In the previous posts, we’ve been using eigenvalues to understand the mixing of reversible Markov chains. Our main convergence result was as follows:
![\[\chi^2\left(\rho^{(n)} \, \middle|\middle| \, \pi\right) \le \left( \max \{ \lambda_2, -\lambda_n \} \right)^{2n} \chi^2\left(\rho^{(0)} \, \middle|\middle| \, \pi\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4083a8792e3728ec282c234e8714a3e0_l3.png "Rendered by QuickLaTeX.com")
 denotes the distribution of the chain at time
denotes the distribution of the chain at time  ,
,  denotes the stationary distribution,
denotes the stationary distribution,  denotes the
denotes the  divergence, and
divergence, and  denote the decreasingly ordered eigenvalues of the Markov transition matrix
denote the decreasingly ordered eigenvalues of the Markov transition matrix  .
.
Bounding the the rate of convergence requires an upper bound on  and a lower bound on
and a lower bound on  . In this post, we will talk about techniques for bounding . For more on the smallest eigenvalue , see the previous post.
. In this post, we will talk about techniques for bounding . For more on the smallest eigenvalue , see the previous post.
Setting
Let’s begin by establishing some notation, mostly the same as previous posts as this series. We work with a reversible Markov chain with transition matrix and stationary distribution .
As in previous posts, we identify vectors  and functions
and functions  , treating them as one and the same
, treating them as one and the same  .
.
For a vector/function  ,
, ![\expect_\pi[f]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5bf080ed72a8c1f4965ae7500b95d55e_l3.png "Rendered by QuickLaTeX.com") and
and  denote the variance with respect to the stationary distribution :
denote the variance with respect to the stationary distribution :
![\[\expect_\pi[f] = \sum_{i=1}^m f(i) \pi_i, \quad \Var_\pi(f) \coloneqq \expect_\pi[(f-\expect_\pi[f])^2].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-140e8451d7640ea23691bc6e0ac79296_l3.png "Rendered by QuickLaTeX.com")
-inner product ![\[\langle f, g\rangle \coloneqq \expect_\pi[f\cdot g] = \sum_{i=1}^m f(i) g(i) \pi_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-429786c5a31567611cd2b34a899b00c7_l3.png "Rendered by QuickLaTeX.com")
We shall also use expressions such as
![\expect_{x \sim \sigma, y\sim \tau} [f(x,y)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c2a42f5e811f88ddfb5da1a1164bd034_l3.png "Rendered by QuickLaTeX.com") to denote the expectation of
to denote the expectation of  where
where  is drawn from distribution
is drawn from distribution  and
and  is drawn from
is drawn from  .
.
We denote the eigenvalues of the transition matrix are . The associated eigenvectors (eigenfunctions)  are orthonormal in the -inner product
are orthonormal in the -inner product
![\[\langle \varphi_i ,\varphi_j\rangle = \begin{cases}1, & i = j, \\0, & i \ne j.\end{cases}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1bcdaefcfb18b68324fe7793e2cb3534_l3.png "Rendered by QuickLaTeX.com")
Variance and Local Variance
To discover methods for bounding , we begin by investigating a seemingly simple question:
How much variable is the output of a function
There are two natural quantities which provide answers to this question: the variance and the local variance. Poincaré inequalities—the main subject of this post—establish a relation between these two numbers. As a consequence, Poincaré inequalities will provide a bound on .
Variance
We begin with the first of our two main characters, the variance . The variance is a very familiar measure of variation, as it is defined for any random variable. It measures the average squared deviation of  from its mean, where is drawn from the stationary distribution .
from its mean, where is drawn from the stationary distribution .
Another helpful formula for the variance is the exchangeable pairs formula:
![\[\Var_\pi(f) = \frac{1}{2} \expect_{x,y \sim \pi} [(f(x) - f(y))^2].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-63885f39b045d90e13763469722ab480_l3.png "Rendered by QuickLaTeX.com")
is proportional to the average square difference of ‘s values when measured at locations and sampled (independently) from the stationary distribution .
Local Variance
The exchangeable pairs formula shows that variance is a measure of the global variability of the function: It measures the amount varies across locations and sampled randomly from the entire set of possible states  .
.
The local variance measures how much varies between points and which are separated by just one step of the Markov chain, thus providing a more local measure of variability. Let  be sampled from the stationary distribution, and let
be sampled from the stationary distribution, and let  denote one step of the Markov chain after
denote one step of the Markov chain after  . The local variance is
. The local variance is
![\[\mathcal{E}(f) = \frac{1}{2} \expect [(f(x_0) - f(x_1))^2].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a1f334058762ab02c87e271c2c92bc47_l3.png "Rendered by QuickLaTeX.com")
An important note: The variance of a function depends only on the stationary distribution . By contrast, the local variance depends on the Markov transition matrix .
Poincaré Inequalities
If does not vary much over a single step of the Markov chain, then it seems reasonable to expect that it doesn’t vary much globally. This intuition is made quantitative using Poincaré inequalities.
Definition (Poincaré inequality). A Markov chain is said to satisfy a Poincaré inequality with constant
if
(1)
![\[\Var_\pi(f)\le \alpha \cdot \mathcal{E}(f) \quad \text{for every function } f.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5e8793ac1bfab318d0a5010d48b2dbcf_l3.png "Rendered by QuickLaTeX.com")
Poincaré Inequalities and Mixing
Poincaré inequalities are intimately related with the speed of mixing for a Markov chain.
To see why, consider a function with small local variance. Because has small local variance,  is close to
is close to  , is close to
, is close to  , etc.; the function does not change much over a single step of the Markov chain. Does this mean that the (global) variance of will also be small? Not necessarily. If the Markov chain takes a long time to mix, the small local variance can accumulate to a large global variance over many steps of the Markov chain. Thus, a slowly mixing chain has a large Poincaré constant . Conversely, if the chain mixes rapidly, the Poincaré constant is small.
, etc.; the function does not change much over a single step of the Markov chain. Does this mean that the (global) variance of will also be small? Not necessarily. If the Markov chain takes a long time to mix, the small local variance can accumulate to a large global variance over many steps of the Markov chain. Thus, a slowly mixing chain has a large Poincaré constant . Conversely, if the chain mixes rapidly, the Poincaré constant is small.
This relation between mixing and Poincaré inequalities is quantified by the following theorem:
Theorem (Poincaré inequalities from eigenvalues). The Markov chain satisfies a Poincaré inequality with constant
This is the smallest possible Poincaré inequality for the Markov chain.
![\[\alpha= \frac{1}{1-\lambda_2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0143e8947cd9b6ad343afca4ab36be9f_l3.png "Rendered by QuickLaTeX.com")
One way to interpret this result is that the eigenvalue gives you Poincaré inequality (1). But we can flip this result around: Poincaré inequalities (1) establish bounds on the eigenvalue .
Corollary (Eigenvalue bounds from Poincaré inequalities). If the Markov chain satisfies a Poincaré inequality (1) for a certain constant
![\[\lambda_2 \le \frac{1}{1-\alpha}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-be80ee6ab2085c10ff126a991ec9ca19_l3.png "Rendered by QuickLaTeX.com")
A View to the Continuous Setting
For a particularly vivid example of a Poincaré inequality, it will be helpful to take a brief detour to the world of continuous Markov processes. This series has—to this point—exclusively focused on Markov chains  that have finitely many possible states and are indexed by discrete times
that have finitely many possible states and are indexed by discrete times  .. We can generalize Markov chains by lifting both of these restrictions, considering Markov processes
.. We can generalize Markov chains by lifting both of these restrictions, considering Markov processes  which take values in continuous space (such as the real line
which take values in continuous space (such as the real line  ) and are indexed by continuous times
) and are indexed by continuous times  .
