, then there is no noise and  .
. - All noise. If
 , then there is all noise and
, then there is all noise and  . The influence of the original vector has been washed away completely.
. The influence of the original vector has been washed away completely.
The noise corruption (1) immediately gives rise to the noise operator1The noise operator is often called the Hermite operator. The noise operator is related to the Ornstein–Uhlenbeck semigroup operator  by a change of variables,
by a change of variables,  .
.  . Let be a function. The noise operator is defined to be:
. Let be a function. The noise operator is defined to be:
(2) ![\[(T_\varrho f)(x) = \expect[f(\tilde{x}_\varrho)] = \expect_{g\sim \operatorname{Normal}(0,I)}[f( \varrho \cdot x + \sqrt{1-\varrho^2}\cdot g)]. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2c0d3910f8c2698ff609526d26364727_l3.png "Rendered by QuickLaTeX.com")
The noise operator computes the average value of when evaluated at the noisy input . Observe that the noise operator maps a function to another function  . Going forward, we will write
. Going forward, we will write  to denote
to denote  .
.
To understand how the noise operator acts on a function , we can write the expectation in the definition (2) as an integral:
![\[T_\varrho f(x) = \int_{\real^d} f(\varrho x + y) \frac{1}{(2\pi (1-\varrho^2))^{d/2}}\e^{-\frac{|y|^2}{2(1-\varrho^2)}} \, \mathrm{d} y.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4ffd4694f0e60bfefcab1cc5e280cea4_l3.png "Rendered by QuickLaTeX.com")
 denotes the (Euclidean) length of
denotes the (Euclidean) length of  . We see that
. We see that  is the convolution of
is the convolution of  with a Gaussian density. Thus, acts to smooth the function .
with a Gaussian density. Thus, acts to smooth the function .
See below for an illustration. The red solid curve is a function , and the blue dashed curve is  .
.
As we decrease from  to
to  , the function is smoothed more and more. When we finally reach , has been smoothed all the way into a constant.
, the function is smoothed more and more. When we finally reach , has been smoothed all the way into a constant.
Random Inputs
The noise operator converts a function to another function . We can evaluate these two functions at a Gaussian random vector  , resulting in two random variables
, resulting in two random variables  and .
and .
We can think of as a modification of the random variable where “a  fraction of the variance of has been averaged out”. We again highlight the two extreme cases:
fraction of the variance of has been averaged out”. We again highlight the two extreme cases:
- No noise. If ,
 . None of the variance of has been averaged out.
. None of the variance of has been averaged out. - All noise. If
 ,
,![T_\varrho f(x) = \expect_{g\sim\operatorname{Normal}(0,I)}[f(g)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7c2c7854379c5ae8a6ceab379242bcc3_l3.png "Rendered by QuickLaTeX.com") is a constant random variable. All of the variance of has been averaged out.
is a constant random variable. All of the variance of has been averaged out.
Just as decreasing smoothes the function until it reaches a constant function at , decreasing makes the random variable more and more “well-behaved” until it becomes a constant random variable at . This “well-behavingness” property of the noise operator is made precise by the Gaussian hypercontractivity theorem.
Moments and Tails
In order to describe the “well-behavingness” properties of the noise operator, we must answer the question:
How can we measure how well-behaved a random variable is?
There are many answers to this question. For this post, we will quantify the well-behavedness of a random variable by using the  norm.2Using norms is a common way of measuring the niceness of a function or random variable in applied math. For instance, we can use Sobolev norms or reproducing kernel Hilbert space norms to measure the smoothness of a function in approximation theory, as I’ve discussed before on this blog.
norm.2Using norms is a common way of measuring the niceness of a function or random variable in applied math. For instance, we can use Sobolev norms or reproducing kernel Hilbert space norms to measure the smoothness of a function in approximation theory, as I’ve discussed before on this blog.
The norm of a ( -valued) random variable
-valued) random variable  is defined to be
is defined to be
(3) ![\[\norm{y}_p \coloneqq \left( \expect[|y|^p] \right)^{1/p}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-35a5fc4a23b6f18a7ae8fdc9a3cefd33_l3.png "Rendered by QuickLaTeX.com")
 th power of the norm
th power of the norm  is sometimes known as the th absolute moment of .
is sometimes known as the th absolute moment of .
The norms of random variables control the tails of a random variable—that is, the probability that a random variable is large in magnitude. A random variables with small tails is typically thought of as a “nice” or “well-behaved” random variable. Random quantities with small tails are usually desirable in applications, as they are more predictable—unlikely to take large values.
The connection between tails and norms can be derived as follows. First, write the tail probability  for
for  using th powers:
using th powers:
![\[\prob \{|y| \ge t\} = \prob\{ |y|^p \ge t^p \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0883f1fd4c80aee10068d2e91c7f49f0_l3.png "Rendered by QuickLaTeX.com")
(4) ![\[\prob \{|y| \ge t\} = \prob \{ |y|^p \ge t^p \} \le \frac{\expect [|y|^p]}{t^p} = \frac{\norm{y}_p^p}{t^p}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3cccec8fa93a5820d606eae22c7d6bf0_l3.png "Rendered by QuickLaTeX.com")
norm (i.e.,  ) has tails that decay at at a rate
) has tails that decay at at a rate  or faster.
or faster.
Gaussian Contractivity
Before we introduce the Gaussian hypercontractivity theorem, let’s establish a weaker property of the noise operator, contractivity.
Proposition 1 (Gaussian contractivity). Choose a noise level
and a power
, and let
![\[\norm{T_\varrho f(x)}_p \le \norm{f(x)}_p.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f1e07630c4ae5d950e1724b1cf8c63f1_l3.png "Rendered by QuickLaTeX.com")
This result shows that the noise operator makes the random variable no less nice than was.
Gaussian contractivity is easy to prove. Begin using the definition of the noise operator (2) and norm (3):
![\[\norm{T_\varrho f(x)}_p^p = \expect_{x\sim \operatorname{Normal}(0,I)} \left[ \left|\expect_{g\sim \operatorname{Normal}(0,I)}[f(\varrho x + \sqrt{1-\varrho^2}\cdot g)]\right|^p\right]\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0eab6434d372220e2c1bf61184491522_l3.png "Rendered by QuickLaTeX.com")
 , obtaining
, obtaining ![\[\norm{T_\varrho f(x)}_p^p \le \expect_{x,g\sim \operatorname{Normal}(0,I)} \left[ \left|f(\varrho x + \sqrt{1-\varrho^2}\cdot g)\right|^p\right].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b598a0bef4b2e7ea6b2e8ee948b9f15a_l3.png "Rendered by QuickLaTeX.com")
 , we have
, we have ![\[\varrho x + \sqrt{1-\varrho^2}\cdot g \sim \operatorname{Normal}(0,I).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-af75cba71dc27112cced020a28aa8c39_l3.png "Rendered by QuickLaTeX.com")
 has the same distribution as . Thus, using in place of , we obtain
has the same distribution as . Thus, using in place of , we obtain ![\[\norm{T_\varrho f(x)}_p^p \le \expect_{x\sim \operatorname{Normal}(0,I)} \left[ \left|f(x)\right|^p\right] = \norm{f(x)}_p^p.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ef6d172ede6d0ca9579d1b3aaf18e9ad_l3.png "Rendered by QuickLaTeX.com")
Gaussian Hypercontractivity
The Gaussian contractivity theorem shows that is no less well-behaved than is. In fact, is more well-behaved than is. This is the content of the Gaussian hypercontractivity theorem:
Theorem 2 (Gaussian hypercontractivity): Choose a noise level
In particular, for
,
![\[\norm{T_\varrho f(x)}_{1+(p-1)/\varrho^2} \le \norm{f(x)}_p.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-431d725cd121372139e21307236b0e6f_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{T_\varrho f(x)}_{1+\varrho^{-2}} \le \norm{f(x)}_2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bc0fd6124965b4c9ed69af922f40f38d_l3.png "Rendered by QuickLaTeX.com")
We have highlighted the case because it is the most useful in practice.
This result shows that as we take smaller, the random variable becomes more and more well-behaved, with tails decreasing at a rate
![\[\prob \{ |T_\varrho f(x)| \ge t \} \le \frac{\norm{T_\varrho f(x)}_{1+(p-1)/\varrho^2}^{1+(p-1)/\varrho^2}}{t^{1 + (p-1)/\varrho^2}} \le \frac{\norm{f(x)}_p^{1+(p-1)/\varrho^2}}{t^{1 + (p-1)/\varrho^2}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cce8fa7a0833532f245765fa1a9c8100_l3.png "Rendered by QuickLaTeX.com")
becomes closer to zero.
We will prove the Gaussian hypercontractivity at the bottom of this post. For now, we will focus on applying this result.
Multilinear Polynomials
A multilinear polynomial  is a multivariate polynomial in the variables
is a multivariate polynomial in the variables  in which none of the variables is raised to a power higher than one. So,
in which none of the variables is raised to a power higher than one. So,
(5) ![\[1+x_1x_2\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d3815294f85a9d7af8b74587e48133b8_l3.png "Rendered by QuickLaTeX.com")
![\[1+x_1+x_1x_2^2\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a12ae7d0e9df2a6ccfcee586af746dff_l3.png "Rendered by QuickLaTeX.com")
 is squared).
is squared).
For multilinear polynomials, we have the following very powerful corollary of Gaussian hypercontractivity:
Corollary 3 (Absolute moments of a multilinear polynomial of Gaussians). Let
. (That is, at most
occur in any monomial of
,
![\[\norm{f(x)}_q \le (q-1)^{k/2} \norm{f(x)}_2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-64e4aee5020d8dc0ff91a8f13e54214a_l3.png "Rendered by QuickLaTeX.com")
Let’s prove this corollary. The first observation is that the noise operator has a particularly convenient form when applied to a multilinear polynomial. Let’s test it out on our example (5) from above. For
![\[f(x) = 1+x_1x_2,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a80e76951d6ebebf98ec09dad419c616_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*}T_\varrho f(x) &= \expect_{g_1,g_2 \sim \operatorname{Normal}(0,1)} \left[1+ (\varrho x_1 + \sqrt{1-\varrho^2}\cdot g_1)(\varrho x_2 + \sqrt{1-\varrho^2}\cdot g_2)\right].\\&= 1 + \expect[\varrho x_1 + \sqrt{1-\varrho^2}\cdot g_1]\expect[\varrho x_2 + \sqrt{1-\varrho^2}\cdot g_2]\\&= 1+ (\varrho x_1)(\varrho x_2) \\&= f(\varrho x).\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-af701855849196fbc6cc6b014e3a2956_l3.png "Rendered by QuickLaTeX.com")
We see that the expectation applies to each variable separately, resulting in each  replaced by
replaced by  . This trend holds in general:
. This trend holds in general:
Proposition 4 (noise operator on multilinear polynomials). For any multilinear polynomial
.
We can use Proposition 4 to obtain bounds on the norms of multilinear polynomials of a Gaussian random variable. Indeed, observe that
![\[f(x) = f(\varrho \cdot x/\varrho) = T_\varrho f(x/\varrho).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-be74992c166a998f5d4e6af5376a0217_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{f(x)}_{1+\varrho^{-2}}=\norm{T_\varrho f(x/\varrho)}_{1+\varrho^{-2}} \le \norm{f(x/\varrho)}_2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1102e3bac6bd91a00b2b9e4720e4b79a_l3.png "Rendered by QuickLaTeX.com")
The final step of our argument will be to compute  . Write as
. Write as
![\[f(x) = \sum_{i_1,\ldots,i_s} a_{i_1,\ldots,i_s} x_{i_1} \cdots x_{i_s}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bbab70512080f4f4823f8e501f882413_l3.png "Rendered by QuickLaTeX.com")
is multilinear,  for
for  . Since is degree-,
. Since is degree-,  . The multilinear monomials
. The multilinear monomials  are orthonormal with respect to the
are orthonormal with respect to the  inner product:
inner product: ![\[\expect[(x_{i_1}\cdots x_{i_s}) \cdot (x_{i_1'}\cdots x_{i_s'})] = \begin{cases} 0 &\text{if } \{i_1,\ldots,i_s\} \ne \{i_1',\ldots,i_{s'}\}, \\1, & \text{otherwise}.\end{cases}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ffae6e30116eaf2f0ba6f2e59c16b3cc_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{f(x)}_2^2 = \sum_{i_1,\ldots,i_s} a_{i_1,\ldots,i_s}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a6320300f83b368256b6451cbd8f730a_l3.png "Rendered by QuickLaTeX.com")
 are
are  . Thus,
. Thus, ![\[\norm{f(x/\varrho)}_2^2 = \sum_{i_1,\ldots,i_s} \varrho^{-2s} a_{i_1,\ldots,i_s}^2 \le \varrho^{-2k} \sum_{i_1,\ldots,i_s} a_{i_1,\ldots,i_s}^2 = \varrho^{-2k}\norm{f(x)}_2^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-60e2eb5d1b10e151be418d12f74ec51c_l3.png "Rendered by QuickLaTeX.com")
Thus, putting all of the ingredients together, we have
![\[\norm{f(x)}_{1+\varrho^{-2}}=\norm{T_\varrho f(x/\varrho)}_p \le \norm{f(x/\varrho)}_2 \le \varrho^{-k} \norm{f(x)}_2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f114ba888a5294007218989be1af2253_l3.png "Rendered by QuickLaTeX.com")
 (equivalently
(equivalently  ), Corollary 3 follows.
), Corollary 3 follows.
Hanson–Wright Inequality
To see the power of the machinery we have developed, let’s prove a version of the Hanson–Wright inequality.
Theorem 5 (suboptimal Hanson–Wright). Let  be a symmetric matrix with zero on its diagonal and be a Gaussian random vector. Then
be a symmetric matrix with zero on its diagonal and be a Gaussian random vector. Then
![\[\prob \{|x^\top A x| \ge t \} \le \exp\left(- \frac{t}{\sqrt{2}\mathrm{e}\norm{A}_{\rm F}} \right) \quad \text{for } t\ge \sqrt{2}\mathrm{e}\norm{A}_{\rm F}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e3d852941995ea03ba8a5437dea4739d_l3.png "Rendered by QuickLaTeX.com")
Hanson–Wright has all sorts of applications in computational mathematics and data science. One direct application is to obtain probabilistic error bounds for the error incurred by a stochastic trace estimation formulas.