.
The mathematical details for Markov processes are a lot more complicated than for their Markov chain siblings, so we will keep it light on details.
For this example, our Markov process will be the Ornstein–Uhlenbeck process. This process has the somewhat mysterious form
![\[x_t = e^{-t}x_0 + e^{-t} B_{e^{2t}-1},\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c98a0f6993431b8ea3c5ce14e96fd6d0_l3.png "Rendered by QuickLaTeX.com")
 denotes a (standard) Brownian motion, independent of the starting state . At time
denotes a (standard) Brownian motion, independent of the starting state . At time  , the Brownian motion
, the Brownian motion  has a Gaussian distribution with variance . Thus,
has a Gaussian distribution with variance . Thus,
Conditional on its starting value
is has a Gaussian distribution with mean
and variance
.
From this observation, it appears that the stationary distribution of the Ornstein–Uhlenbeck process is the standard Gaussian distribution. Indeed, this is the case, and the Ornstein–Uhlenbeck process converges to stationarity exponentially fast.
Since we have exponential convergence to stationarity,1And, as can be checked, the Ornstein–Uhlenbeck process is reversible, in the appropriate sense. there’s a Poincaré inequality lurking in the background, known as the Gaussian Poincaré inequality. Letting  denote a standard Gaussian random variable, Gaussian Poincaré inequality states that
denote a standard Gaussian random variable, Gaussian Poincaré inequality states that
(2) ![\[\Var(f(Z)) \le \expect \big[(f'(Z))^2\big].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2da5301cf15bd60eddb662b9859d986b_l3.png "Rendered by QuickLaTeX.com")
![\[\mathcal{E}(f) = \expect \big[(f'(Z))^2\big].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c734423684e8cbeef463d21fd3a7d8cd_l3.png "Rendered by QuickLaTeX.com")
The Gaussian Poincaré inequality presents a very clear demonstration of what a Poincaré inequality is: The global variance of the function  is controlled by its local variability, here quantified by the expected squared derivative:
is controlled by its local variability, here quantified by the expected squared derivative:
 as a generalization of the “expected squared derivative” of the function .
as a generalization of the “expected squared derivative” of the function .
Our main interest in Poincaré inequalities in this post is instrumental, we seek to use Poincaré inequalities to understand the mixing properties of Markov chains. But the Gaussian Poincaré inequality demonstrates that Poincaré inequalities are also interesting on their own terms. The inequality (2) is a useful inequality for bounding the variance of a function of a Gaussian random variable. As an immediate example, observe that the function  has derivative bounded by
has derivative bounded by  :
:  . Thus,
. Thus,
![\[\Var(\tanh Z) \le \expect[(f'(Z))^2] \le 1.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-62932f1a7dd99680d5022f2f617204f6_l3.png "Rendered by QuickLaTeX.com")
 is –Lipschitz continuous and use the exchangeable pairs formula for variance:
is –Lipschitz continuous and use the exchangeable pairs formula for variance: ![\Var(\tanh(Z)) = 0.5\expect[(\tanh Z - \tanh Z')^2] \le 0.5 \expect[(Z-Z')^2] = \Var(Z) = 1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-13cfee974435cfa789dc50791f5dd980_l3.png "Rendered by QuickLaTeX.com") , where
, where  is an independent copy of . but the point stands that the Gaussian Poincaré inequality—and Poincaré inequalities in general—can be useful on their own terms.3The Gaussian Poincaré inequality’s multidimensional generalization has especially interesting consequences. See the bottom of this post for an example.
is an independent copy of . but the point stands that the Gaussian Poincaré inequality—and Poincaré inequalities in general—can be useful on their own terms.3The Gaussian Poincaré inequality’s multidimensional generalization has especially interesting consequences. See the bottom of this post for an example.
Poincaré Inequalities and Eigenvalues
For the remainder of this post, we will develop the connection between Poincaré inequalities and eigenvalues, leading to a proof of our main theorem:
Theorem (Poincaré inequalities from eigenvalues). The Markov chain satisfies a Poincaré inequality with constant
That is,
(3)
There exists a function
![\[\Var_\pi(f)\le \frac{1}{1-\lambda_2}\cdot\mathcal{E}(f) \quad \text{for all } f\in\real^m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8b1dc6392929fce027a5637445e5e788_l3.png "Rendered by QuickLaTeX.com")
We begin by showing that it suffices to consider mean-zero functions ![\expect[f] = 0](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ec4690eff3c2fed1a114233e551241f6_l3.png "Rendered by QuickLaTeX.com") to prove (3). Next, we derive formulas for and using the -inner product
to prove (3). Next, we derive formulas for and using the -inner product  . We conclude by expanding in eigenvectors of and deriving the Poincaré inequality (3).
. We conclude by expanding in eigenvectors of and deriving the Poincaré inequality (3).
Shift to Mean-Zero
To prove the Poincaré inequality (3), we are free to assume that has mean zero, ![\expect_\pi[f]=0](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6fa817f7b45e4b28fb57943a37ce1887_l3.png "Rendered by QuickLaTeX.com") . Indeed, both the variance and local variance don’t change if we shift by a constant
. Indeed, both the variance and local variance don’t change if we shift by a constant  . That is, letting
. That is, letting  denote the function
denote the function
![\[\mathbb{1}(i) = 1 \quad\text{for }i =1,\ldots,m,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-76d08dac199d8cde7c208717c678cb21_l3.png "Rendered by QuickLaTeX.com")
![\[\Var_\pi(f+c\mathbb{1})=\Var_\pi(f)\quad\text{and}\quad\mathcal{E}(f+c\mathbb{1})=\mathcal{E}(f)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-397546ace1cf7f9ee61e6b903c5d30fa_l3.png "Rendered by QuickLaTeX.com")
and constant . Therefore, for proving our Poincaré inequality, we can always shift so that it is mean-zero: ![\[\expect_\pi[f] = 0.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-768127e484e8e86a1ea3b0c57ff2254b_l3.png "Rendered by QuickLaTeX.com")
Variance
Our strategy for proving the main theorem will be to develop a more linear algebraic formula for the variance and local variance. Let’s begin with the variance.