This version of Hanson–Wright is not perfect. In particular, it does not capture the Bernstein-type tail behavior of the classical Hanson–Wright inequality
![\[\prob\{|x^\top Ax| \ge t\} \le 2\exp \left( -\frac{t^2}{4\norm{A}_{\rm F}^2+4\norm{A}t} \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-74f8d582a44becc2445f4b52ac3eb4a3_l3.png "Rendered by QuickLaTeX.com")
Let’s prove our suboptimal Hanson–Wright inequality. Set  . Since has zero on its diagonal, is a multilinear polynomial of degree two in the entries of . The random variable is mean-zero, and a short calculation shows its norm is
. Since has zero on its diagonal, is a multilinear polynomial of degree two in the entries of . The random variable is mean-zero, and a short calculation shows its norm is
![\[\norm{f(x)}_2 = \sqrt{\Var(f(x))} = \sqrt{2} \norm{A}_{\rm F}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-04fc820c7aa87627174119b5944e0170_l3.png "Rendered by QuickLaTeX.com")
Thus, by Corollary 3,
(6) ![\[\norm{f(x)}_q \le (q-1) \norm{f(x)}_2 \le \sqrt{2} q \norm{A}_{\rm F} \quad \text{for every } q\ge 2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c01528ece54d71c7e77c1b07a1c4a9c2_l3.png "Rendered by QuickLaTeX.com")
 norms are monotone, (6) holds for
norms are monotone, (6) holds for  as well. Therefore, the standard tail bound for norms (4) gives
as well. Therefore, the standard tail bound for norms (4) gives (7) ![\[\prob \{|x^\top A x| \ge t \} \le \frac{\norm{f(x)}_q^q}{t^q} \le \left( \frac{\sqrt{2}q\norm{A}_{\rm F}}{t} \right)^q\quad \text{for }q\ge 1.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0eaa8096b3cce3efcf8840738de249a4_l3.png "Rendered by QuickLaTeX.com")
Now, we must optimize the value of  to obtain the sharpest possible bound. To make this optimization more convenient, introduce a parameter
to obtain the sharpest possible bound. To make this optimization more convenient, introduce a parameter
![\[\alpha \coloneqq \frac{\sqrt{2}q\norm{A}_{\rm F}}{t}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6362cb79df6daa64768db6b91094ac4e_l3.png "Rendered by QuickLaTeX.com")
 parameter, the bound (7) reads
parameter, the bound (7) reads ![\[\prob \{|x^\top A x| \ge t \} \le \exp\left(- \frac{t}{\sqrt{2}\norm{A}_{\rm F}} \alpha \ln \frac{1}{\alpha} \right) \quad \text{for } t\ge \frac{\sqrt{2}\norm{A}_{\rm F}}{\alpha}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0676270f71519fd22e35fe8d378860ba_l3.png "Rendered by QuickLaTeX.com")
 , yielding the claimed result
, yielding the claimed result
Proof of Gaussian Hypercontractivity
Let’s prove the Gaussian hypercontractivity theorem. For simplicity, we will stick with the  case, but the higher-dimensional generalizations follow along similar lines. The key ingredient will be the Gaussian Jensen inequality, which made a prominent appearance in a previous blog post of mine. Here, we will only need the following version:
case, but the higher-dimensional generalizations follow along similar lines. The key ingredient will be the Gaussian Jensen inequality, which made a prominent appearance in a previous blog post of mine. Here, we will only need the following version:
Theorem 6 (Gaussian Jensen). Let
be a twice differentiable function and let
be jointly Gaussian random variables with covariance matrix
. Then
(8)
holds for all test functionsif, and only if,
(9)
![\[b(\expect[h_1(x)], \expect[h_2(\tilde{x})]) \ge \expect [b(h_1(x),h_2(\tilde{x}))]\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-12fd2ed7b9a9ed4e8c3a2a8abfcfb83c_l3.png "Rendered by QuickLaTeX.com")
![\[\Sigma \circ \nabla^2 b \quad\text{is negative semidefinite on all of $\real^2$}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-982109c83623dffed1091bebab2c8a07_l3.png "Rendered by QuickLaTeX.com")
Here,  denotes the entrywise product of matrices and
denotes the entrywise product of matrices and  is the Hessian matrix of the function
is the Hessian matrix of the function  .
.
To me, this proof of Gaussian hypercontractivity using Gaussian Jensen (adapted from Paata Ivanishvili‘s excellent post) is amazing. First, we reformulate the Gaussian hypercontractivity property a couple of times using some functional analysis tricks. Then we do a short calculation, invoke Gaussian Jensen, and the theorem is proved, almost as if by magic.
Part 1: Tricks
Let’s begin with “tricks” part of the argument.
Trick 1. To prove Gaussian hypercontractivity holds for all functions
.
Indeed, suppose Gaussian hypercontractivity holds for all nonnegative functions . Then, for any function , apply Jensen’s inequality to conclude

Thus, assuming hypercontractivity holds for the nonnegative function  , we have
, we have
![\[\norm{T_\varrho f(x)}_{1+(p-1)/\varrho^2} \le \norm{T_\varrho |f|(x)}_{1+(p-1)/\varrho^2} \le \norm{|f|(x)}_p = \norm{f}_p.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8af3943d192e74b575dd0ac9d66318ce_l3.png "Rendered by QuickLaTeX.com")
as well, and the Trick 1 is proven.
Trick 2. To prove Gaussian hypercontractivity for all
holds for all
with
. Here,
is the Hölder conjugate to
.
![\[\expect[g(x) \cdot T_\varrho f(x)]\le \norm{g(x)}_{q'} \norm{f(x)}_p\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5354683cbb445eec2fa3a6270f5a4930_l3.png "Rendered by QuickLaTeX.com")
Indeed, this follows3This argument may be more clear to parse if we view and  as functions on equipped with the standard Gaussian measure
as functions on equipped with the standard Gaussian measure  . This result is just duality for the
. This result is just duality for the  norm. from the dual characterization of the norm of :
norm. from the dual characterization of the norm of :
![\[\norm{T_\varrho f(x)}_q = \sup_{\substack{\norm{g(x)} < +\infty \\ g\ge 0}} \frac{\expect[g(x) \cdot T_\varrho f(x)]}{\norm{g(x)}_{q'}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fb7781d624035221c888dcb755aa797e_l3.png "Rendered by QuickLaTeX.com")
Trick 3. Let
be a pair of standard Gaussian random variables with correlation
. Then the bilinearized Gaussian hypercontractivity statement is equivalent to
![\[\expect[g(x) f(\tilde{x})]\le (\expect[(g(x)^{q'})])^{1/q'} (\expect[(f(\tilde{x})^{p})])^{1/p}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-484dbbe3223d9ee9eedcd6c61a5cb9e5_l3.png "Rendered by QuickLaTeX.com")
Indeed, define  for the random variable in the definition of the noise operator . The random variable
for the random variable in the definition of the noise operator . The random variable  is standard Gaussian and has correlation with , concluding the proof of Trick 3.
is standard Gaussian and has correlation with , concluding the proof of Trick 3.
Finally, we apply a change of variables as our last trick:
Trick 4. Make the change of variables
and
, yielding the final equivalent version of Gaussian hypercontractivity:
for all functions
and
(in the appropriate spaces).
![\[\expect[v(x)^{1/q'} u(\tilde{x})^{1/p}]\le (\expect[v(x)])^{1/q'} (\expect[u(\tilde{x}))])^{1/p}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e344261445ca42165f91b7a41bd4f27c_l3.png "Rendered by QuickLaTeX.com")
Part 2: Calculation
We recognize this fourth equivalent version of Gaussian hypercontractivity as the conclusion (8) to Gaussian Jensen with
![\[b(u,v) = u^{1/p}v^{1/q'}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-66a908e9dcc2f7c2143bdd800b2bc67d_l3.png "Rendered by QuickLaTeX.com")
We now enter the calculation part of the proof. First, we compute the Hessian of :
![\[\nabla^2 b(u,v) = u^{1/p}v^{1/q'}\cdot\begin{bmatrix} - \frac{1}{pp'} u^{-2} & \frac{1}{pq'} u^{-1}v^{-1} \\ \frac{1}{pq'} u^{-1}v^{-1} & - \frac{1}{qq'} v^{-2}\end{bmatrix}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1e4e90d7081679b6e70c3d15c433f32d_l3.png "Rendered by QuickLaTeX.com")
 for the Hölder conjugate to . By Gaussian Jensen, to prove Gaussian hypercontractivity, it suffices to show that
for the Hölder conjugate to . By Gaussian Jensen, to prove Gaussian hypercontractivity, it suffices to show that ![\[\nabla^2 b(u,v)\circ \twobytwo{1}{\varrho}{\varrho}{1}= u^{1/p}v^{1/q'}\cdot\begin{bmatrix} - \frac{1}{pp'} u^{-2} & \frac{\varrho}{pq'} u^{-1}v^{-1} \\ \frac{\varrho}{pq'} u^{-1}v^{-1} & - \frac{1}{qq'} v^{-2}\end{bmatrix}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6a0103067b2861534c02b41257561c60_l3.png "Rendered by QuickLaTeX.com")
 . There are a few ways we can make our lives easier. Write this matrix as
. There are a few ways we can make our lives easier. Write this matrix as ![\[\nabla^2 b(u,v)\circ \twobytwo{1}{\varrho}{\varrho}{1}= u^{1/p}v^{1/q'}\cdot B^\top\begin{bmatrix} - \frac{p}{p'} & \varrho \\ \varrho & - \frac{q'}{q} \end{bmatrix}B \quad \text{for } B = \operatorname{diag}(p^{-1}u^{-1},(q')^{-1}v^{-1}).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-133058d7adc70a8cbc73237908ead12d_l3.png "Rendered by QuickLaTeX.com")
 by nonnegative and conjugation
by nonnegative and conjugation  both preserve negative semidefiniteness, so it is sufficient to prove
both preserve negative semidefiniteness, so it is sufficient to prove ![\[H = \begin{bmatrix} - \frac{p}{p'} & \varrho \\ \varrho & - \frac{q'}{q} \end{bmatrix} \quad \text{is negative semidefinite}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e76306c9c94205e495a55477fa2f0359_l3.png "Rendered by QuickLaTeX.com")
 are negative, at least one of ‘s eigenvalues is negative.4Indeed, by the Rayleigh–Ritz variational principle, the smallest eigenvalue of a symmetric matrix is
are negative, at least one of ‘s eigenvalues is negative.4Indeed, by the Rayleigh–Ritz variational principle, the smallest eigenvalue of a symmetric matrix is  Taking
Taking  for
for  to be each of the standard basis vectors, shows that the smallest eigenvalue of is smaller than the smallest diagonal entry of . Therefore, to prove is negative semidefinite, we can prove that its determinant (= product of its eigenvalues) is nonnegative. We compute
to be each of the standard basis vectors, shows that the smallest eigenvalue of is smaller than the smallest diagonal entry of . Therefore, to prove is negative semidefinite, we can prove that its determinant (= product of its eigenvalues) is nonnegative. We compute ![\[\det H = \frac{pq'}{p'q} - \varrho^2 .\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1d039c438c40277dc480013fe3dfbb94_l3.png "Rendered by QuickLaTeX.com")
 ,
,  , :
, : ![\[\det H = \frac{pq'}{p'q} - \varrho^2 = \frac{p-1}{q-1} - \varrho^2 = \frac{p-1}{(p-1)/\varrho^2} - \varrho^2 = 0.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c2ea946be5f8bedf9507e790b6e0cd8c_l3.png "Rendered by QuickLaTeX.com")
 . We conclude is negative semidefinite, proving the Gaussian hypercontractivity theorem.
. We conclude is negative semidefinite, proving the Gaussian hypercontractivity theorem.
 of an
of an  matrix
matrix  . The classical method for this purpose is the
. The classical method for this purpose is the ![\[\hat{\tr} = \frac{1}{m} \left( x_1^\top Ax_1 + \cdots + x_m^\top Ax_m \right),\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c2cf5e846664b66392f4fe2622eb6eec_l3.png "Rendered by QuickLaTeX.com")
 are
are ![\[\expect[x_ix_i^\top] = I.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-32e3e4d06e209eb374b8308e7e00c8e4_l3.png "Rendered by QuickLaTeX.com")
 with equal probabilities (i.e.,
with equal probabilities (i.e.,  ,
,  .
.![\expect[\hat{\tr}] = \tr(A)](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b723b7e77c79b9c958ab554ff5ec5890_l3.png "Rendered by QuickLaTeX.com") , the
, the  is equal to the
is equal to the  of the Girard–Hutchinson estimator with different choices of test vectors. In that post, I stated the formulas for different choices of test vectors (Gaussian, random signs, sphere) and showed how those formulas could be proven.
of the Girard–Hutchinson estimator with different choices of test vectors. In that post, I stated the formulas for different choices of test vectors (Gaussian, random signs, sphere) and showed how those formulas could be proven. be the
be the ![\[\overline{\lambda} = \frac{\lambda_1 + \cdots + \lambda_n}{n}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8b81d9f9da5622b280b2fa50cbaa4851_l3.png "Rendered by QuickLaTeX.com")
![\[\Var(\hat{\tr}_{\rm Gaussian}) = \frac{1}{m} \cdot 2 \sum_{i=1}^n \lambda_i^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ab8e3bf02ed41a57c1ddb14423ff98eb_l3.png "Rendered by QuickLaTeX.com")
![\[\Var(\hat{\tr}_{\rm sphere}) = \frac{1}{m} \cdot \frac{n}{n+2} \cdot 2\sum_{i=1}^n (\lambda_i - \overline{\lambda})^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e4e35a6f5234490c062c33fab8fc772b_l3.png "Rendered by QuickLaTeX.com")
 is smaller than
is smaller than  by a factor of
by a factor of  . This improvement is quite minor. Second, and more importantly,
. This improvement is quite minor. Second, and more importantly,  matrix
matrix  and
and  with a (
with a ( , we take
, we take  . Below show the variance of Girard–Hutchinson estimator for different distributions for the test vector. We see that the sphere distribution leads to a trace estimate which has a variance 300× smaller than the Gaussian distribution. For this example, the sphere and random sign distributions are similar.
. Below show the variance of Girard–Hutchinson estimator for different distributions for the test vector. We see that the sphere distribution leads to a trace estimate which has a variance 300× smaller than the Gaussian distribution. For this example, the sphere and random sign distributions are similar. )
)

![\[\Var(\hat{\tr}_{\rm signs}) = 2 \sum_{i\ne j} A_{ij}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fdb49b7246114e38347ac231d9f8b320_l3.png "Rendered by QuickLaTeX.com")
 depends on the size of the off-diagonal entries of
depends on the size of the off-diagonal entries of ![\[\tr(A) \coloneqq \sum_{i=1}^n A_{ii}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4a03d788b895df85c11739dd6183fce7_l3.png "Rendered by QuickLaTeX.com")
 . Our goal is to form an estimate
. Our goal is to form an estimate ![\[\expect\left[\frac{|\hat{\tr}-\tr(A)|}{\tr(A)}\right] \le \varepsilon \quad \text{using } m= \frac{\rm const}{\varepsilon^2} \text{ matvecs}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f5fb46e94d7eb16388f9b64b89b55695_l3.png "Rendered by QuickLaTeX.com")
 ) requires roughly
) requires roughly  matvecs!
matvecs!
![\[\expect\left[\frac{|\hat{\tr}-\tr(A)|}{\tr(A)}\right] \le \varepsilon \quad \text{using } m= \frac{\rm const}{\varepsilon} \text{ matvecs}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f02329ffe8815d7accd7cdc6b6d98288_l3.png "Rendered by QuickLaTeX.com")
 matvecs to achieve 1% error!
matvecs to achieve 1% error! ![\[\expect\left[\frac{|\hat{\tr}-\tr(A)|}{\tr(A)}\right] \le \varepsilon \quad \text{using } m= \frac{\rm const}{\varepsilon^{0.999}} \text{ matvecs}?\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-db093bc2c65d7a41027f2a3ea2ed0b8e_l3.png "Rendered by QuickLaTeX.com")
 . The algorithm is allowed to be adaptive: It can use the matvecs
. The algorithm is allowed to be adaptive: It can use the matvecs  it has already collected to decide which vector
it has already collected to decide which vector  to present next. We measure the cost of the algorithm in terms of the number of matvecs alone, and the algorithm knows nothing about the psd matrix
to present next. We measure the cost of the algorithm in terms of the number of matvecs alone, and the algorithm knows nothing about the psd matrix  and
and  . Then
. Then  would be an allowed input vector, but
would be an allowed input vector, but  would not be (too many digits after the decimal place). Similarly,
would not be (too many digits after the decimal place). Similarly,  would not be valid because its entries exceed
would not be valid because its entries exceed  . For this analysis of trace estimation, we use
. For this analysis of trace estimation, we use  (no powers of ten allowed)!
(no powers of ten allowed)!![\[\expect\left[\frac{|\hat{\tr}-\tr(A)|}{\tr(A)}\right] \le \varepsilon \quad \text{using } m= \frac{\rm const}{\varepsilon^{0.999}} \text{ matvecs}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9a779882022766ae2b0dbd26f61820b4_l3.png "Rendered by QuickLaTeX.com")
 of both their inputs.
of both their inputs. with
with  and
and ![\[\text{Case 0: } x^\top y \ge\sqrt{n} \quad \text{or} \quad \text{Case 1: } x^\top y \le -\sqrt{n}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-18693e0c147a787651023d68bc6ee988_l3.png "Rendered by QuickLaTeX.com")
 , determines whether they are in case 0 or case 1, and sends Bob a single bit to communicate the answer. This procedure requires
, determines whether they are in case 0 or case 1, and sends Bob a single bit to communicate the answer. This procedure requires  bits of communication.
bits of communication. bits of communication, say
bits of communication, say  probability for every pair of inputs
probability for every pair of inputs  bits of communication.
bits of communication. and
and  . For the less familiar, it can be helpful to interpret
. For the less familiar, it can be helpful to interpret  , and consider (but do not form!) the positive semidefinite matrix
, and consider (but do not form!) the positive semidefinite matrix ![\[A = (X+Y)^\top (X+Y).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-12c37bc5230cb151322c3079bda9ed4e_l3.png "Rendered by QuickLaTeX.com")
![\[\tr(A) = \tr(X^\top X) + 2\tr(X^\top Y) + \tr(Y^\top Y) = 2n + 2(x^\top y).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3ac0f1ff7ee1987c02df3f54d7db0b9f_l3.png "Rendered by QuickLaTeX.com")
 :
:![\[\text{Case 0: } \tr(A)\ge 2n + 2\sqrt{n} \quad \text{or} \quad \text{Case 1: } \tr(A) \le 2n-2\sqrt{n}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-524300396d8a4514223f78c9b0ef5500_l3.png "Rendered by QuickLaTeX.com")
 or
or  ) and sends the result to Bob.
) and sends the result to Bob. for some vector
for some vector  with entries between
with entries between  whose entries are integers between
whose entries are integers between  and
and  . Since
. Since  , interconverting between
, interconverting between  is trivial. Alice and Bob’s procedure for computing
is trivial. Alice and Bob’s procedure for computing  .
. and sends it to Alice.
and sends it to Alice. and sends it to Bob.
and sends it to Bob. and sends its to Alice.
and sends its to Alice. .
. and
and  are
are  and have
and have  and
and  . We conclude the communication cost for one matvec is
. We conclude the communication cost for one matvec is  bits.
bits. , BestTraceAlgorithm requires at most
, BestTraceAlgorithm requires at most  matvecs and, for any positive semidefinite input matrix
matvecs and, for any positive semidefinite input matrix ![\[\expect\left[\frac{|\hat{\tr}-\tr(A)|}{\tr(A)}\right] \le \varepsilon.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6916e3d69eb2e3156b0dca29cc675119_l3.png "Rendered by QuickLaTeX.com")
 matvecs.
matvecs.
![\[\left| \frac{\hat{\tr} - \tr(A)}{\tr(A)} \right| \le \frac{1}{\sqrt{n}},\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-047558693bcc30d440d0946612c51d11_l3.png "Rendered by QuickLaTeX.com")
 matvecs in total. The total communication is
matvecs in total. The total communication is  bits. Chakrabati and Regev showed that Gap-Hamming requires
bits. Chakrabati and Regev showed that Gap-Hamming requires  bits of communication (for some
bits of communication (for some  ) to solve the Gap-Hamming problem with
) to solve the Gap-Hamming problem with  , then Alice and Bob fail to solve the Gap-Hamming problem with at least
, then Alice and Bob fail to solve the Gap-Hamming problem with at least  probability. Thus,
probability. Thus, ![\[\text{If } m < \frac{cn}{T} = \Theta\left( \frac{\sqrt{n}}{b+\log n} \right), \quad \text{then } \left| \frac{\hat{\tr} - \tr(A)}{\tr(A)} \right| > \frac{1}{\sqrt{n}} \text{ with probability at least } \frac{1}{3}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5bfe46d9b0837c94540ec3beb61f54d9_l3.png "Rendered by QuickLaTeX.com")
![\[\text{If }\left| \frac{\hat{\tr} - \tr(A)}{\tr(A)} \right| \le \frac{1}{\sqrt{n}}\text{ with probability at least } \frac{2}{3}, \quad \text{then } m \ge \Theta\left( \frac{\sqrt{n}}{b+\log n} \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-63477ee2387425ede19c2c39833bb2db_l3.png "Rendered by QuickLaTeX.com")
 . Then, by (3) and
. Then, by (3) and ![\[\left| \frac{\hat{\tr} - \tr(A)}{\tr(A)} \right| \le \frac{1}{\sqrt{n}} \quad \text{with probability at least }\frac{2}{3}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bf9214804f204aebae161f5f99a2accb_l3.png "Rendered by QuickLaTeX.com")
![\[m \ge \Theta\left( \frac{\sqrt{n}}{b+\log n} \right) \text{ matvecs}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6e01cd6afae6d7dc63aabde27c2178c2_l3.png "Rendered by QuickLaTeX.com")
 , we conclude that any trace estimation algorithm, even BestTraceAlgorithm, requires
, we conclude that any trace estimation algorithm, even BestTraceAlgorithm, requires![\[m \ge \Theta \left( \frac{1}{\varepsilon (b+\log(1/\varepsilon))} \right) \text{ matvecs}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-330d47c1891be07282d275eb0360aed2_l3.png "Rendered by QuickLaTeX.com")
 using even
using even  matvecs. This proves the MMMW theorem.
matvecs. This proves the MMMW theorem.
 be a domain and let
be a domain and let  be a (
be a ( . We consider the task of evaluating
. We consider the task of evaluating ![\[I[f] = \int_\Omega f(x) g(x) \, \mathrm{d}\mu(x).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ab120ac4901519f4b1568ade408707bb_l3.png "Rendered by QuickLaTeX.com")
![I[f]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9496abb9e72cf1ad2b3e40a94f4fec37_l3.png "Rendered by QuickLaTeX.com") for multiple different functions
for multiple different functions ![\[\hat{I}_{w,s}[f] = \sum_{i=1}^n w_i f(s_i) \approx I[f].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d36251a9e4651630d9d7d6aa81fbfbf5_l3.png "Rendered by QuickLaTeX.com")
 and points
and points  such that the approximation
such that the approximation ![\hat{I}_{w,s}[f] \approx I[f]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b5fadb09388be24ddec46a434981d95e_l3.png "Rendered by QuickLaTeX.com") is accurate.
is accurate.
 be an RKHS with
be an RKHS with  . We can interpret the norm as assigning a roughness
. We can interpret the norm as assigning a roughness  to each function
to each function  . It is related to the RKHS
. It is related to the RKHS  by the reproducing property
by the reproducing property![\[f(x)=\langle f, k(x,\cdot)\rangle \quad \text{for every }f\in\mathcal{H},x\in\Omega.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6d0724181706b6c01955310a7292b07d_l3.png "Rendered by QuickLaTeX.com")
 represents the univariate function obtained by setting the first input of
represents the univariate function obtained by setting the first input of  . Let’s first assume that the nodes
. Let’s first assume that the nodes  are fixed, and talk about how to pick the weights
are fixed, and talk about how to pick the weights  that we’ll called the ideal weights. There (at least) are five equivalent ways of characterizing the ideal weights. We’ll present all of them. As an exercise, you can try and convince yourself that these characterizations are equivalent, giving rise to the same weights.
that we’ll called the ideal weights. There (at least) are five equivalent ways of characterizing the ideal weights. We’ll present all of them. As an exercise, you can try and convince yourself that these characterizations are equivalent, giving rise to the same weights. .
.![\[\hat{I}_{w_\star,s}[k(s_i,\cdot)]=I[k(s_i,\cdot)] \quad \text{for } i=1,2,\ldots,n.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-45aa6eed6211812b47bb91ff2a58b43e_l3.png "Rendered by QuickLaTeX.com")
 :
:![\[\sum_{j=1}^n k(s_i,s_j)w^\star_j = \int_\Omega k(s_i,x) g(x)\,\mathrm{d}\mu(x) \quad \text{for }i=1,2,\ldots,n.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2ca2ce892f9d441ad8a17abcf969ca8c_l3.png "Rendered by QuickLaTeX.com")
 is the ideal weights.
is the ideal weights.
 at the nodes, obtaining an interpolant
at the nodes, obtaining an interpolant  . Then, obtain an approximation to the integral by integrating the interpolant:
. Then, obtain an approximation to the integral by integrating the interpolant:![\[\hat{I}_{w^\star,s}[f] \coloneqq \int_\Omega \hat{f}(x) g(x) \, \mathrm{d}\mu(x).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-14e696801e85cb650607a92cd2b6a42c_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{f} = \argmin \{ \norm{h} : h(s_i) = f(s_i) \text{ for } i=1,\ldots,n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2507040c13a322806e3a0d81a9d8926e_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{f} = \sum_{i=1}^n \alpha_i k(\cdot,s_i)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2768fe50b96718c1519054650d8bbd3d_l3.png "Rendered by QuickLaTeX.com")
 .With a little algebra, you can show that the integral of
.With a little algebra, you can show that the integral of ![\[I[\hat{f}] = \sum_{i=1}^n w^\star_i f(s_i),\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-dfd771f09002913d91123004a3372f7a_l3.png "Rendered by QuickLaTeX.com")
![\[\operatorname{Err}(w,s)=\sup_{\norm{f}\le 1}\left| I[f] - \hat{I}_{w,s}[f]\right|.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9f468f5797f49ba8cb5c557a88fa0a83_l3.png "Rendered by QuickLaTeX.com")
 is the highest possible quadrature error for a function
is the highest possible quadrature error for a function  of norm at most 1.
of norm at most 1.
![\[w^\star=\operatorname*{argmin}_{w\in\real^n}\operatorname{Err}(w,s).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-91513ad1e13f98b3d21ec99003ef729a_l3.png "Rendered by QuickLaTeX.com")
 for a mean-zero Gaussian process with
for a mean-zero Gaussian process with ![\[\Cov(f(x),f(y))=k(x,y)\quad \text{for every } x,y\in\Omega.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e26f38b7f58fe9f9d8c7a9a51aa68ebc_l3.png "Rendered by QuickLaTeX.com")
![\[\operatorname{MSE}(w,s)\coloneqq \expect_{f\sim\operatorname{GP}(0,k)} \left( I[f] - \hat{I}_{w,s}[f] \right)^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7e11807473beb060a6fea3f5aa419bf2_l3.png "Rendered by QuickLaTeX.com")
![\[\operatorname{MSE}(w,s)=\operatorname{Err}(w,s)^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ad03024d84ea4faa12ecedde8d36f3b4_l3.png "Rendered by QuickLaTeX.com")
![\[w^\star=\operatorname*{argmin}_{w\in\real^n}\operatorname{MSE}(w,s).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0521bed12adafe0d73fcb5a5a568fcae_l3.png "Rendered by QuickLaTeX.com")
 . The integral of this random function
. The integral of this random function ![I[h]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d99103c1657617fde090847d111aac8a_l3.png "Rendered by QuickLaTeX.com") is a random variable. To numerically integrate a function
is a random variable. To numerically integrate a function  agreeing with
agreeing with ![\[\hat{I}_{w^\star,s}[f]\coloneqq \expect_{h\sim\operatorname{GP}(0,k)}[I[h] \mid h(s_i)=f(s_i) \text{ for } i=1,\ldots,n].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-44a9d031fe0d7307e3012608a80dffbd_l3.png "Rendered by QuickLaTeX.com")
 , it is reasonable to add an additional constraint that the weights
, it is reasonable to add an additional constraint that the weights ![\[w\in\Delta\coloneqq \left\{ p\in\real^n_+ : \sum_{i=1}^n p_i = 1\right\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d5f5e9e0975c0a82bcfd5c08c75653d5_l3.png "Rendered by QuickLaTeX.com")
 ; thus, in effect, quadrature amounts to approximating one probability measure
; thus, in effect, quadrature amounts to approximating one probability measure  . Additional constraints such as these can easily be imposed when using the optimization characterizations 3 and 4 of the ideal weights. See
. Additional constraints such as these can easily be imposed when using the optimization characterizations 3 and 4 of the ideal weights. See  ? To pick the nodes, it seems sensible to try and minimize the worst-case error
? To pick the nodes, it seems sensible to try and minimize the worst-case error  with the ideal weights
with the ideal weights ![\[\operatorname{Err}(w^\star,s) = \norm{\int_\Omega (k(\cdot,x) - \hat{k}_s(\cdot,x)) g(x) \, \mathrm{d}\mu(x)}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-89b40eb87dd22ab3819a1ef237a0874d_l3.png "Rendered by QuickLaTeX.com")
 is the
is the ![\[\hat{k}_s(x,y) = k(x,s) k(s,s)^{-1} k(s,y).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8c2b1cfd34c6b7cf6318f7b8b5ad08cd_l3.png "Rendered by QuickLaTeX.com")
 for the kernel matrix with
for the kernel matrix with  entry
entry  and
and  and
and  for the row and column vectors with
for the row and column vectors with  th entry
th entry  and
and  .
.
 as accurate as possible.
as accurate as possible. is and, thus, the smaller the error
is and, thus, the smaller the error  , it has a high probability of placing the next node
, it has a high probability of placing the next node  far from the previously selected nodes.
far from the previously selected nodes.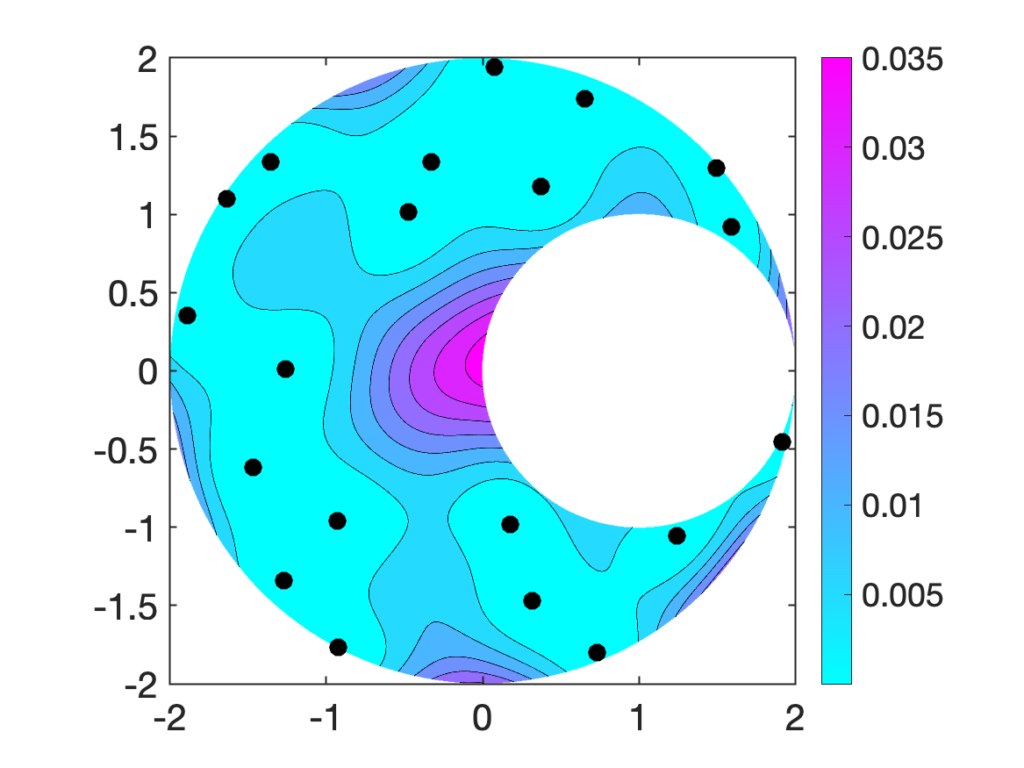
 seeks to compress a high-dimensional matrix
seeks to compress a high-dimensional matrix  or vector
or vector  to a lower-dimensional sketched matrix
to a lower-dimensional sketched matrix  or vector
or vector  . The quality of a sketching matrix for a matrix
. The quality of a sketching matrix for a matrix ![\[(1-\varepsilon) \norm{x} \le \norm{Sx} \le (1+\varepsilon) \norm{x} \quad \text{for every } x \in \operatorname{col}(A).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-18bca665601c0d5aa74f454d2a2cdf6d_l3.png "Rendered by QuickLaTeX.com")
 denotes the
denotes the  .
. matrix.
matrix. (one million) and output dimension
(one million) and output dimension  . For the SRTT, we use the
. For the SRTT, we use the  .