Assume ![\expect_\pi[f] = 0](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5bb3a81c46de080d7497a8b15dc671e4_l3.png "Rendered by QuickLaTeX.com") . Then the variance is
. Then the variance is
![\[\Var_\pi(f)=\expect[f^2]=\sum_{i=1}^m f(i)f(i)\pi_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-34c04d78b686f1464575345ff7942f0e_l3.png "Rendered by QuickLaTeX.com")
-inner product, we have shown that ![\[\Var_\pi(f)=\langle f,f\rangle.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c8e6cda6b300b5ffc2d56c82e0024a40_l3.png "Rendered by QuickLaTeX.com")
Local Variance
Now we derive a formula for the local variance:
![\[\mathcal{E}(f) = \frac{1}{2} \expect[(f(x_0)-f(x_1))^2]\quad \text{where }x_0\sim\pi.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b19838fb6f36da7cbd443083ba89017c_l3.png "Rendered by QuickLaTeX.com")
 and
and  is
is  . Thus,
. Thus, ![\[\mathcal{E}(f) = \frac{1}{2} \sum_{i,j=1}^m (f(i)-f(j))^2 \pi_iP_{ij}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3b001418aee305354517a3784887e27f_l3.png "Rendered by QuickLaTeX.com")
![\[\mathcal{E}(f) = {\rm A} + {\rm B} + {\rm C}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a50f3c027ad34072a0bd9bd6348c40a0_l3.png "Rendered by QuickLaTeX.com")

Let’s take each of these terms one-by-one. For  , recognize that
, recognize that  . Thus,
. Thus,
![\[{\rm A} = \frac{1}{2}\sum_{i=1}^m (f(i))^2 \pi_i = \frac{1}{2}\langle f, f\rangle.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-dad7cb3fe33d90897dd8b5a31625ca44_l3.png "Rendered by QuickLaTeX.com")
 , use detailed balance
, use detailed balance  . Then, using the condition
. Then, using the condition  , we obtain
, we obtain ![\[{\rm B} = \frac{1}{2} \sum_{j=1}^m (f(j))^2 \left(\sum_{i=1}^m \pi_j P_{ji} \right) = \frac{1}{2} \sum_{j=1}^m (f(j))^2 \pi_j = \frac{1}{2} \langle f, f\rangle.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d26f896a5e016a55ba59c4b0abca8f69_l3.png "Rendered by QuickLaTeX.com")
 , recognize that
, recognize that  is the
is the  th entry of the matrix–vector product
th entry of the matrix–vector product  . Thus,
. Thus, ![\[{\rm C} = - \sum_{i=1}^m f(i) Pf(i) \,\pi_i = -\langle f, Pf\rangle.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-37f0ed03af3cbfc11bccf5a6f6e20bb1_l3.png "Rendered by QuickLaTeX.com")
![\[\mathcal{E}(f) = \langle f, (I-P)f\rangle,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9450ee3a751ddf403b01a7f69fe26a2e_l3.png "Rendered by QuickLaTeX.com")
 denotes the identity matrix.
denotes the identity matrix.
Conclusion
The Poincaré inequality
![\[\Var_\pi(f) \le \frac{1}{1-\lambda_2} \cdot\mathcal{E}(f) \quad \text{for all $f$ with $\expect_\pi[f] = 0$}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3d732320f8d8787a3cc4cec15b09d8d4_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{\mathcal{E}(f)}{\Var_\pi(f)}\ge 1-\lambda_2 \quad \text{for all $f$ with $\expect_\pi[f] = 0$}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f7218fec7abdef7e7270acb4dbeb6fd7_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{\langle f, (I-P)f\rangle}{\langle f, f\rangle} \ge 1-\lambda_2 \quad \text{for all $f$ with $\expect_\pi[f] = 0$}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3690797d7d53191ee73aac81fbcdd36c_l3.png "Rendered by QuickLaTeX.com")
as a linear combination of eigenvectors.
Consider a decomposition of as a linear combination of ‘s eigenvectors:
![\[f = c_1 \varphi_1 + c_2 \varphi_2 + \cdots + c_m\varphi_m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-df5f258e09e7a807979852d3373b2035_l3.png "Rendered by QuickLaTeX.com")
is equivalent to saying that  .
.
Using the orthonormality of under the -inner product and the eigenvalue relation  , we have that
, we have that

Thus,
(4) 
where
![\[a_i = \frac{c_i^2}{c_2^2 + \cdots + c_m^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3895b1bbfe12ec753d65b2a519517c7b_l3.png "Rendered by QuickLaTeX.com")
 are nonnegative and add to :
are nonnegative and add to : ![\[a_2+\cdots+a_m = \frac{c_2^2+\cdots+c_m^2}{c_2^2+\cdots+c_m^2} = 1.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b076fc822731dc667d48e67a60bbf6ea_l3.png "Rendered by QuickLaTeX.com")
 and
and  (equivalently, setting
(equivalently, setting  ). Thus, we conclude
). Thus, we conclude ![\[\frac{\langle f, (I-P)f\rangle}{\langle f, f\rangle}\ge 1-\lambda_2,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1b798877b91df792cf96ef10eb9ac632_l3.png "Rendered by QuickLaTeX.com")
is a multiple of  .
.
![\[\chi^2\left(\rho^{(n)} \, \middle|\middle| \, \pi\right) \le \left( \max \{ \lambda_2, -\lambda_n \} \right)^{2n} \chi^2\left(\rho^{(0)} \, \middle|\middle| \, \pi\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ed65d0043f7a436b0f42a6d096d34e9f_l3.png "Rendered by QuickLaTeX.com")
 Fortunately, there is a trick.
Fortunately, there is a trick. for every
for every  , where
, where  :
:![\[\pi^\top P^{\rm lazy} = \frac{1}{2} \pi^\top P + \frac{1}{2} \pi^\top I = \frac{1}{2} \pi^\top + \frac{1}{2} \pi^\top = \pi^\top.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d33d9a3024c655134a56d89b119cf39c_l3.png "Rendered by QuickLaTeX.com")
![\[\lambda_i^{\rm lazy} = \frac{1+\lambda_i}{2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ac2938aa6854a708a394222649af1e66_l3.png "Rendered by QuickLaTeX.com")
 are
are  , all of the eigenvalues of the lazy chain are
, all of the eigenvalues of the lazy chain are  . Thus, the smallest eigenvalue of
. Thus, the smallest eigenvalue of  :
:![\[\chi^2\left(\rho^{(n)} \, \middle|\middle| \, \pi\right) \le \left( \lambda_2^{\rm lazy} \right)^{2n} \chi^2\left(\rho^{(0)} \, \middle|\middle| \, \pi\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-861a132f08a1c2b208d61eb004ed58bb_l3.png "Rendered by QuickLaTeX.com")
 is an eigenvalue, the chain will fail to converge to stationarity at all. For this application, the lazy approach may make sense.
is an eigenvalue, the chain will fail to converge to stationarity at all. For this application, the lazy approach may make sense. drawn from the stationary distribution:
drawn from the stationary distribution: ![\[\expect_{x\sim \pi} [f(x)] = \sum_{i=1}^m f(i) \pi_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6399c58f0e1b13f3cffac439c145d3b4_l3.png "Rendered by QuickLaTeX.com")
 of the value of
of the value of  values
values  of the chain
of the chain![\[\hat{f}_{N}\coloneqq \frac{1}{N}\sum_{n=0}^{N-1} f(x_i).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-591e83a4f5551f6826ddffb5de03ce72_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{f}_N = \frac{1}{N}\sum_{n=0}^{N-1} f(x_i)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-615239005583b665db04e6a578abec08_l3.png "Rendered by QuickLaTeX.com")
 . For a large number
. For a large number ![\expect_{x\sim \pi} [f(x)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e4b2ff50078922c10c1f0a32237a19d6_l3.png "Rendered by QuickLaTeX.com") and variance
and variance  where
where ![\[\sigma^2 = \Var[f(x_0)] + 2\sum_{n=1}^\infty \Cov(f(x_0),f(x_n)). \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b209aff956ed442df57ac781c0376a2f_l3.png "Rendered by QuickLaTeX.com")
 . The faster the covariance decreases, the smaller
. The faster the covariance decreases, the smaller  will be and thus the smaller the error for the Markov chain average.