.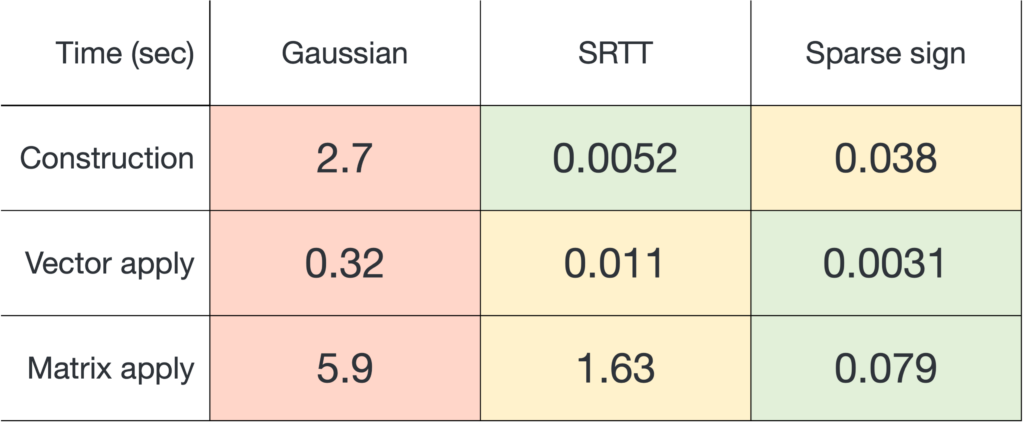
 and applying it to a matrix
and applying it to a matrix  , sparse sign embeddings are 14× faster than SRTTs and 73× faster than Gaussian embeddings.
, sparse sign embeddings are 14× faster than SRTTs and 73× faster than Gaussian embeddings. for
for  and
and  using the MATLAB
using the MATLAB  between 100 and 10,000. We report the distortion averaged over 100 trials. The theoretically predicted value
between 100 and 10,000. We report the distortion averaged over 100 trials. The theoretically predicted value  (equivalently,
(equivalently,  ) is shown as a dashed line.
) is shown as a dashed line.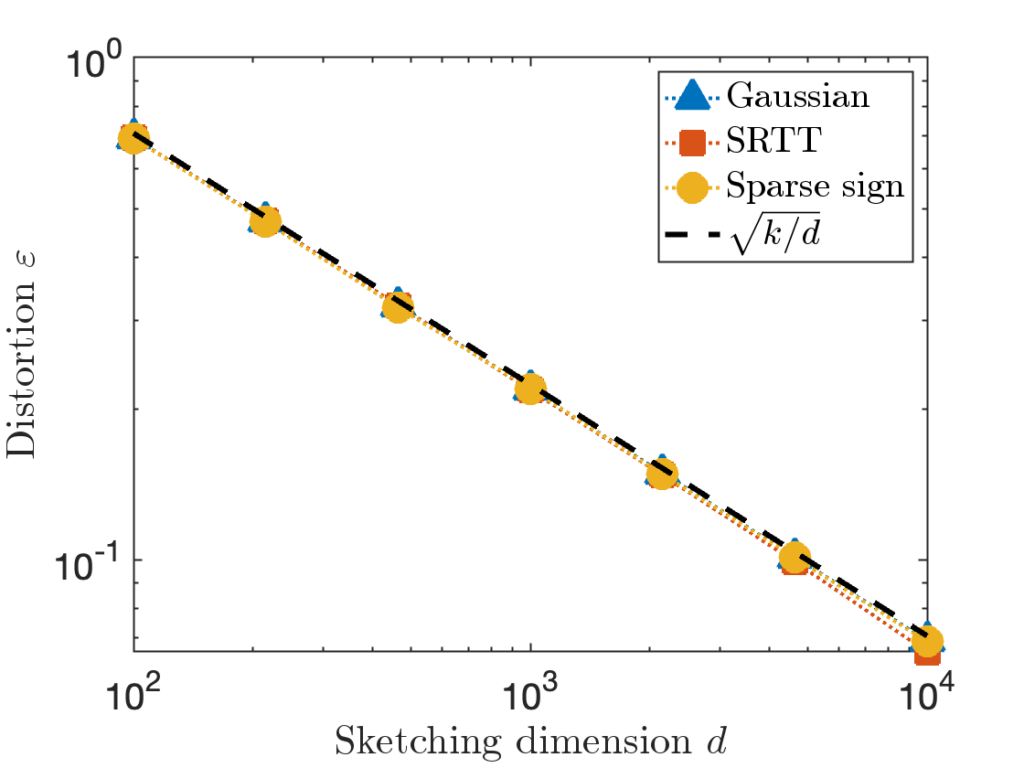
 is taken to be a matrix with independent standard Gaussian random values.
is taken to be a matrix with independent standard Gaussian random values. is taken to be the
is taken to be the  is taken to be the
is taken to be the  identity matrix stacked onto a
identity matrix stacked onto a  matrix of zeros.
matrix of zeros.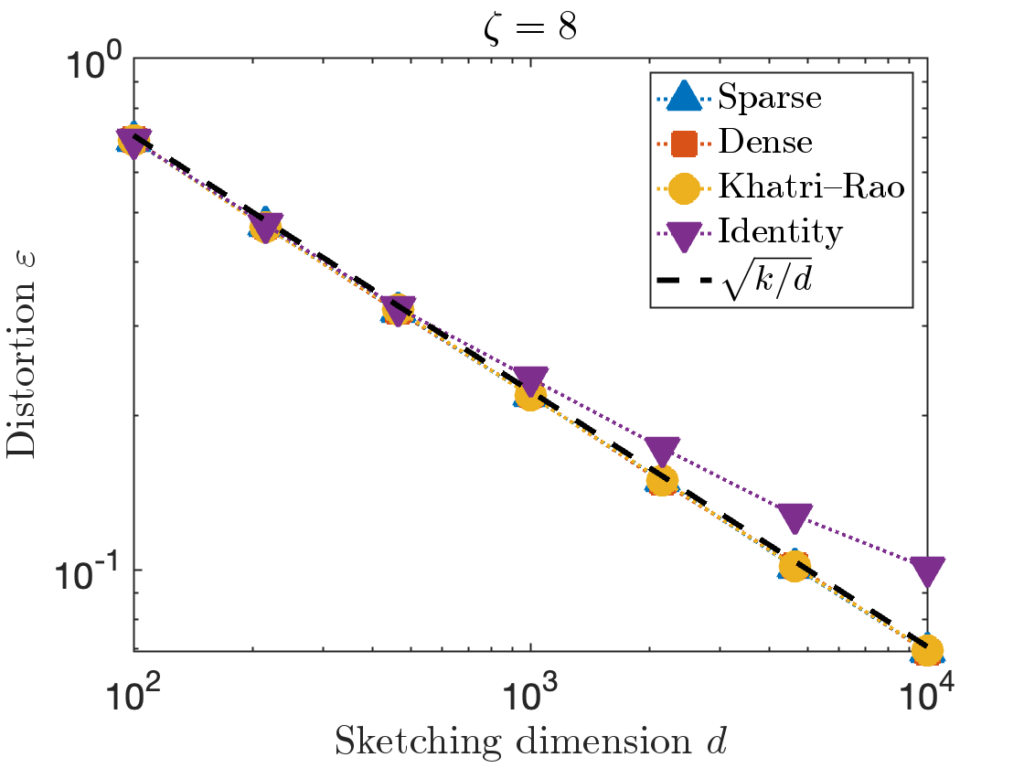
 . However, for the last test matrix “Identity”, we see the distortion begins to slightly exceed this predicted distortion for
. However, for the last test matrix “Identity”, we see the distortion begins to slightly exceed this predicted distortion for  .
. , we can increase the value of the sparsity parameter
, we can increase the value of the sparsity parameter  . We recommend
. We recommend ![\[\zeta = \max \left( 8 , \left\lceil 2\sqrt{\frac{d}{k}} \right\rceil \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b28b75e96d6b15a5d9985b8aa381d897_l3.png "Rendered by QuickLaTeX.com")
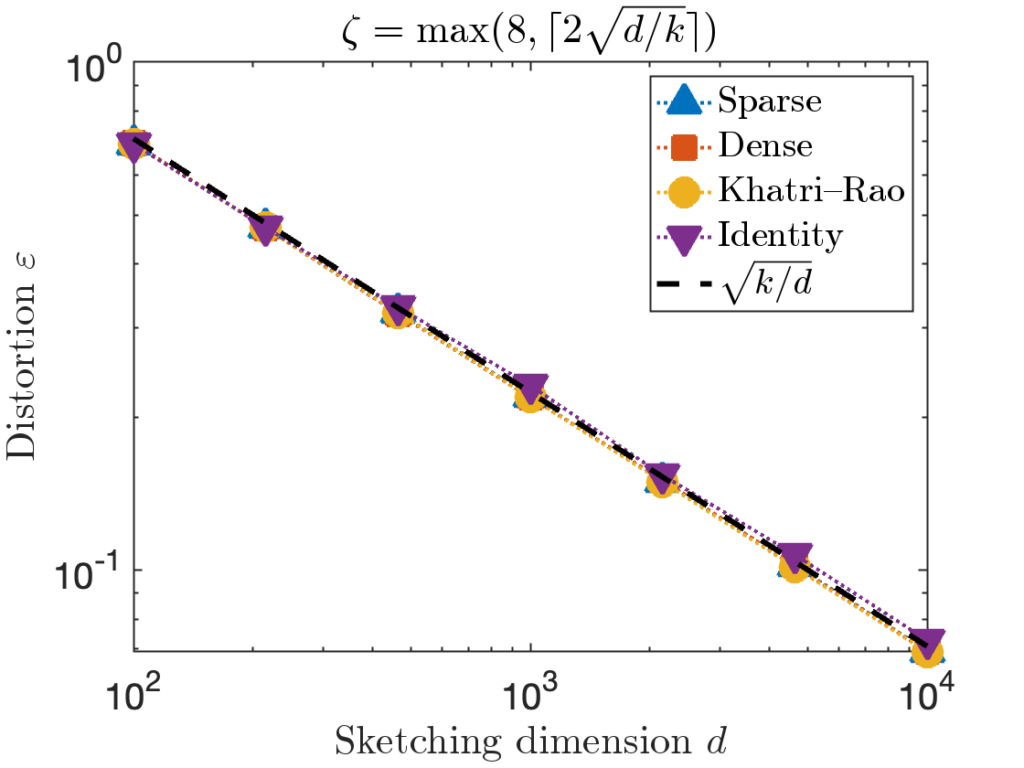
 can be necessary to achieve the optimal distortion.
can be necessary to achieve the optimal distortion.![\[S = \frac{1}{\sqrt{\zeta}} \begin{bmatrix} s_1 & \cdots & s_n \end{bmatrix}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-240419555cc566f76ea74282e84c5e81_l3.png "Rendered by QuickLaTeX.com")
 is an independent and randomly generated to contain exactly
is an independent and randomly generated to contain exactly ![\[(1-\varepsilon) \norm{x} \le \norm{Sx} \le (1+\varepsilon) \norm{x} \quad \text{for all }x \in \operatorname{col}(A).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d314ea7cf5e68537f11898d4ed2931f6_l3.png "Rendered by QuickLaTeX.com")
![\[d = \frac{k}{\varepsilon^2} \quad \text{and} \quad \zeta = \max\left(8,\frac{2}{\varepsilon}\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-754f91c06d677b1c84e4f42155952044_l3.png "Rendered by QuickLaTeX.com")
 . The value
. The value  has demonstrated deficiencies and should almost always be avoided (see below). The scaling
has demonstrated deficiencies and should almost always be avoided (see below). The scaling  is derived from the
is derived from the ![\[d = \mathcal{O} \left( \frac{k \log k}{\varepsilon^2} \right) \quad \text{and} \quad \zeta = \mathcal{O}\left( \frac{\log k}{\varepsilon} \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-05d5afd9741741fcca989c6ba9141837_l3.png "Rendered by QuickLaTeX.com")
 factor and the lack of explicit constants in the
factor and the lack of explicit constants in the  and can also be generated using a single line. The real challenge to generating sparse sign embeddings in MATLAB is the row indices, since each batch of
and can also be generated using a single line. The real challenge to generating sparse sign embeddings in MATLAB is the row indices, since each batch of  sparse sign embedding with sparsity
sparse sign embedding with sparsity  and weights
and weights  . To apply
. To apply  and reweight them using the weights:
and reweight them using the weights:![\[b \in \real^n \longmapsto Sb = (w_1 b_{i_1},\ldots,w_db_{i_d}) \in \real^d.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ca8f027ac8b72885073f98d47cfd38c5_l3.png "Rendered by QuickLaTeX.com")
 for the hard “Identity” test matrix used above.
for the hard “Identity” test matrix used above.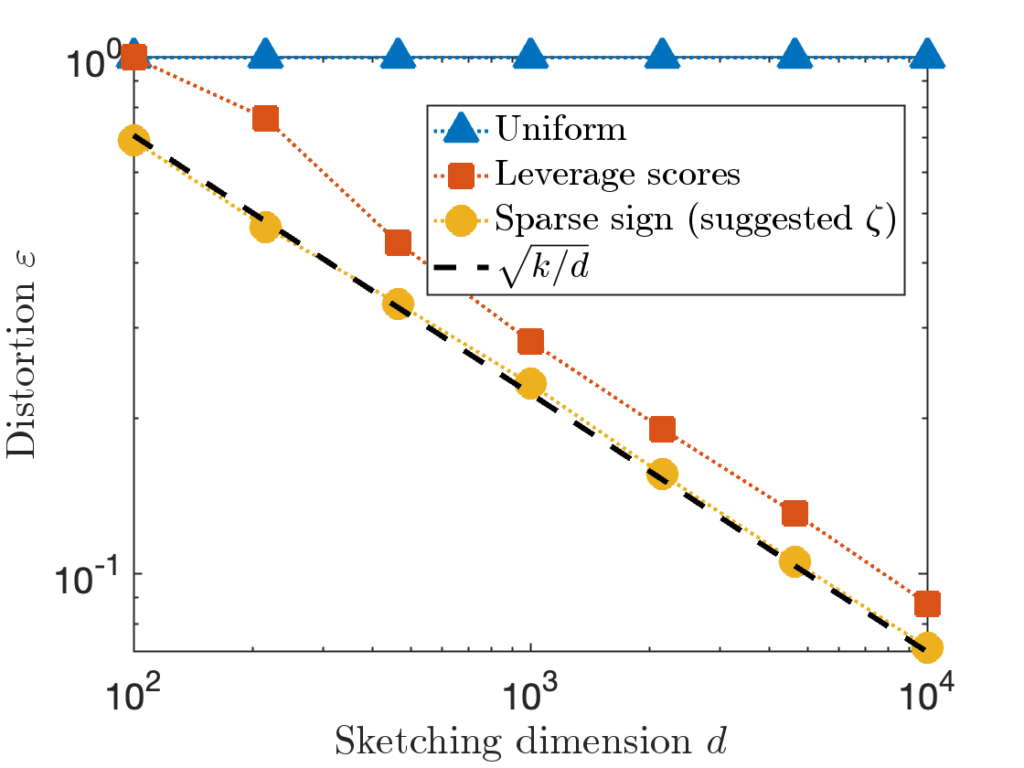
 for each row of
for each row of  cost, much higher than other types of sketches.
cost, much higher than other types of sketches. , and compare the distortion of CountSketch to the sparse sign embedding with parameters
, and compare the distortion of CountSketch to the sparse sign embedding with parameters  :
: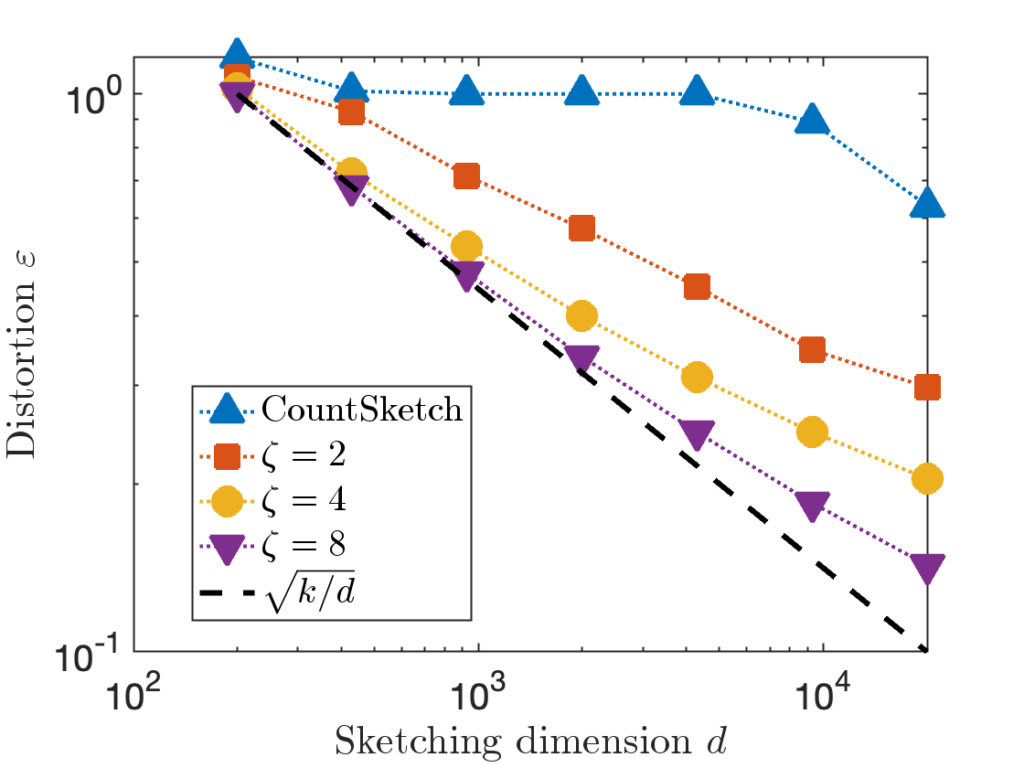
 , 20× higher than
, 20× higher than  in order to achieve distortion
in order to achieve distortion  (or perhaps
(or perhaps  ). This difference between
). This difference between  for CountSketch and
for CountSketch and  for other sketching matrices is a at the root of CountSketch’s woefully bad performance on some inputs.
for other sketching matrices is a at the root of CountSketch’s woefully bad performance on some inputs. is an informal symbol meaning “proportional to”.
is an informal symbol meaning “proportional to”. . This is Theorem 16 in
. This is Theorem 16 in  , where
, where  is a CountSketch of size
is a CountSketch of size  and
and  is a Gaussian sketching matrix of size
is a Gaussian sketching matrix of size  .