will be and thus the smaller the error for the Markov chain average. ,
, ![\[\frac{\hat{f}_N - \expect_{x \sim \pi} [f(x)]}{\sqrt{N}}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f5818a8980215e63da79048168aa8b79_l3.png "Rendered by QuickLaTeX.com")
 that are
that are ![\[\langle \varphi_i,\varphi_j \rangle = \expect_{x\sim \pi} [\varphi_i(x)\varphi_j(x)] = \begin{cases}1, & i = j, \\0, & i \ne j.\end{cases}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-139934705e34440f3c903f0e089f580b_l3.png "Rendered by QuickLaTeX.com")
 as defining a function
as defining a function  . Thus, we can expand the function
. Thus, we can expand the function ![\[f = c_1 \varphi_1 + \cdots + c_m \varphi_m. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c7d7e27ce6d2d6d0e3c721a120eef469_l3.png "Rendered by QuickLaTeX.com")
 is the vector of all ones (or, equivalently, the function that outputs
is the vector of all ones (or, equivalently, the function that outputs  at time
at time  at time
at time  . In other words, multiplying by
. In other words, multiplying by  :
:![\[(Pf)(i) = \expect[f(x_1) \mid x_0 = i].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d3abc35eacbcac194f948451539f7778_l3.png "Rendered by QuickLaTeX.com")
![\[(P^nf)(i) = \expect[f(x_n) \mid x_0 = i]. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3aee313626d01d020c481e25567fe6c1_l3.png "Rendered by QuickLaTeX.com")
 denote a probability distribution which places 100% of the probability mass on the single site
denote a probability distribution which places 100% of the probability mass on the single site  is
is ![\[(P^n f)(i) = \delta_i^\top (P^n f) = (\delta_i^\top P^n) f.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e8c9b07d76e51bf1a6c2e582e9a239a7_l3.png "Rendered by QuickLaTeX.com")
 is the state of the Markov chain after
is the state of the Markov chain after  . Thus,
. Thus,![\[(P^n f)(i) = (\rho^{(n)})^\top f = \sum_{i=1}^m \rho^{(n)}_i f(i) = \expect[f(x_n) \mid x_0=i].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6eaa69991373f0004f94c020fd9d4b3c_l3.png "Rendered by QuickLaTeX.com")
 and the spectral decomposition of
and the spectral decomposition of ![\[\Cov (f(x_0),f(x_n)) = \expect[f(x_0)f(x_n)] - \expect[f(x_0)]\expect[f(x_n)]. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0d2881b12745eed9e1a985eb8fefa650_l3.png "Rendered by QuickLaTeX.com")
![\expect[f(x_0)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c88debcfbbae714aadb6b34e5a6fd646_l3.png "Rendered by QuickLaTeX.com") and
and ![\expect[f(x_n)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-35ed314f41c6654ee1ef7f9631c96e4e_l3.png "Rendered by QuickLaTeX.com") . Since
. Since ![\[\expect[f(x_0)] = \expect[f(x_0) \cdot 1] = \expect[f(x_0) \varphi_1(x_0)] = \langle f, \varphi_1\rangle = c_1.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fceebd56048f584bab0bf0ba12254652_l3.png "Rendered by QuickLaTeX.com")
 .
.
 , so we have
, so we have ![\expect[f(x_n)] = \expect[f(x_0)] = c_1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-703a86f4cdb9f7d354b2f7440826b5e9_l3.png "Rendered by QuickLaTeX.com") .
.![\expect[f(x_0)f(x_n)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-274aba259d8ec1c94a05588a5b6e3846_l3.png "Rendered by QuickLaTeX.com") . Use the
. Use the ![\begin{align*}\expect[f(x_0)f(x_n)] &= \sum_{i=1}^m \expect[f(x_0) f(x_n) \mid x_0 = i] \prob\{x_0 = i\} \\&= \sum_{i=1}^m f(i) \expect[f(x_n) \mid x_0 = i] \pi_i.\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2e350d683f2a7cfff71028de3a45dbf8_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[f(x_0)f(x_n)] = \sum_{i=1}^m f(i) (P^n f)(i) \pi_i = \langle f, P^n f\rangle.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-10a769b03dee2b18b03876d46eaac7c7_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[f(x_0)f(x_n)] = \left\langle \sum_{i=1}^m c_i \varphi_i,\sum_{i=1}^m c_i P^n\varphi_i \right\rangle = \left\langle \sum_{i=1}^m c_i \varphi_i,\sum_{i=1}^m c_i \lambda_i^n \varphi_i \right\rangle = \sum_{i=1}^m \lambda_i^n \, c_i^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-63bbc0c0f98d4c57de9a53a7162295f3_l3.png "Rendered by QuickLaTeX.com")
![\expect[f(x_0)] = \expect[f(x_n)] = c_1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0dee583b20d0c65301633cb289069661_l3.png "Rendered by QuickLaTeX.com") and plugging into (4), we obtain
and plugging into (4), we obtain![\[\Cov(f(x_0),f(x_n)) = \sum_{i=1}^m \lambda_i^n \, c_i^2 - c_1^2 = \sum_{i=2}^m \lambda_i^n c_i^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-20b7af4f300077ae2d041dae30de529d_l3.png "Rendered by QuickLaTeX.com")
 , so
, so  entirely drops out of the covariance.
entirely drops out of the covariance.
![\[\Var[f(x_0)] = \Cov(f(x_0),f(x_0)) = \sum_{i=2}^m \lambda_i^0 c_i^2 = \sum_{i=2}^m c_i^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5f587d4d05f65d8d43d5824fd499d0d2_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*}\sigma^2 &= \Var[f(x_0)] + 2\sum_{n=1}^\infty \Cov(f(x_0),f(x_n)) \\&= \sum_{i=2}^m c_i^2 + 2\sum_{n=1}^\infty \sum_{i=2}^m \lambda_i^n \, c_i^2 \\&= -\sum_{i=2}^m c_i^2 + 2\sum_{i=2}^m \left(\sum_{n=0}^\infty \lambda_i^n\right)c_i^2 .\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-da05968b01086497f8e6e098e384b170_l3.png "Rendered by QuickLaTeX.com")
![\[\sigma^2 = -\sum_{i=2}^m c_i^2 + 2\sum_{i=2}^m \frac{1}{1-\lambda_i} c_i^2 = \sum_{i=2}^m \left(\frac{2}{1-\lambda_i}-1\right)c_i^2 = \sum_{i=2}^m \frac{1+\lambda_i}{1-\lambda_i} c_i^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-61c9cb2ae48b8b474edd697e36a1e58c_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{f}_N = \frac{1}{N} \sum_{i=0}^{N-1} f(x_n)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-76330a2c8101f63831cdc0bcdd4e0cee_l3.png "Rendered by QuickLaTeX.com")
![\expect_{x \sim \pi} [f(x)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c4b525a230a1b1912a79546d8b641e00_l3.png "Rendered by QuickLaTeX.com") . The Markov chain central limit theorem shows that, for a large number of steps
. The Markov chain central limit theorem shows that, for a large number of steps ![\hat{f}_N - \expect_{x\sim\pi}[f(x)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0f260b35378f3e3cb9ca1723ad1a0fe1_l3.png "Rendered by QuickLaTeX.com") is approximately normally distributioned with mean zero and variance
is approximately normally distributioned with mean zero and variance  of the transition matrix
of the transition matrix  . Thus, we have
. Thus, we have
 of an eigenvalue
of an eigenvalue  is scaled by in
is scaled by in  for the corresponding eigenvalue
for the corresponding eigenvalue  of the lazy chain. We see that at every
of the lazy chain. We see that at every  value, the lazy chain has a higher amplification factor than the original chain.
value, the lazy chain has a higher amplification factor than the original chain.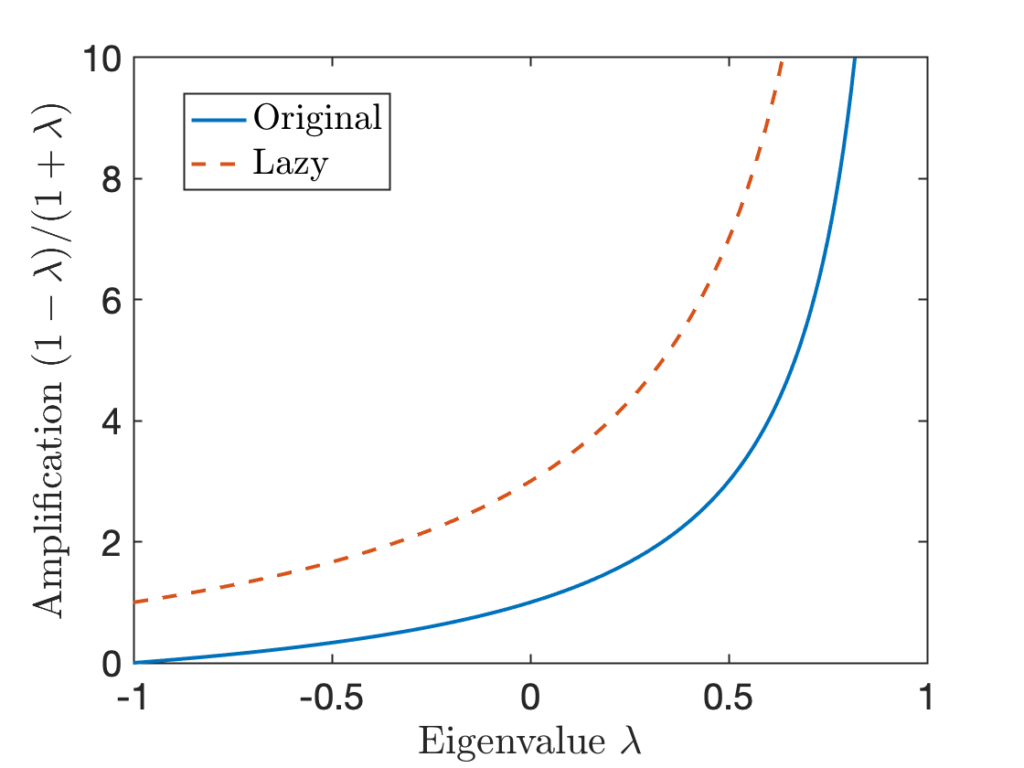
 and
and  and functions
and functions  as being one and the same, and we will use both
as being one and the same, and we will use both  and
and  to denote the
to denote the  numbers, but instead labels each state
numbers, but instead labels each state  with a numeric value.
with a numeric value.![\expect[f]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fb89f41552bdb76a7c8c04d9d35b3631_l3.png "Rendered by QuickLaTeX.com") denote the
denote the  where
where  is drawn from
is drawn from ![\[\expect[f] \coloneqq \expect_{X \sim \pi} [f(X)] = \sum_{i=1}^m \pi_i f(i).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-09e6ff4df06017b52b788b6787fad904_l3.png "Rendered by QuickLaTeX.com")
![\[\Var(f) \coloneqq \expect [(f - \expect[f])^2] = \sum_{i=1}^m (f(i) - \expect[f])^2 \pi_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-03395d1f27b782837abde9a7d030c4c7_l3.png "Rendered by QuickLaTeX.com")
 denote a probability distribution which assigns 100% probability to outcome
denote a probability distribution which assigns 100% probability to outcome  matrix with real entries
matrix with real entries  (i.e., one satisfying
(i.e., one satisfying  ) has
) has  .
. . Let’s first ask: What does the transpose
. Let’s first ask: What does the transpose  is equipped with the
is equipped with the  and it is defined as
and it is defined as![\[(f,g) \coloneqq f^\top g = \sum_{i=1}^m f(i) g(i).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-86465508e63dc4f1aefde253dd2b2a7c_l3.png "Rendered by QuickLaTeX.com")
 .
.
![\[(f,Ag) = (A^\top f, g)\quad \text{for every }f,g\in\real^m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9bc76899fbef0450c0757d9d90e3722a_l3.png "Rendered by QuickLaTeX.com")
 is the same as the amount of
is the same as the amount of  in the direction of
in the direction of ![[\cdot,\cdot]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9f5a656d3836fd9f84831aee0283adc1_l3.png "Rendered by QuickLaTeX.com") be any inner product on
be any inner product on  such that
such that ![\[[f,Ag]=[A^*f,g]\quad\text{for every }f,g\in\real^m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fe7c2788bf80274e17adc7bef25f9701_l3.png "Rendered by QuickLaTeX.com")
 .
.![\[[u_i,u_j]=\begin{cases}1, & i=j, \\0,& i\ne j.\end{cases}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6485908bc8e69e0ad6fb16b826344f60_l3.png "Rendered by QuickLaTeX.com")
![\[\langle f, g \rangle \coloneqq \expect[f\cdot g] = \sum_{i=1}^m f(i)g(i) \pi_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a1d97adbf15c3c5bd85460e94161ee28_l3.png "Rendered by QuickLaTeX.com")
![\expect[f] = \expect[g] = 0](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-16f996fb8f734dee3bcc58dc1b6638b1_l3.png "Rendered by QuickLaTeX.com") ), it reports the
), it reports the  where
where  is drawn from
is drawn from  :
:
![\[\pi_i P_{ij} = \pi_j P_{ji} \quad \text{for } i,j=1,2,\ldots,m\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d24fd7216a2b9a2afc49c2f1ae9ea55c_l3.png "Rendered by QuickLaTeX.com")
![\[\langle f, Pg \rangle= \sum_{i,j=1}^m f(i) g(j) \pi_jP_{ji} = \sum_{j=1}^m \left( \sum_{i=1}^m f(i) P_{ij} \right) g(j) \pi_j = \langle Pf, g\rangle.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2e8d0788b8c0f3ee0e4602e817957cfa_l3.png "Rendered by QuickLaTeX.com")
 associated with eigenvectors
associated with eigenvectors ![\[\langle\varphi_i,\varphi_j\rangle=\begin{cases}1, &i=j\\0,& i\ne j.\end{cases}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fd0e99bc2439329beccce1339db0aee9_l3.png "Rendered by QuickLaTeX.com")
 span all of
span all of  elsewhere. Then, by the fundamental theorem of Markov chains,
elsewhere. Then, by the fundamental theorem of Markov chains,  converges to
converges to  for every
for every  . Thus, since
. Thus, since  for every vector
for every vector  in magnitude.
in magnitude. is a vector of all one’s.
is a vector of all one’s. have magnitude
have magnitude  .
. for every
for every  .