. is a CountSketch matrix with output dimension
is a CountSketch matrix with output dimension  , then the distortion of
, then the distortion of  with high probability.
with high probability.![\[SA = \begin{bmatrix} s_1 & \cdots & s_k \end{bmatrix}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-31bf925d44deb6fbfa4d5884e90c6d7e_l3.png "Rendered by QuickLaTeX.com")
 has a single
has a single  in a uniformly random location
in a uniformly random location  .
.
 are not all different from each other, say
are not all different from each other, say  . Set
. Set  , where
, where  is the standard basis vector with
is the standard basis vector with  but
but  . Thus, for the distortion relation
. Thus, for the distortion relation ![\[(1-\varepsilon) \norm{x} =(1-\varepsilon)\sqrt{2} \le 0 = \norm{(SA)x}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9051c8196e74dfbd5c18d6711b0cb056_l3.png "Rendered by QuickLaTeX.com")
 . Thus,
. Thus, ![\[\prob \{ \varepsilon \ge 1 \} \ge \prob \{ j_1,\ldots,j_k \text{ are not distinct} \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8c0d45952014a332d5d44be9f33bd4e8_l3.png "Rendered by QuickLaTeX.com")
 pairs of people. Each pair of people has a
pairs of people. Each pair of people has a  chance of sharing a birthday, so the expected number of birthdays in a room of 23 people is
chance of sharing a birthday, so the expected number of birthdays in a room of 23 people is  . Since are 0.69 birthdays shared on average in a room of 23 people, it is perhaps less surprising that 23 is the critical number at which the chance of two people sharing a birthday exceeds 50%.
. Since are 0.69 birthdays shared on average in a room of 23 people, it is perhaps less surprising that 23 is the critical number at which the chance of two people sharing a birthday exceeds 50%. and
and  in CountSketch have a
in CountSketch have a  chance of being the same. There are
chance of being the same. There are  pairs of indices, so the expected number of equal indices
pairs of indices, so the expected number of equal indices  . Thus, we should anticipate
. Thus, we should anticipate  is required to ensure that
is required to ensure that ![\[\prob \{ j_1,\ldots,j_k \text{ are not distinct} \} = 1 - \prob \{ j_1,\ldots,j_k \text{ are distinct} \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-838b7c482de601a1b88174faaeaeae01_l3.png "Rendered by QuickLaTeX.com")
 are all distinct, the probability
are all distinct, the probability  are distinct is just the probability that
are distinct is just the probability that  values
values ![\[\prob\{ j_1,\ldots,j_i \text{ are distinct} \mid j_1,\ldots,j_{i-1} \text{ are distinct}\} = 1 - \frac{i-1}{d}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a2aaad1d0bb3da4ffbcdcea74e5546a9_l3.png "Rendered by QuickLaTeX.com")
![\[\prob \{ j_1,\ldots,j_k \text{ are distinct} \} = \prod_{i=1}^k \left(1 - \frac{i-1}{d} \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-274b188c4b1ef4289d715a6d71fec699_l3.png "Rendered by QuickLaTeX.com")
 for every
for every  , obtaining
, obtaining![\[\mathbb{P} \{ j_1,\ldots,j_k \text{ are distinct} \} \le \prod_{i=0}^{k-1} \exp\left(-\frac{i}{d}\right) = \exp \left( -\frac{1}{d}\sum_{i=0}^{k-1} i \right) = \exp\left(-\frac{k(k-1)}{2d}\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0d94f2c4c08982b42bf291b534e5a0f9_l3.png "Rendered by QuickLaTeX.com")
![\[\prob \{ \varepsilon \ge 1 \} \ge 1-\prob \{ j_1,\ldots,j_k \text{ are distinct} \\}\ge 1-\exp\left(-\frac{k(k-1)}{2d}\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-45b59a486a3e0a13091f9d0bdaf8f256_l3.png "Rendered by QuickLaTeX.com")
![\[\prob\{\varepsilon \ge 1\} \ge \frac{1}{2} \quad \text{if} \quad d \le \frac{k(k-1)}{2\ln 2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4b662621b3ca4114b44c072547d33135_l3.png "Rendered by QuickLaTeX.com")
 or perhaps a tall matrix
or perhaps a tall matrix  . A sketching matrix is a
. A sketching matrix is a  matrix
matrix  . When multiplied into a high-dimensional vector
. When multiplied into a high-dimensional vector 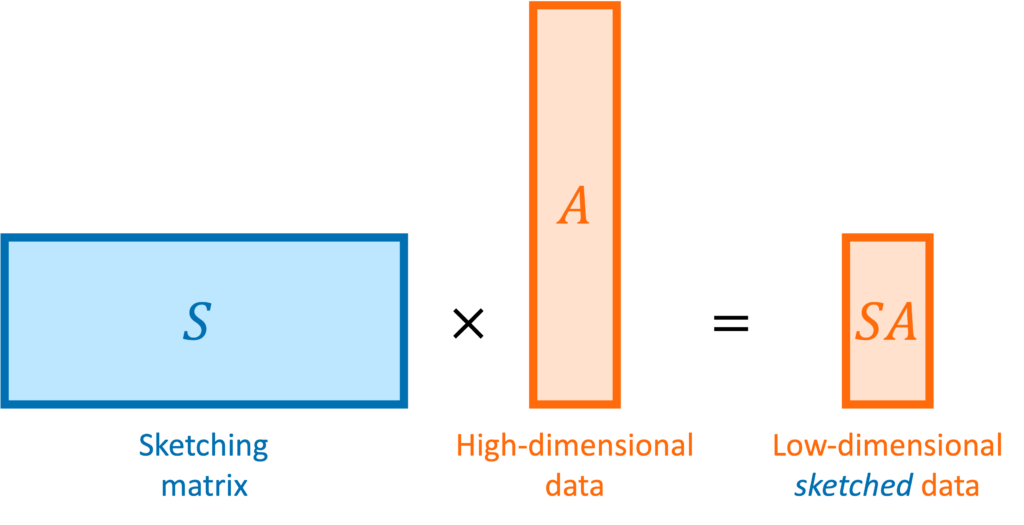
 be a collection of vectors. For
be a collection of vectors. For  , we require that
, we require that  :
: ![\[(1-\varepsilon) \norm{x}\le\norm{Sx}\le(1+\varepsilon)\norm{x} \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cc4b68a1603c32270b2c2e68ad7bc573_l3.png "Rendered by QuickLaTeX.com")
![\[\operatorname{col}(A) \coloneqq \{ Ax : x \in \real^k \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b5b1a6d9d03c0b015432e7cdd42a617d_l3.png "Rendered by QuickLaTeX.com")
 with an output dimension of roughly
with an output dimension of roughly  . In particular, the sketching dimension
. In particular, the sketching dimension  requires roughly
requires roughly  operations, rather than the
operations, rather than the  operations we would expect to multiply a
operations we would expect to multiply a  is
is ![\[S = \sqrt{\frac{n}{d}} \cdot R \cdot F \cdot D.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c5a94a1ac9f7597c1a0d751105604bbe_l3.png "Rendered by QuickLaTeX.com")
 is a diagonal matrix whose entries are each a random
is a diagonal matrix whose entries are each a random  is a fast trigonometric transform such as a fast
is a fast trigonometric transform such as a fast  is a selection matrix. To generate
is a selection matrix. To generate  , let
, let  , selected without replacement.
, selected without replacement.  for every vector
for every vector  and the
and the  , and
, and  operations, a significant improvement over the
operations, a significant improvement over the  , larger than for a Gaussian sketch.
, larger than for a Gaussian sketch.![\[S = \frac{1}{\sqrt{\zeta}} \begin{bmatrix} s_1 & s_2 & \cdots & s_n \end{bmatrix}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cc514af4074faf14379b710b8e2b0a21_l3.png "Rendered by QuickLaTeX.com")
 nonzero entries. The parameter
nonzero entries. The parameter  in practice.
in practice. or
or  operations) to apply to a vector, depending on parameter choices (see below). With a good sparse matrix library, sparse sign embeddings are often the fastest sketching matrix by a wide margin.
operations) to apply to a vector, depending on parameter choices (see below). With a good sparse matrix library, sparse sign embeddings are often the fastest sketching matrix by a wide margin. random numbers, higher than SRTTs (roughly
random numbers, higher than SRTTs (roughly  numbers).
numbers).  ; the theoretically sanctioned sketching dimension (at least according to existing theory) is larger than for a Gaussian sketch. In practice, we can often get away with using
; the theoretically sanctioned sketching dimension (at least according to existing theory) is larger than for a Gaussian sketch. In practice, we can often get away with using  .
. operations. Therefore, sketching offers the promise of speeding up linear algebraic computations involving
operations. Therefore, sketching offers the promise of speeding up linear algebraic computations involving ![\[\operatorname*{minimize}_{x\in\real^k} \norm{Ax - b}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bcfff26e64b8d516a8c0d33dfcb45ee1_l3.png "Rendered by QuickLaTeX.com")
 . Applying
. Applying ![\[\operatorname*{minimize}_{\hat{x}\in\real^k} \norm{(SA)\hat{x} - Sb}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-92ba828310f4ef0dacea49bcd75727ed_l3.png "Rendered by QuickLaTeX.com")
 is the sketch-and-solve solution to the least-squares problem, which we can use as an approximate solution to the original least-squares problem.
is the sketch-and-solve solution to the least-squares problem, which we can use as an approximate solution to the original least-squares problem.
 , first apply sketching to obtain
, first apply sketching to obtain  and then apply an out-of-the-box clustering algorithms like
and then apply an out-of-the-box clustering algorithms like  denote the optimal least-squares solution and let
denote the optimal least-squares solution and let ![\[\norm{A\hat{x} - b} \le \frac{1+\varepsilon}{1-\varepsilon} \norm{Ax - b}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c03f037b5206dd786bd8b4c179d3c789_l3.png "Rendered by QuickLaTeX.com")
 , then this bound tells us that
, then this bound tells us that ![\[\norm{A\hat{x} - b} \le 2\norm{Ax_\star - b}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6ad93cba2f8e5dfec4b865e8b94dd39e_l3.png "Rendered by QuickLaTeX.com")
 . For such applications, the bound (4) ensures that
. For such applications, the bound (4) ensures that  . Often, this means
. Often, this means  , measuring how close
, measuring how close  and residual norm
and residual norm  ). Then, we generate a sparse sign embedding of dimension
). Then, we generate a sparse sign embedding of dimension  ). Then, we compute the sketch-and-solve solution and, as reference, a “direct” solution by
). Then, we compute the sketch-and-solve solution and, as reference, a “direct” solution by  , close to direct method’s residual norm of
, close to direct method’s residual norm of  . However, the forward error of sketch-and-solve is
. However, the forward error of sketch-and-solve is  nine orders of magnitude larger than the direct method’s forward error of
nine orders of magnitude larger than the direct method’s forward error of  .
. , to decrease the distortion by a factor of ten requires increasing the sketching dimension
, to decrease the distortion by a factor of ten requires increasing the sketching dimension  that we hope will converge at a rapid rate to the true least-squares solution,
that we hope will converge at a rapid rate to the true least-squares solution,  , then
, then  .
.![\[SA = QR,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e8775c0801a1253b7a8822784e7495be_l3.png "Rendered by QuickLaTeX.com")
![\[A^\top A \approx (SA)^\top (SA) = R^\top Q^\top Q R = R^\top R.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-aabb17d9e49992a08c48837c21e8caf2_l3.png "Rendered by QuickLaTeX.com")
 since
since  has orthonormal columns. The conclusion is that
has orthonormal columns. The conclusion is that  .
.
![\[(A^\top A)x = A^\top b. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3e08632dc9739f5394c70af2f2890fe4_l3.png "Rendered by QuickLaTeX.com")
 by
by  in (5) and solving. The resulting solution is
in (5) and solving. The resulting solution is![\[x_0 = R^{-1} (R^{-\top}(A^\top b)).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-005b51f6dd4c033bea707996974d294d_l3.png "Rendered by QuickLaTeX.com")
 will typically not be a good solution to the least-squares problem (2), so we need to iterate. To do so, we’ll try and solve for the error
will typically not be a good solution to the least-squares problem (2), so we need to iterate. To do so, we’ll try and solve for the error  . To derive an equation for the error, subtract
. To derive an equation for the error, subtract  from both sides of the normal equations (5), yielding
from both sides of the normal equations (5), yielding ![\[(A^\top A)(x-x_0) = A^\top (b-Ax_0).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-97a5ef135e29969666e364c48f392167_l3.png "Rendered by QuickLaTeX.com")
 :
: ![\[x\approx x_1 \coloneqq x_0 + R^{-\top}(R^{-1}(A^\top(b-Ax_0))).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f4f205cf644dc7c31027ff4f19c01563_l3.png "Rendered by QuickLaTeX.com")
 , approximate
, approximate  , and obtain a new approximate solution
, and obtain a new approximate solution ![\[x_{i+1} = x_i + R^{-\top}(R^{-1}(A^\top(b-Ax_i))).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-403a2c522b754eabc3f908af0d8b0a9c_l3.png "Rendered by QuickLaTeX.com")
 at every iteration. Later,
at every iteration. Later, 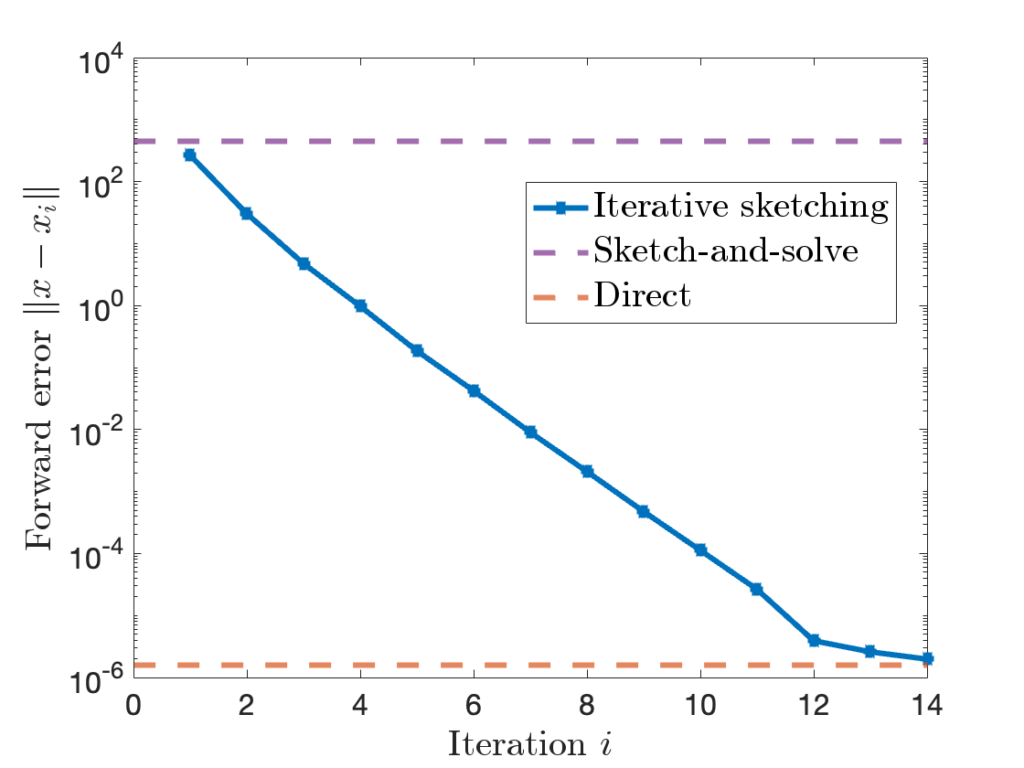
 to
to  can be quite high.
can be quite high.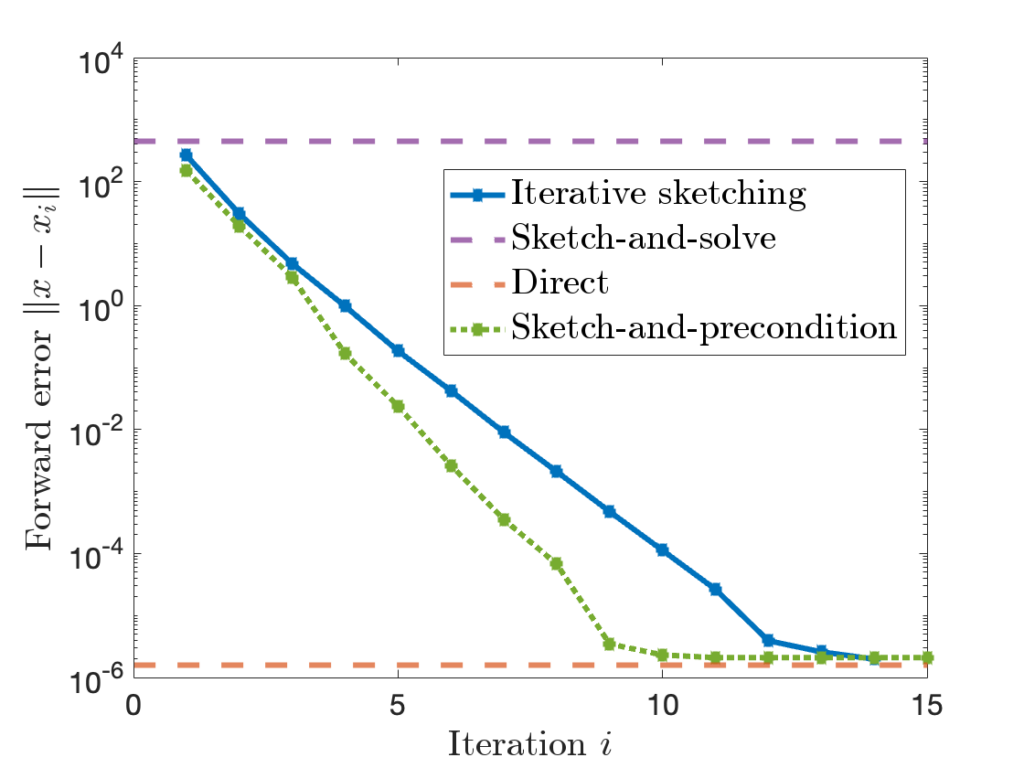
 is comparable to accuracy of a standard
is comparable to accuracy of a standard  , sketch-and-precondition is not forward stable. The maximum achievable accuracy was worse than standard solvers by orders of magnitude! Maybe sketching doesn’t work after all?
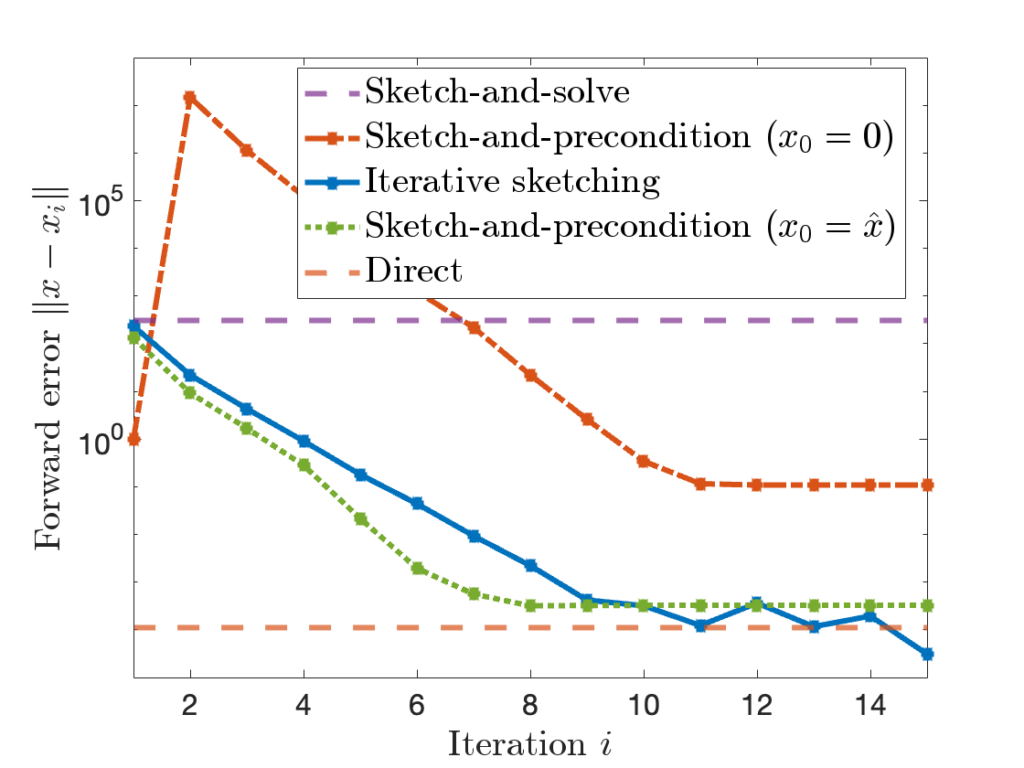
, sketch-and-precondition is not forward stable. The maximum achievable accuracy was worse than standard solvers by orders of magnitude! Maybe sketching doesn’t work after all? for sketch-and-precondition, then sketch-and-precondition appears to be forward stable in practice. No theoretical analysis supporting this finding is known at present.
for sketch-and-precondition, then sketch-and-precondition appears to be forward stable in practice. No theoretical analysis supporting this finding is known at present. and residual
and residual  .
.
![\[\chi^2\left(\rho^{(n)} \, \middle|\middle| \, \pi\right) \le \left( \max \{ \lambda_2, -\lambda_n \} \right)^{2n} \chi^2\left(\rho^{(0)} \, \middle|\middle| \, \pi\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0794ae256af7d3a6568f3a32db1425d4_l3.png "Rendered by QuickLaTeX.com")
 denotes the distribution of the chain at time
denotes the distribution of the chain at time  denotes the
denotes the  denotes the
denotes the 
 denote the decreasingly ordered
denote the decreasingly ordered  . To bound the rate of convergence to stationarity, we therefore must upper bound
. To bound the rate of convergence to stationarity, we therefore must upper bound  and lower bound
and lower bound  .
.
 Fortunately, there is a trick.
Fortunately, there is a trick. for every
for every  , where
, where  denotes the identity matrix. It is easy to see that the stationary distribution
denotes the identity matrix. It is easy to see that the stationary distribution  :
:![\[\pi^\top P^{\rm lazy} = \frac{1}{2} \pi^\top P + \frac{1}{2} \pi^\top I = \frac{1}{2} \pi^\top + \frac{1}{2} \pi^\top = \pi^\top.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a2f70218501ac8392029274508a38325_l3.png "Rendered by QuickLaTeX.com")
![\[\lambda_i^{\rm lazy} = \frac{1+\lambda_i}{2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5e6471392329eadb056e000dd8afb8dc_l3.png "Rendered by QuickLaTeX.com")
 are
are  , all of the eigenvalues of the lazy chain are
, all of the eigenvalues of the lazy chain are  . Thus, the smallest eigenvalue of
. Thus, the smallest eigenvalue of  :
:![\[\chi^2\left(\rho^{(n)} \, \middle|\middle| \, \pi\right) \le \left( \lambda_2^{\rm lazy} \right)^{2n} \chi^2\left(\rho^{(0)} \, \middle|\middle| \, \pi\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d4bf7b37701e17656c6dc56fb9db6968_l3.png "Rendered by QuickLaTeX.com")
 drawn from the stationary distribution:
drawn from the stationary distribution: ![\[\expect_{x\sim \pi} [f(x)] = \sum_{i=1}^m f(i) \pi_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-581b407b8fcaab50b566347ec3362bac_l3.png "Rendered by QuickLaTeX.com")
 of the value of
of the value of  values
values  of the chain
of the chain![\[\hat{f}_{N}\coloneqq \frac{1}{N}\sum_{n=0}^{N-1} f(x_i).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d3abc4798f0fa92356238c58537699ee_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{f}_N = \frac{1}{N}\sum_{n=0}^{N-1} f(x_i)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-35bea8cb17a1bbf5901d464df8d8af9f_l3.png "Rendered by QuickLaTeX.com")
 denote the states of a Markov chain initialized in the stationary distribution
denote the states of a Markov chain initialized in the stationary distribution  . For a large number
. For a large number ![\expect_{x\sim \pi} [f(x)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-67db2fead36b3a187ebf1352cc3e6d99_l3.png "Rendered by QuickLaTeX.com") and variance
and variance  where
where ![\[\sigma^2 = \Var[f(x_0)] + 2\sum_{n=1}^\infty \Cov(f(x_0),f(x_n)). \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9ccb444d1406a56f0f0b9737ab600a34_l3.png "Rendered by QuickLaTeX.com")
 and later values
and later values  . The faster the covariance decreases, the smaller
. The faster the covariance decreases, the smaller  will be and thus the smaller the error for the Markov chain average.
will be and thus the smaller the error for the Markov chain average. ,
, ![\[\frac{\hat{f}_N - \expect_{x \sim \pi} [f(x)]}{\sqrt{N}}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ab0189bb8a43dd6275f74d55a4f8435d_l3.png "Rendered by QuickLaTeX.com")
 be any function.
be any function. that are
that are ![\[\langle \varphi_i,\varphi_j \rangle = \expect_{x\sim \pi} [\varphi_i(x)\varphi_j(x)] = \begin{cases}1, & i = j, \\0, & i \ne j.\end{cases}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5b0557d6e679ed9a7a55768fbb0056ea_l3.png "Rendered by QuickLaTeX.com")
 as defining a function
as defining a function  . Thus, we can expand the function
. Thus, we can expand the function ![\[f = c_1 \varphi_1 + \cdots + c_m \varphi_m. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1474945015cf7c860e9d82fc857138ed_l3.png "Rendered by QuickLaTeX.com")
 is the vector of all ones (or, equivalently, the function that outputs
is the vector of all ones (or, equivalently, the function that outputs  at time
at time  at time
at time  ?
? conditional on the chain starting at
conditional on the chain starting at  :
:![\[(Pf)(i) = \expect[f(x_1) \mid x_0 = i].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-71153b53c3a2d82f9fefb2b12d5ac571_l3.png "Rendered by QuickLaTeX.com")
![\[(P^nf)(i) = \expect[f(x_n) \mid x_0 = i]. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cf635621bbccf0e48e7515a503200684_l3.png "Rendered by QuickLaTeX.com")
 denote a probability distribution which places 100% of the probability mass on the single site
denote a probability distribution which places 100% of the probability mass on the single site  is
is ![\[(P^n f)(i) = \delta_i^\top (P^n f) = (\delta_i^\top P^n) f.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-20220377ddafe66cc15776909cfd314b_l3.png "Rendered by QuickLaTeX.com")
 is the state of the Markov chain after
is the state of the Markov chain after  . Thus,
. Thus,![\[(P^n f)(i) = (\rho^{(n)})^\top f = \sum_{i=1}^m \rho^{(n)}_i f(i) = \expect[f(x_n) \mid x_0=i].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fa79bb9f10b909d68f7fec65cb4fabe9_l3.png "Rendered by QuickLaTeX.com")
 and the spectral decomposition of
and the spectral decomposition of  . Then
. Then![\[\Cov (f(x_0),f(x_n)) = \expect[f(x_0)f(x_n)] - \expect[f(x_0)]\expect[f(x_n)]. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d2cc34b5bf843bf3100a8fd96a7e8981_l3.png "Rendered by QuickLaTeX.com")
![\expect[f(x_0)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d66434b3232c9cf4d99f584f7e6a5f56_l3.png "Rendered by QuickLaTeX.com") and
and ![\expect[f(x_n)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9f1d9f0ed731833ba8fb63cf111c934d_l3.png "Rendered by QuickLaTeX.com") . Since
. Since ![\[\expect[f(x_0)] = \expect[f(x_0) \cdot 1] = \expect[f(x_0) \varphi_1(x_0)] = \langle f, \varphi_1\rangle = c_1.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f1b383454029a1568133d8b33967d41e_l3.png "Rendered by QuickLaTeX.com")
 .
.
 , so we have
, so we have ![\expect[f(x_n)] = \expect[f(x_0)] = c_1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bbc2e6714bd40bb93761105d9cfef194_l3.png "Rendered by QuickLaTeX.com") .
.![\expect[f(x_0)f(x_n)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f9de8b18a1c54f01b4f04947d3673526_l3.png "Rendered by QuickLaTeX.com") . Use the
. Use the ![\begin{align*}\expect[f(x_0)f(x_n)] &= \sum_{i=1}^m \expect[f(x_0) f(x_n) \mid x_0 = i] \prob\{x_0 = i\} \\&= \sum_{i=1}^m f(i) \expect[f(x_n) \mid x_0 = i] \pi_i.\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-013a17b0d26f00edaf30d12b3d16384c_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[f(x_0)f(x_n)] = \sum_{i=1}^m f(i) (P^n f)(i) \pi_i = \langle f, P^n f\rangle.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a042b0079dadaf4cea8b6decfaedae05_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[f(x_0)f(x_n)] = \left\langle \sum_{i=1}^m c_i \varphi_i,\sum_{i=1}^m c_i P^n\varphi_i \right\rangle = \left\langle \sum_{i=1}^m c_i \varphi_i,\sum_{i=1}^m c_i \lambda_i^n \varphi_i \right\rangle = \sum_{i=1}^m \lambda_i^n \, c_i^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1b21004630647911cbda5b4ea80a52a1_l3.png "Rendered by QuickLaTeX.com")
![\expect[f(x_0)] = \expect[f(x_n)] = c_1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5572f912ce7a5f39f9ec42abab4ff888_l3.png "Rendered by QuickLaTeX.com") and plugging into (4), we obtain
and plugging into (4), we obtain![\[\Cov(f(x_0),f(x_n)) = \sum_{i=1}^m \lambda_i^n \, c_i^2 - c_1^2 = \sum_{i=2}^m \lambda_i^n c_i^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b524034278dba4ae25f8a744ac8ed29a_l3.png "Rendered by QuickLaTeX.com")
 , so
, so  entirely drops out of the covariance.
entirely drops out of the covariance.