.![\[\norm{\sigma - \pi}_{\rm TV} = \max_{A \subseteq \{1,\ldots,m\}} |\sigma(A) - \pi(A)| = \frac{1}{2} \sum_{i=1}^m |\sigma_i - \pi_i|.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d369d587213cfe7bb579ea5d2d89d1f8_l3.png "Rendered by QuickLaTeX.com")

 and
and  of each outcome. Spectral theory plays more nicely with an “
of each outcome. Spectral theory plays more nicely with an “ ” way of comparing probability distributions, which we develop now.
” way of comparing probability distributions, which we develop now. . This provides a general way of figuring out which objects for finite state space Markov chains are row vectors and which are column vectors: Measures are row vectors whereas functions are column vectors.
. This provides a general way of figuring out which objects for finite state space Markov chains are row vectors and which are column vectors: Measures are row vectors whereas functions are column vectors. given by
given by![\[h(i) = \frac{d\sigma}{d\pi}(i) = \frac{\sigma_i}{\pi_i} \quad \text{for } i=1,2,\ldots,m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cbffacfb7f8993bd3f61752e12035912_l3.png "Rendered by QuickLaTeX.com")
![\[\expect_{X \sim \sigma} [g(X)] = \expect_{Y \sim \pi}[g(Y)h(Y)] = \sum_{i=1}^m g(i)h(i) \pi_i. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b0bf11be5c7b4508cf0965a0c53426ab_l3.png "Rendered by QuickLaTeX.com")
 is a random variable with distribution
is a random variable with distribution ![\mathrm{Unif}[0,1]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0db92c7166ac7b273b85e4c488d226ea_l3.png "Rendered by QuickLaTeX.com") ) is a function
) is a function  such that
such that![\[\expect_{X \sim \sigma} [g(X)] = \expect_{Y\sim \mathrm{Unif}[0,1]} [g(Y)h(Y)] = \int_0^1 g(x) h(x) \, dx.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c7f33161d65ad1fcb0f79f24b4f51a0f_l3.png "Rendered by QuickLaTeX.com")
 replaced with integrals
replaced with integrals  .
.
![\[\chi^2(\sigma \mid\mid \pi) \coloneqq \Var \left(\frac{d\sigma}{d\pi} \right) = \expect \left[\left( \frac{d\sigma}{d\pi} - 1 \right)^2\right] = \expect \left[\left(\frac{d\sigma}{d\pi}\right)^2\right] - 1.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2521b63ae50f02fe6099c54dcc4e00a4_l3.png "Rendered by QuickLaTeX.com")
 , note that
, note that![\[\expect\left[\frac{d\sigma}{d\pi}\right] = \sum_{i=1}^m \frac{d\sigma}{d\pi}(i) \pi_i = \sum_{i=1}^m \frac{\sigma_i}{\pi_i} \pi_i = \sum_{i=1}^m \sigma_i = 1. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6bcec4a11dcc43c0b01738d12e38d6e6_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\sigma - \pi}_{\rm TV} = \frac{1}{2} \expect \left[ \left| \frac{d\sigma}{d\pi} - 1 \right| \right].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4ab771f36e4aabcf1fcbe807729630b6_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\sigma - \pi}_{\rm TV} = \frac{1}{2} \expect \left[ \left| \frac{d\sigma}{d\pi} - 1 \right| \right] \le \frac{1}{2} \left(\expect \left[ \left( \frac{d\sigma}{d\pi} - 1 \right)^2 \right]\right)^{1/2} = \frac{1}{2} \sqrt{\chi^2(\sigma \mid\mid \pi)}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4986b7434b84b79aff6f94df2ec4b4e8_l3.png "Rendered by QuickLaTeX.com")
 denote the distributions of the Markov chain at times
denote the distributions of the Markov chain at times  and
and  ,
, ![\[\chi^2(\delta_i \mid\mid \pi) \le \frac{1}{\pi_i}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4896a0499c8c3b1ab5bc1e2952fd1d65_l3.png "Rendered by QuickLaTeX.com")
![\[\chi^2\left( \rho^{(0)} \, \middle|\middle| \, \pi \right) \le \frac{1}{\min_{1\le i\le m} \pi_i} \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c3a7cb7312400b0230e1a53951e6d0a7_l3.png "Rendered by QuickLaTeX.com")
![\[\chi^2(\delta_i \mid\mid \pi) = \Var(d\delta_i/d\pi) \le \expect[(d\delta_i/d\pi)^2] = 1/\pi_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7343459c314bf5425643e99e6f0e2906_l3.png "Rendered by QuickLaTeX.com")
 is a
is a  for some
for some  -total variation distance to stationarity
-total variation distance to stationarity ![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le \varepsilon\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5ed1f6d26bba1fa54f9bd01bcf39defc_l3.png "Rendered by QuickLaTeX.com")
![\[n = \left\lceil \frac{1}{\log(\max\{\lambda_2,-\lambda_n\})}\log \left( \frac{1}{2\varepsilon \min_{1\le i \le m}\sqrt{\pi_i}} \right) \right\rceil \text{ steps}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8d9dc3295020a8171795dec7e448eef5_l3.png "Rendered by QuickLaTeX.com")

 . To do this, we use the recurrence for the probability distribution:
. To do this, we use the recurrence for the probability distribution:![\[\rho^{(n+1)}_j = \sum_{i=1}^m \rho_i^{(n)} P_{ij}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-84dcc77d0a4138d7d59160bcf259be32_l3.png "Rendered by QuickLaTeX.com")
![\[\left( \frac{d\rho^{(n+1)}}{d\pi}\right)_j = \frac{\rho_j^{(n+1)}}{\pi_j} = \frac{\sum_{i=1}^m \rho^{(n)}_i P_{ij}}{\pi_j}= \sum_{i=1}^m \rho^{(n)}_i\frac{P_{ij}}{\pi_j}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b6c60937b23d2509e4a3e4fa1f121427_l3.png "Rendered by QuickLaTeX.com")
 , which implies
, which implies![\[\left( \frac{d\rho^{(n+1)}}{d\pi}\right)_j = \sum_{i=1}^m\rho^{(n)}_i \frac{P_{ji}}{\pi_i} = \sum_{i=1}^m P_{ji} \frac{\rho^{(n)}_i}{\pi_i} = \left( P \frac{d \rho^{(n)}}{d\pi} \right)_j.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d22315b80e3fc4d3736d0c49f877fa9c_l3.png "Rendered by QuickLaTeX.com")
 is an ordinary
is an ordinary ![\[\frac{d\rho^{(n+1)}}{d\pi} = P \frac{d\rho^{(n)}}{d\pi} \quad \text{for } n =0,1,\ldots. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-406471ab024dae5551eae8b499a0243e_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{d\rho^{(0)}}{d\pi} = c_1 \mathbf{1} + c_2 \varphi_2 + \cdots + c_m \varphi_m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6bcb8bbdd130a3e85c422adc2f37715d_l3.png "Rendered by QuickLaTeX.com")
![\expect[d\rho^{(0)}/d\pi] = 1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-37f5774410e7d60045c0758953e0cdde_l3.png "Rendered by QuickLaTeX.com") . Thus, we conclude
. Thus, we conclude  . Since the
. Since the  are eigenvectors of
are eigenvectors of  , the recurrence (7) implies
, the recurrence (7) implies![\[\frac{d\rho^{(n)}}{d\pi} = \mathbf{1} + c_2 \lambda_2^n \varphi_2 + \cdots + c_m \lambda_m^n \varphi_m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-935cf156fcf1f467b0c6719614b94e6b_l3.png "Rendered by QuickLaTeX.com")
![\[\chi^2(\rho^{(n)} \mid\mid \pi) = \sum_{i=2}^m c_i^2 \lambda_i^{2n} \le (\max \{ \lambda_2, -\lambda_m \})^{2n} \sum_{i=2}^m c_i^2 = (\max \{ \lambda_2, -\lambda_m \})^{2n} \chi^2(\rho^{(0)} \mid\mid \pi).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7b82e2d3cefcede8d4a7a72b1fa3ceea_l3.png "Rendered by QuickLaTeX.com")
![\[\tau_{\rm mix} \coloneqq \min \left\{ n \ge 1 : \max_{\rho^{(0)}} \norm{\rho^{(n)} - \pi}_{\rm TV} \le \frac{1}{2e} \right\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e491d914ce283944ca10dc9d96bdb1a5_l3.png "Rendered by QuickLaTeX.com")
 of the chain at time
of the chain at time  is the
is the ![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le e^{-\lfloor n / \tau_{\rm mix}\rfloor}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8a28da28e02550f209ce8ec1c8b5b79e_l3.png "Rendered by QuickLaTeX.com")
 , then
, then  .