![\[\Var[f(x_0)] = \Cov(f(x_0),f(x_0)) = \sum_{i=2}^m \lambda_i^0 c_i^2 = \sum_{i=2}^m c_i^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2c926c78d60b0301356f6a26530ecd4d_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*}\sigma^2 &= \Var[f(x_0)] + 2\sum_{n=1}^\infty \Cov(f(x_0),f(x_n)) \\&= \sum_{i=2}^m c_i^2 + 2\sum_{n=1}^\infty \sum_{i=2}^m \lambda_i^n \, c_i^2 \\&= -\sum_{i=2}^m c_i^2 + 2\sum_{i=2}^m \left(\sum_{n=0}^\infty \lambda_i^n\right)c_i^2 .\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0d27501c707dab9d3907b1aaf3b5d6fd_l3.png "Rendered by QuickLaTeX.com")
![\[\sigma^2 = -\sum_{i=2}^m c_i^2 + 2\sum_{i=2}^m \frac{1}{1-\lambda_i} c_i^2 = \sum_{i=2}^m \left(\frac{2}{1-\lambda_i}-1\right)c_i^2 = \sum_{i=2}^m \frac{1+\lambda_i}{1-\lambda_i} c_i^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a4c2db58ce13ec71eb8b021a911dfcf2_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{f}_N = \frac{1}{N} \sum_{i=0}^{N-1} f(x_n)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3b18dba9948ca0bc5101f96f00663218_l3.png "Rendered by QuickLaTeX.com")
![\expect_{x \sim \pi} [f(x)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d6571ed2f0f16fa098b50799de5df7c3_l3.png "Rendered by QuickLaTeX.com") . The Markov chain central limit theorem shows that, for a large number of steps
. The Markov chain central limit theorem shows that, for a large number of steps ![\hat{f}_N - \expect_{x\sim\pi}[f(x)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5e166c7df3e7d2b704ef9138fe8cd0dc_l3.png "Rendered by QuickLaTeX.com") is approximately normally distributioned with mean zero and variance
is approximately normally distributioned with mean zero and variance  of the transition matrix
of the transition matrix  . Thus, we have
. Thus, we have
 of an eigenvalue
of an eigenvalue  is scaled by in
is scaled by in  for the corresponding eigenvalue
for the corresponding eigenvalue  of the lazy chain. We see that at every
of the lazy chain. We see that at every  value, the lazy chain has a higher amplification factor than the original chain.
value, the lazy chain has a higher amplification factor than the original chain.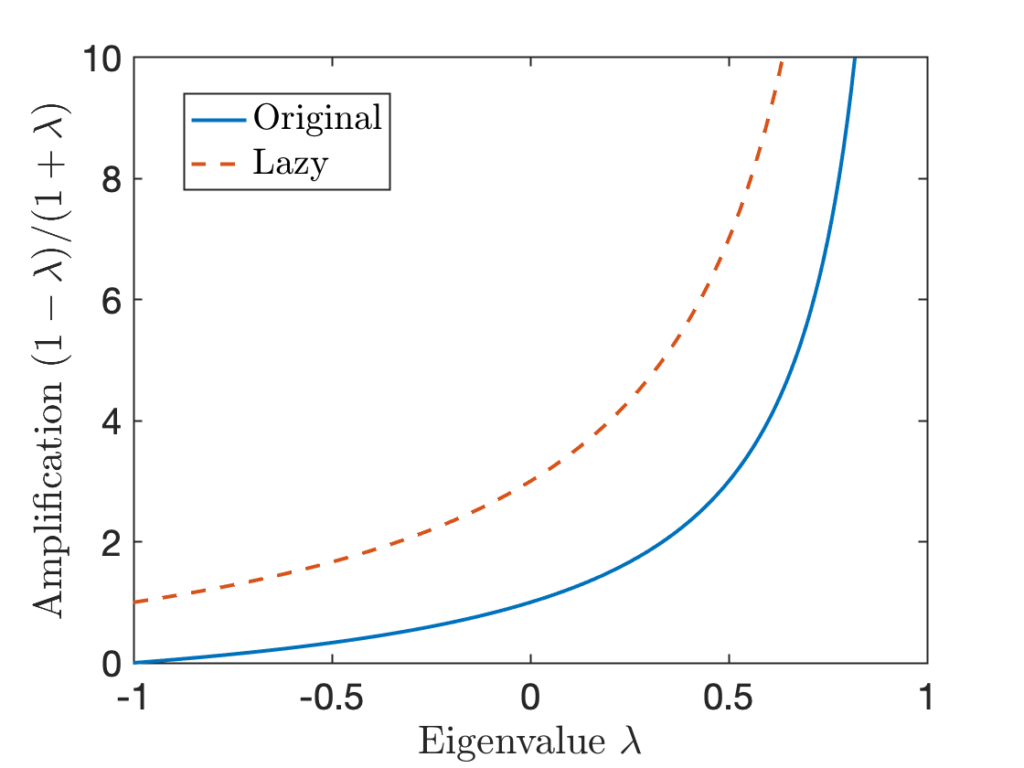
 with transition probability matrix
with transition probability matrix  and
and  and functions
and functions  as being one and the same, and we will use both
as being one and the same, and we will use both  and
and  to denote the
to denote the  with a numeric value.
with a numeric value.![\expect[f]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cbb1e9c87522270e46960ae18e413f5e_l3.png "Rendered by QuickLaTeX.com") denote the
denote the  where
where ![\[\expect[f] \coloneqq \expect_{X \sim \pi} [f(X)] = \sum_{i=1}^m \pi_i f(i).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-12ae5e7aed4bc6bbd81b6a5551acee16_l3.png "Rendered by QuickLaTeX.com")
![\[\Var(f) \coloneqq \expect [(f - \expect[f])^2] = \sum_{i=1}^m (f(i) - \expect[f])^2 \pi_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-14ae996585596c6de32cf35bda0592d7_l3.png "Rendered by QuickLaTeX.com")
 denote a probability distribution which assigns 100% probability to outcome
denote a probability distribution which assigns 100% probability to outcome  matrix with real entries
matrix with real entries  ) has
) has  .
. . Let’s first ask: What does the transpose
. Let’s first ask: What does the transpose  is equipped with the
is equipped with the  and it is defined as
and it is defined as![\[(f,g) \coloneqq f^\top g = \sum_{i=1}^m f(i) g(i).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0326a3a86a3eab2ed1f53ac63d689f35_l3.png "Rendered by QuickLaTeX.com")
![\[(f,Ag) = (A^\top f, g)\quad \text{for every }f,g\in\real^m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-830c5c58b2f61f8592d7c05c83e8b5e7_l3.png "Rendered by QuickLaTeX.com")
 is the same as the amount of
is the same as the amount of  in the direction of
in the direction of ![[\cdot,\cdot]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-17c4eaa9ec5d2cc57ecd5eb82d7f4509_l3.png "Rendered by QuickLaTeX.com") be any inner product on
be any inner product on  such that
such that ![\[[f,Ag]=[A^*f,g]\quad\text{for every }f,g\in\real^m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c74d765399ae7f102ae9d3193386b68f_l3.png "Rendered by QuickLaTeX.com")
 .
.![\[[u_i,u_j]=\begin{cases}1, & i=j, \\0,& i\ne j.\end{cases}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-10fa1af31befb8facdc2cc589ce8ba3a_l3.png "Rendered by QuickLaTeX.com")
![\[\langle f, g \rangle \coloneqq \expect[f\cdot g] = \sum_{i=1}^m f(i)g(i) \pi_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9bf54f44a70cf121fff63df5b636405a_l3.png "Rendered by QuickLaTeX.com")
![\expect[f] = \expect[g] = 0](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c3e5aa24c2520cd178b757331cd8ba65_l3.png "Rendered by QuickLaTeX.com") ), it reports the
), it reports the  where
where  is drawn from
is drawn from  :
:
![\[\pi_i P_{ij} = \pi_j P_{ji} \quad \text{for } i,j=1,2,\ldots,m\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0d0a61321eb0ac824f91654da65a02ec_l3.png "Rendered by QuickLaTeX.com")
![\[\langle f, Pg \rangle= \sum_{i,j=1}^m f(i) g(j) \pi_jP_{ji} = \sum_{j=1}^m \left( \sum_{i=1}^m f(i) P_{ij} \right) g(j) \pi_j = \langle Pf, g\rangle.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1c6b2a786ba6f196e92f5abb4c1b65df_l3.png "Rendered by QuickLaTeX.com")
 associated with eigenvectors
associated with eigenvectors  which are orthonormal in the
which are orthonormal in the ![\[\langle\varphi_i,\varphi_j\rangle=\begin{cases}1, &i=j\\0,& i\ne j.\end{cases}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-90f85597aa067ac50d1192836c3021bb_l3.png "Rendered by QuickLaTeX.com")
 span all of
span all of  converges to
converges to  for every
for every  . Thus, since
. Thus, since  for every vector
for every vector  in magnitude.
in magnitude. is a vector of all one’s.
is a vector of all one’s. have magnitude
have magnitude  .
. for every
for every  .
. and
and ![\[\norm{\sigma - \pi}_{\rm TV} = \max_{A \subseteq \{1,\ldots,m\}} |\sigma(A) - \pi(A)| = \frac{1}{2} \sum_{i=1}^m |\sigma_i - \pi_i|.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9ff5c3589b0cf437e53b4911648c8465_l3.png "Rendered by QuickLaTeX.com")

 and
and  of each outcome. Spectral theory plays more nicely with an “
of each outcome. Spectral theory plays more nicely with an “ ” way of comparing probability distributions, which we develop now.
” way of comparing probability distributions, which we develop now. . This provides a general way of figuring out which objects for finite state space Markov chains are row vectors and which are column vectors: Measures are row vectors whereas functions are column vectors.
. This provides a general way of figuring out which objects for finite state space Markov chains are row vectors and which are column vectors: Measures are row vectors whereas functions are column vectors. given by
given by![\[h(i) = \frac{d\sigma}{d\pi}(i) = \frac{\sigma_i}{\pi_i} \quad \text{for } i=1,2,\ldots,m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-efe9d6570613f351438de0047c2005b3_l3.png "Rendered by QuickLaTeX.com")
![\[\expect_{X \sim \sigma} [g(X)] = \expect_{Y \sim \pi}[g(Y)h(Y)] = \sum_{i=1}^m g(i)h(i) \pi_i. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d7323cb723f0ae19b06f80667acb9e2a_l3.png "Rendered by QuickLaTeX.com")
 is a random variable with distribution
is a random variable with distribution ![\mathrm{Unif}[0,1]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-06841890a0a03602236d857293fe3eb4_l3.png "Rendered by QuickLaTeX.com") ) is a function
) is a function ![\[\expect_{X \sim \sigma} [g(X)] = \expect_{Y\sim \mathrm{Unif}[0,1]} [g(Y)h(Y)] = \int_0^1 g(x) h(x) \, dx.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e5d96baf80eb9a08416cac0f029fe78c_l3.png "Rendered by QuickLaTeX.com")
 replaced with integrals
replaced with integrals  .
.
![\[\chi^2(\sigma \mid\mid \pi) \coloneqq \Var \left(\frac{d\sigma}{d\pi} \right) = \expect \left[\left( \frac{d\sigma}{d\pi} - 1 \right)^2\right] = \expect \left[\left(\frac{d\sigma}{d\pi}\right)^2\right] - 1.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3f09c3bef84c0b3d334e8d7303d2060e_l3.png "Rendered by QuickLaTeX.com")
 , note that
, note that![\[\expect\left[\frac{d\sigma}{d\pi}\right] = \sum_{i=1}^m \frac{d\sigma}{d\pi}(i) \pi_i = \sum_{i=1}^m \frac{\sigma_i}{\pi_i} \pi_i = \sum_{i=1}^m \sigma_i = 1. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2932e6c18d6b5501f6bef7af65f0c03f_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\sigma - \pi}_{\rm TV} = \frac{1}{2} \expect \left[ \left| \frac{d\sigma}{d\pi} - 1 \right| \right].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bcfc0ba006214a27603b1e8ac8c03e8a_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\sigma - \pi}_{\rm TV} = \frac{1}{2} \expect \left[ \left| \frac{d\sigma}{d\pi} - 1 \right| \right] \le \frac{1}{2} \left(\expect \left[ \left( \frac{d\sigma}{d\pi} - 1 \right)^2 \right]\right)^{1/2} = \frac{1}{2} \sqrt{\chi^2(\sigma \mid\mid \pi)}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-89d273ad59841a54bbdb88388ec7a7f4_l3.png "Rendered by QuickLaTeX.com")
 denote the distributions of the Markov chain at times
denote the distributions of the Markov chain at times  . Then
. Then and
and  ,
, ![\[\chi^2(\delta_i \mid\mid \pi) \le \frac{1}{\pi_i}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e5da01bb469f7166c9c9b8d87e87e2fe_l3.png "Rendered by QuickLaTeX.com")
![\[\chi^2\left( \rho^{(0)} \, \middle|\middle| \, \pi \right) \le \frac{1}{\min_{1\le i\le m} \pi_i} \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-56d0779ff9daa032453593faa90dbe0c_l3.png "Rendered by QuickLaTeX.com")
![\[\chi^2(\delta_i \mid\mid \pi) = \Var(d\delta_i/d\pi) \le \expect[(d\delta_i/d\pi)^2] = 1/\pi_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-be46cae36b56d89606398f3245b1d038_l3.png "Rendered by QuickLaTeX.com")
 is a
is a  for some
for some ![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le \varepsilon\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0265093609a1b549d141134d29077abf_l3.png "Rendered by QuickLaTeX.com")
![\[n = \left\lceil \frac{1}{\log(\max\{\lambda_2,-\lambda_n\})}\log \left( \frac{1}{2\varepsilon \min_{1\le i \le m}\sqrt{\pi_i}} \right) \right\rceil \text{ steps}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fb115afced0673978450c77cbfef5188_l3.png "Rendered by QuickLaTeX.com")

 . To do this, we use the recurrence for the probability distribution:
. To do this, we use the recurrence for the probability distribution:![\[\rho^{(n+1)}_j = \sum_{i=1}^m \rho_i^{(n)} P_{ij}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0aaa12011f9fb3501f47141288c3dcdc_l3.png "Rendered by QuickLaTeX.com")
![\[\left( \frac{d\rho^{(n+1)}}{d\pi}\right)_j = \frac{\rho_j^{(n+1)}}{\pi_j} = \frac{\sum_{i=1}^m \rho^{(n)}_i P_{ij}}{\pi_j}= \sum_{i=1}^m \rho^{(n)}_i\frac{P_{ij}}{\pi_j}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f1b743fe6c6f919a5d608930191c2680_l3.png "Rendered by QuickLaTeX.com")
 , which implies
, which implies![\[\left( \frac{d\rho^{(n+1)}}{d\pi}\right)_j = \sum_{i=1}^m\rho^{(n)}_i \frac{P_{ji}}{\pi_i} = \sum_{i=1}^m P_{ji} \frac{\rho^{(n)}_i}{\pi_i} = \left( P \frac{d \rho^{(n)}}{d\pi} \right)_j.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d2b9f29a6ec2c9ecfc1f3b8b9cc35e25_l3.png "Rendered by QuickLaTeX.com")
 is an ordinary
is an ordinary ![\[\frac{d\rho^{(n+1)}}{d\pi} = P \frac{d\rho^{(n)}}{d\pi} \quad \text{for } n =0,1,\ldots. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2ab5f31342640b6aba7fb6ed3670d07b_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{d\rho^{(0)}}{d\pi} = c_1 \mathbf{1} + c_2 \varphi_2 + \cdots + c_m \varphi_m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7c1e32629808ff2980ccc23b2358e447_l3.png "Rendered by QuickLaTeX.com")
![\expect[d\rho^{(0)}/d\pi] = 1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7aa5e037db3762a1c1fd5fecb4d987c8_l3.png "Rendered by QuickLaTeX.com") . Thus, we conclude
. Thus, we conclude  . Since the
. Since the  are eigenvectors of
are eigenvectors of  , the recurrence (7) implies
, the recurrence (7) implies![\[\frac{d\rho^{(n)}}{d\pi} = \mathbf{1} + c_2 \lambda_2^n \varphi_2 + \cdots + c_m \lambda_m^n \varphi_m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4aad2f567930a8530ae08c2489213718_l3.png "Rendered by QuickLaTeX.com")
![\[\chi^2(\rho^{(n)} \mid\mid \pi) = \sum_{i=2}^m c_i^2 \lambda_i^{2n} \le (\max \{ \lambda_2, -\lambda_m \})^{2n} \sum_{i=2}^m c_i^2 = (\max \{ \lambda_2, -\lambda_m \})^{2n} \chi^2(\rho^{(0)} \mid\mid \pi).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c5a236cf94253b8b6d6531f5b631f2d0_l3.png "Rendered by QuickLaTeX.com")
![\[\tau_{\rm mix} \coloneqq \min \left\{ n \ge 1 : \max_{\rho^{(0)}} \norm{\rho^{(n)} - \pi}_{\rm TV} \le \frac{1}{2e} \right\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b113a1282ec6482365ff8d864c452020_l3.png "Rendered by QuickLaTeX.com")
 of the chain at time
of the chain at time  is the
is the ![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le e^{-\lfloor n / \tau_{\rm mix}\rfloor}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-46dcfd14933771d53054517213b42af3_l3.png "Rendered by QuickLaTeX.com")
 , then
, then  .
. .
. such that (A) each process is individually a Markov chain with transition matrix
such that (A) each process is individually a Markov chain with transition matrix ![\[\prob\{x_{n+1} = j \mid x_n = i \} = \prob\{y_{n+1} = j \mid y_n = i \} = P_{ij}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ecf2dc14cf5c77a7a3fa86e776c06307_l3.png "Rendered by QuickLaTeX.com")
 , then
, then  .
. and
and  is initialized in the stationary distribution
is initialized in the stationary distribution  . Let
. Let  be the time at which
be the time at which ![\[\tau_{\rho^{(0)}} \coloneqq \min\{ n \ge 0 : x_n = y_n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0df481cdd2a2b70ed3b4c6465a1a8029_l3.png "Rendered by QuickLaTeX.com")
 control the convergence of the Markov chain
control the convergence of the Markov chain  .
.![\tau_{\rm mix} \le 2e \max_{\rho^{(0)}} \expect[\tau_{\rho^{(0)}}]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9f694166ecea61359b557b46b36cccca_l3.png "Rendered by QuickLaTeX.com") .
.![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le \prob\{\tau_{\rho^{(0)}} > n\}\le \frac{\expect[\tau_{\rho^{(0)}}]}{n}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-714fbccb7821cffd4d7ca081e377bad5_l3.png "Rendered by QuickLaTeX.com")
 . Then the left-hand side is at most
. Then the left-hand side is at most  , so
, so![\[\frac{1}{2e} \le \max_{\rho^{(0)}}\norm{\rho^{(\tau_{\rm mix})} - \pi}_{\rm TV} = \prob\{\tau_{\rho^{(0)}} > n\} \le \frac{\max_{\rho^{(0)}}\expect[\tau_{\rho^{(0)}}]}{\tau_{\rm mix}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f11d19a7019c09955620afe79a616798_l3.png "Rendered by QuickLaTeX.com")
 ). Therefore, one can also think of this Markov chain as a very inefficient way of generating a string of random bits.
). Therefore, one can also think of this Markov chain as a very inefficient way of generating a string of random bits. and a (uniform) random bit
and a (uniform) random bit  . Set
. Set  by changing the
by changing the  th bit of
th bit of  , and set
, and set  by changing the
by changing the  to
to  have been chosen by time
have been chosen by time  to be the time at which all positions
to be the time at which all positions ![\[\tau_{\rho^{(0)}} \le \tau_{\rm pick}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5b3a01a539c1722e08e4e8d0cd8bbad9_l3.png "Rendered by QuickLaTeX.com")
![\expect[\tau_{\rm pick}]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-219b553c55a7c9bd3e9c54d093dd4d5f_l3.png "Rendered by QuickLaTeX.com") , it can be helpful to break into easier pieces. Let’s start with the simplest possible question: How many picks do we need to collect the first coupon? Just one. We always get a coupon in our first box.
, it can be helpful to break into easier pieces. Let’s start with the simplest possible question: How many picks do we need to collect the first coupon? Just one. We always get a coupon in our first box. of them are different from the first. So the probability of picking a new coupon in the second box is
of them are different from the first. So the probability of picking a new coupon in the second box is  . In fact,
. In fact, , and its mean is
, and its mean is  . On average, we need
. On average, we need  picks to collect the second coupon.
picks to collect the second coupon. coupons we haven’t collected and
coupons we haven’t collected and  . Thus, the number of picks is a geometric random variable with success probability
. Thus, the number of picks is a geometric random variable with success probability  .
. picks to pick the
picks to pick the  , we obtain that the total number of picks required is to collect all the coupons is
, we obtain that the total number of picks required is to collect all the coupons is![\[\expect[\tau_{\rm pick}] = 1 + \frac{N}{N-1} + \frac{N}{N-2} + \cdots + \frac{N}{N-(N-1)} = N \left( \frac{1}{N} + \frac{1}{N-1} + \cdots + \frac{1}{2} + 1 \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a2fb962d7fa0ba242bc45e3920fe4eda_l3.png "Rendered by QuickLaTeX.com")
 denote the
denote the ![\[H_N = 1 + \frac{1}{2} + \cdots + \frac{1}{N}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-681ceb38097f36e5c2c1065f2c210153_l3.png "Rendered by QuickLaTeX.com")
![\expect[\tau_{\rm pick}] = NH_N](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-dc3b95575279b77c40894610fa83f46c_l3.png "Rendered by QuickLaTeX.com") . Since the
. Since the  , we have
, we have![\[\expect[\tau_{\rm pick}] \le N \log (N) + N.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3b66139144a4ae9829de07283a68fc50_l3.png "Rendered by QuickLaTeX.com")
![\[\tau_{\rm mix} \le 2e \, \expect[\tau_{\rho^{(0)}}] \le 2e \, \expect[\tau_{\rm pick}] \le 2e \, N \log(N) + 2e \, N.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-db68ef63468db6e700de2ccc40bd5763_l3.png "Rendered by QuickLaTeX.com")
 .
.
![\[\prob\{\tau_{\rm pick} > N \log N + cN\} \le e^{-c}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5fb5a001f8a261a6d566b91d0565e630_l3.png "Rendered by QuickLaTeX.com")
 and
and  , from which it follows that
, from which it follows that![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le \varepsilon \quad \text{provided that} \quad n \ge N \log N + N \log(1/\varepsilon).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c1281930113936226338f62949cbc8be_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le \varepsilon \quad \text{provided that} \quad n \ge \frac{1}{2} N \log N + c \,N \log(1/\varepsilon)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4119ef2fd21bd99bbbaefc6513c74705_l3.png "Rendered by QuickLaTeX.com")
 . The constant
. The constant  in this inequality cannot be improved. See section 5.3.1 of
in this inequality cannot be improved. See section 5.3.1 of  . When initialized from any starting distribution
. When initialized from any starting distribution  if all of its entries are strictly positive. Recall that a Markov chain with transition matrix
if all of its entries are strictly positive. Recall that a Markov chain with transition matrix  . For this post, all Markov chains will have state space
. For this post, all Markov chains will have state space ![\[\norm{\rho - \sigma}_{\rm TV} = \max_{S \subseteq \{1,\ldots,m\}} |\rho(S) - \sigma(S)| = \frac{1}{2} \sum_{i=1}^m \left| \rho_i - \sigma_i \right|.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-58877ea5c31eeccd6053edb0cbed6568_l3.png "Rendered by QuickLaTeX.com")
 .
. . Thus, despite these distributions seeming quite similar to us, the total variation distance between
. Thus, despite these distributions seeming quite similar to us, the total variation distance between  , if
, if![\[\prob \{x = i\} = \rho_i \quad \text{for $i=1,2,\ldots,m$}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7565daa9870bbf83fd46fb566bfca2d8_l3.png "Rendered by QuickLaTeX.com")
 on
on  such that if a pair of random variables
such that if a pair of random variables  is drawn from
is drawn from  . Denote the set of all couplings of
. Denote the set of all couplings of  .
.![\[\norm{\rho - \sigma}_{\rm TV} = \min_{\gamma \in \operatorname{Couplings}(\rho,\sigma)} \prob_{(x,y) \sim \gamma} \{ x \ne y \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4b17b71b4686a53ba061fa9c0c8bccbe_l3.png "Rendered by QuickLaTeX.com")
 represents the probability for variables
represents the probability for variables  drawn from joint distribution
drawn from joint distribution  . Then the coupling lemma tells us that there is a coupling
. Then the coupling lemma tells us that there is a coupling  . Indeed, such a coupling can be obtained by drawing
. Indeed, such a coupling can be obtained by drawing  . This defines a joint distribution
. This defines a joint distribution  with 100% probability.
with 100% probability. ,
, ![\[\norm{\rho - \sigma}_{\rm TV} \le \prob \{x \ne y \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b60e0e5766b4d0df4a7d65afa3f0d992_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho - \sigma}_{\rm TV} = \prob \{x \ne y\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3c59407e0bf4b8fedccce9a21d8af350_l3.png "Rendered by QuickLaTeX.com")
 as
as  at an exponential rate.
at an exponential rate. is non-increasing
is non-increasing ![\[\norm{\rho^{(n+1)} - \pi}_{\rm TV} \le \norm{\rho^{(n)} - \pi}_{\rm TV} \quad \text{for every } n =0,1,2\ldots. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1b5ae27ef4ee43697f2398624ee3be8e_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho^{(n)} - \pi}_{\rm TV} = \prob \{x_n\ne y_n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6e05880c0fe257457b7f56a387b88876_l3.png "Rendered by QuickLaTeX.com")
 .
. , then run the two chains
, then run the two chains ![\[\prob\{x_{n+1}\ne y_{n+1}\} \le \prob\{x_n \ne y_n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-814352aaaad7a9fbc0b4f3c5eb822613_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho^{(n+1)} - \pi}_{\rm TV} \le \prob\{x_{n+1}\ne y_{n+1}\} \le \prob\{x_n \ne y_n\} = \norm{\rho^{(n)} - \pi}_{\rm TV}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8f56f9a288668e13c91be92c6e752226_l3.png "Rendered by QuickLaTeX.com")
 .
. more carefully. Write it as
more carefully. Write it as
 , break into cases for all possible values
, break into cases for all possible values  for
for  to take
to take 
 be the minimum probability of moving between any two states
be the minimum probability of moving between any two states![\[p_{\rm min} \coloneqq \min_{1\le i,j\le m} P_{ij}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-68a998d97674a3ec8aa696cb11b7c6af_l3.png "Rendered by QuickLaTeX.com")
 to
to 
![\[\prob \{x_{n+1} \ne y_{n+1}\} \le (1 - p_{\rm min})\prob \{x_n \ne y_n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-78d293b83c6753dccca02b89b455d959_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho^{(n+1)}-\pi}_{\rm TV} \le \prob \{x_{n+1} \ne y_{n+1}\} \le (1 - p_{\rm min})\prob \{x_n \ne y_n\} = (1 - p_{\rm min}) \norm{\rho^{(n)} - \pi}_{\rm TV}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b68167c8dbcfc823d7ff91216becd632_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le (1 - p_{\rm min})^n \norm{\rho^{(0)} - \pi}_{\rm TV} \le (1 - p_{\rm min})^n.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-59e6f7ff5d0e041c577eb7ed5532adcd_l3.png "Rendered by QuickLaTeX.com")
 . Fortunately, together with our earlier observation that distance to stationarity is non-increasing, we can upgrade this proof into a proof for the general case.
. Fortunately, together with our earlier observation that distance to stationarity is non-increasing, we can upgrade this proof into a proof for the general case. for which
for which  . Construct an auxilliary Markov chain
. Construct an auxilliary Markov chain  such that one step of the auxilliary chain consists of running
such that one step of the auxilliary chain consists of running ![\[z_0 = x_0, \:z_1 = x_{n_0}, \:z_2 = x_{2n_0},\ldots.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c6b0273a5b22a30c655addd81517c287_l3.png "Rendered by QuickLaTeX.com")
 is
is  , we have
, we have![\[\norm{\rho^{(k\cdot n_0)} - \pi}_{\rm TV} \le (1-\delta)^k \norm{\rho^{(0)} - \pi}_{\rm TV} \le (1-\delta)^k \quad \text{for }k=0,1,2,\ldots,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8dc7e93bb5af185f602d9eadd3372cbf_l3.png "Rendered by QuickLaTeX.com")
 . Thus, since distance to stationarity is non-increasing, we have
. Thus, since distance to stationarity is non-increasing, we have![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le \norm{\rho^{(n_0 \cdot \lfloor n/n_0\rfloor)} - \pi}_{\rm TV} \le (1-\delta)^{\lfloor n/n_0\rfloor} \norm{\rho^{(0)} - \pi}_{\rm TV} \le (1-\delta)^{\lfloor n/n_0\rfloor}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9c26eb887b7b0b2884be1d636e7e88da_l3.png "Rendered by QuickLaTeX.com")
![\[\tau_{\rm mix} \coloneqq \min \left\{ n \ge 1 : \max_{\rho^{(0)}} \norm{\rho^{(n)} - \pi}_{\rm TV} \le \frac{1}{2e} \right\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d19e6587cede63b1f01ae3512c569760_l3.png "Rendered by QuickLaTeX.com")
 steps:
steps: , then
, then  be the expected number of times the chain hits
be the expected number of times the chain hits  . Because the chain is primitive, all of the
. Because the chain is primitive, all of the ![\[\pi_i = \frac{a_i}{\sum_{j=1}^m a_j}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-225852bc17bde57aae1b213a6d0f5254_l3.png "Rendered by QuickLaTeX.com")
![\[a^\top P = a^\top. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-70f92aabf9d6aab8582cd7bd6d6e5376_l3.png "Rendered by QuickLaTeX.com")
 denote the values of the chain and
denote the values of the chain and  denote the time at which the chain returns to
denote the time at which the chain returns to ![\[a_j = \sum_{n=1}^\infty \prob\{x_n = j, n_{\rm ret} > n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-659adc2db7f6f375e48bc49831206001_l3.png "Rendered by QuickLaTeX.com")
![\[a_j = \prob\{x_1 = j\} + \sum_{n=2}^\infty \prob\{x_n = j, n_{\rm ret} > n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-432f1991305a7be83aaa8b645e8903d8_l3.png "Rendered by QuickLaTeX.com")
 . For the second term, break into cases depending on the value of the chain at time
. For the second term, break into cases depending on the value of the chain at time 
![\[a_j = P_{ij} + \sum_{n=2}^\infty \sum_{k\ne i} \prob\{x_{n-1} = k, n_{\rm ret} > n-1 \} P_{kj}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-499edcb2f37d7a81e5cb5ee1c3901c2c_l3.png "Rendered by QuickLaTeX.com")
 to
to  and exchange the order of summation to obtain
and exchange the order of summation to obtain![\[a_j = P_{ij} + \sum_{k\ne i} \left(\sum_{n=1}^\infty \prob\{x_n = k, n_{\rm ret} > n \}\right) P_{kj}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-744016bb42586d11410b2316a6f9c495_l3.png "Rendered by QuickLaTeX.com")
 . Thus, since
. Thus, since  , we have
, we have![\[a_j = a_iP_{ij} + \sum_{k\ne i} a_k P_{kj} = \sum_{k=1}^m a_k P_{kj},\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-88622d7f9fed657f8d72d912be2de7f1_l3.png "Rendered by QuickLaTeX.com")