. .
. such that (A) each process is individually a Markov chain with transition matrix
such that (A) each process is individually a Markov chain with transition matrix ![\[\prob\{x_{n+1} = j \mid x_n = i \} = \prob\{y_{n+1} = j \mid y_n = i \} = P_{ij}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8a91e29baa6fd219723bc325c68d9b75_l3.png "Rendered by QuickLaTeX.com")
 , then
, then  .
. and
and  is initialized in the stationary distribution
is initialized in the stationary distribution  . Let
. Let  be the time at which
be the time at which ![\[\tau_{\rho^{(0)}} \coloneqq \min\{ n \ge 0 : x_n = y_n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-68580815d8347111c8a35c6767c24d3e_l3.png "Rendered by QuickLaTeX.com")
 .
.![\tau_{\rm mix} \le 2e \max_{\rho^{(0)}} \expect[\tau_{\rho^{(0)}}]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6bff20b3e6944c95a1e8bf2d625c22d0_l3.png "Rendered by QuickLaTeX.com") .
.![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le \prob\{\tau_{\rho^{(0)}} > n\}\le \frac{\expect[\tau_{\rho^{(0)}}]}{n}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-74fd53f9c863d5faf2edb9698e58854f_l3.png "Rendered by QuickLaTeX.com")
 . Then the left-hand side is at most
. Then the left-hand side is at most  , so
, so![\[\frac{1}{2e} \le \max_{\rho^{(0)}}\norm{\rho^{(\tau_{\rm mix})} - \pi}_{\rm TV} = \prob\{\tau_{\rho^{(0)}} > n\} \le \frac{\max_{\rho^{(0)}}\expect[\tau_{\rho^{(0)}}]}{\tau_{\rm mix}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-61cf831f4db72e776d3122e3e323b7c1_l3.png "Rendered by QuickLaTeX.com")
 ). Therefore, one can also think of this Markov chain as a very inefficient way of generating a string of random bits.
). Therefore, one can also think of this Markov chain as a very inefficient way of generating a string of random bits. and a (uniform) random bit
and a (uniform) random bit  . Set
. Set  by changing the
by changing the  th bit of
th bit of  , and set
, and set  by changing the
by changing the  to
to  to set at some point, the two Markov chains have the same bit in position
to set at some point, the two Markov chains have the same bit in position  have been chosen by time
have been chosen by time  to be the time at which all positions
to be the time at which all positions ![\[\tau_{\rho^{(0)}} \le \tau_{\rm pick}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-878ab3b502681c3fb7c0453599af3293_l3.png "Rendered by QuickLaTeX.com")
![\expect[\tau_{\rm pick}]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ff405a11db183f95baecf7299661c685_l3.png "Rendered by QuickLaTeX.com") , it can be helpful to break into easier pieces. Let’s start with the simplest possible question: How many picks do we need to collect the first coupon? Just one. We always get a coupon in our first box.
, it can be helpful to break into easier pieces. Let’s start with the simplest possible question: How many picks do we need to collect the first coupon? Just one. We always get a coupon in our first box. of them are different from the first. So the probability of picking a new coupon in the second box is
of them are different from the first. So the probability of picking a new coupon in the second box is  . In fact,
. In fact, , and its mean is
, and its mean is  . On average, we need
. On average, we need  picks to collect the second coupon.
picks to collect the second coupon. coupons we haven’t collected and
coupons we haven’t collected and  . Thus, the number of picks is a geometric random variable with success probability
. Thus, the number of picks is a geometric random variable with success probability  .
. picks to pick the
picks to pick the  th coupon. Adding up the expected number of picks for each
th coupon. Adding up the expected number of picks for each  , we obtain that the total number of picks required is to collect all the coupons is
, we obtain that the total number of picks required is to collect all the coupons is![\[\expect[\tau_{\rm pick}] = 1 + \frac{N}{N-1} + \frac{N}{N-2} + \cdots + \frac{N}{N-(N-1)} = N \left( \frac{1}{N} + \frac{1}{N-1} + \cdots + \frac{1}{2} + 1 \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-db166dbcfe9198024b7dafb5de81fdf7_l3.png "Rendered by QuickLaTeX.com")
 denote the
denote the ![\[H_N = 1 + \frac{1}{2} + \cdots + \frac{1}{N}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-280c58a265450ae987b6c6236999bfd0_l3.png "Rendered by QuickLaTeX.com")
![\expect[\tau_{\rm pick}] = NH_N](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ec1cac0ce484b5e1ceef29a198523670_l3.png "Rendered by QuickLaTeX.com") . Since the
. Since the  , we have
, we have![\[\expect[\tau_{\rm pick}] \le N \log (N) + N.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2626a01a852627593ced1766177dcbbc_l3.png "Rendered by QuickLaTeX.com")
![\[\tau_{\rm mix} \le 2e \, \expect[\tau_{\rho^{(0)}}] \le 2e \, \expect[\tau_{\rm pick}] \le 2e \, N \log(N) + 2e \, N.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-73215e6c39a6bd7162aba749cd61e1bf_l3.png "Rendered by QuickLaTeX.com")
 .
.
![\[\prob\{\tau_{\rm pick} > N \log N + cN\} \le e^{-c}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-73f8883bcb323760364995473bcc3831_l3.png "Rendered by QuickLaTeX.com")
 and
and  , from which it follows that
, from which it follows that![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le \varepsilon \quad \text{provided that} \quad n \ge N \log N + N \log(1/\varepsilon).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-14c0bb8d63f118fc70a87253f64236af_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le \varepsilon \quad \text{provided that} \quad n \ge \frac{1}{2} N \log N + c \,N \log(1/\varepsilon)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ce2a7b130eee9537cf737b90814aa4d3_l3.png "Rendered by QuickLaTeX.com")
 . The constant
. The constant  in this inequality cannot be improved. See section 5.3.1 of
in this inequality cannot be improved. See section 5.3.1 of  . When initialized from any starting distribution
. When initialized from any starting distribution  if all of its entries are strictly positive. Recall that a Markov chain with transition matrix
if all of its entries are strictly positive. Recall that a Markov chain with transition matrix  . For this post, all Markov chains will have state space
. For this post, all Markov chains will have state space  and
and  under
under ![\[\norm{\rho - \sigma}_{\rm TV} = \max_{S \subseteq \{1,\ldots,m\}} |\rho(S) - \sigma(S)| = \frac{1}{2} \sum_{i=1}^m \left| \rho_i - \sigma_i \right|.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7dd0b0e121d45408883369794becedff_l3.png "Rendered by QuickLaTeX.com")
 .
. . Thus, despite these distributions seeming quite similar to us, the total variation distance between
. Thus, despite these distributions seeming quite similar to us, the total variation distance between  , if
, if![\[\prob \{x = i\} = \rho_i \quad \text{for $i=1,2,\ldots,m$}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3537663be586f21278e7e32b7502af94_l3.png "Rendered by QuickLaTeX.com")
 on
on  is a distribution on
is a distribution on  such that if a pair of random variables
such that if a pair of random variables  is drawn from
is drawn from  . Denote the set of all couplings of
. Denote the set of all couplings of  .
.![\[\norm{\rho - \sigma}_{\rm TV} = \min_{\gamma \in \operatorname{Couplings}(\rho,\sigma)} \prob_{(x,y) \sim \gamma} \{ x \ne y \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-918278c5556c178aee214db808000551_l3.png "Rendered by QuickLaTeX.com")
 represents the probability for variables
represents the probability for variables  drawn from joint distribution
drawn from joint distribution  . Then the coupling lemma tells us that there is a coupling
. Then the coupling lemma tells us that there is a coupling  . Indeed, such a coupling can be obtained by drawing
. Indeed, such a coupling can be obtained by drawing  . This defines a joint distribution
. This defines a joint distribution  with 100% probability.
with 100% probability. ,
, ![\[\norm{\rho - \sigma}_{\rm TV} \le \prob \{x \ne y \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2b881043ba005f53ae84ada8ebe53191_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho - \sigma}_{\rm TV} = \prob \{x \ne y\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e692d3e9715ed9b325be70775ba0eac3_l3.png "Rendered by QuickLaTeX.com")
 as
as  at an exponential rate.
at an exponential rate. is non-increasing
is non-increasing ![\[\norm{\rho^{(n+1)} - \pi}_{\rm TV} \le \norm{\rho^{(n)} - \pi}_{\rm TV} \quad \text{for every } n =0,1,2\ldots. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-49f8b3e1681a778cc0540ab25def9d1c_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho^{(n)} - \pi}_{\rm TV} = \prob \{x_n\ne y_n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8e78bf69e3ca31ba02e37fa3a64e5f52_l3.png "Rendered by QuickLaTeX.com")
 .
. , then run the two chains
, then run the two chains ![\[\prob\{x_{n+1}\ne y_{n+1}\} \le \prob\{x_n \ne y_n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3904173ffb700f39526fb117f5a6c248_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho^{(n+1)} - \pi}_{\rm TV} \le \prob\{x_{n+1}\ne y_{n+1}\} \le \prob\{x_n \ne y_n\} = \norm{\rho^{(n)} - \pi}_{\rm TV}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2409e83e870c68fe8d7f8e1a94903325_l3.png "Rendered by QuickLaTeX.com")
 .
. more carefully. Write it as
more carefully. Write it as
 , break into cases for all possible values
, break into cases for all possible values  for
for  to take
to take 
 be the minimum probability of moving between any two states
be the minimum probability of moving between any two states![\[p_{\rm min} \coloneqq \min_{1\le i,j\le m} P_{ij}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ca934d28f674adb9b8bc14ef320dd327_l3.png "Rendered by QuickLaTeX.com")
 to
to 
![\[\prob \{x_{n+1} \ne y_{n+1}\} \le (1 - p_{\rm min})\prob \{x_n \ne y_n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-69b8b6e06ad981139c7c6ffd1ae6d1ba_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho^{(n+1)}-\pi}_{\rm TV} \le \prob \{x_{n+1} \ne y_{n+1}\} \le (1 - p_{\rm min})\prob \{x_n \ne y_n\} = (1 - p_{\rm min}) \norm{\rho^{(n)} - \pi}_{\rm TV}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ce7570327a59ec2ede1a579d7f13564d_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le (1 - p_{\rm min})^n \norm{\rho^{(0)} - \pi}_{\rm TV} \le (1 - p_{\rm min})^n.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9119337225ce34aa99582b2b53069300_l3.png "Rendered by QuickLaTeX.com")
 . Fortunately, together with our earlier observation that distance to stationarity is non-increasing, we can upgrade this proof into a proof for the general case.
. Fortunately, together with our earlier observation that distance to stationarity is non-increasing, we can upgrade this proof into a proof for the general case. for which
for which  . Construct an auxilliary Markov chain
. Construct an auxilliary Markov chain  such that one step of the auxilliary chain consists of running
such that one step of the auxilliary chain consists of running ![\[z_0 = x_0, \:z_1 = x_{n_0}, \:z_2 = x_{2n_0},\ldots.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e5c67b34610d3cf8834e42621fd85218_l3.png "Rendered by QuickLaTeX.com")
 is
is  , we have
, we have![\[\norm{\rho^{(k\cdot n_0)} - \pi}_{\rm TV} \le (1-\delta)^k \norm{\rho^{(0)} - \pi}_{\rm TV} \le (1-\delta)^k \quad \text{for }k=0,1,2,\ldots,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f00ec64a989f2c387244cc13ca79cb63_l3.png "Rendered by QuickLaTeX.com")
 . Thus, since distance to stationarity is non-increasing, we have
. Thus, since distance to stationarity is non-increasing, we have![\[\norm{\rho^{(n)} - \pi}_{\rm TV} \le \norm{\rho^{(n_0 \cdot \lfloor n/n_0\rfloor)} - \pi}_{\rm TV} \le (1-\delta)^{\lfloor n/n_0\rfloor} \norm{\rho^{(0)} - \pi}_{\rm TV} \le (1-\delta)^{\lfloor n/n_0\rfloor}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c8c82df8e81ce5b1ca4fcbae23a11f4d_l3.png "Rendered by QuickLaTeX.com")
![\[\tau_{\rm mix} \coloneqq \min \left\{ n \ge 1 : \max_{\rho^{(0)}} \norm{\rho^{(n)} - \pi}_{\rm TV} \le \frac{1}{2e} \right\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ccf82253d6d08b59e651ef0c81a44e57_l3.png "Rendered by QuickLaTeX.com")
 steps:
steps: , then
, then  be the expected number of times the chain hits
be the expected number of times the chain hits  . Because the chain is primitive, all of the
. Because the chain is primitive, all of the ![\[\pi_i = \frac{a_i}{\sum_{j=1}^m a_j}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6abd189895ccf9707e3178558a0b5a2c_l3.png "Rendered by QuickLaTeX.com")
![\[a^\top P = a^\top. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d6885d4de71a8b8655bd542c1434c775_l3.png "Rendered by QuickLaTeX.com")
 denote the values of the chain and
denote the values of the chain and  denote the time at which the chain returns to
denote the time at which the chain returns to ![\[a_j = \sum_{n=1}^\infty \prob\{x_n = j, n_{\rm ret} > n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-713cac4a8c97033b1cba87fe2632d46d_l3.png "Rendered by QuickLaTeX.com")
![\[a_j = \prob\{x_1 = j\} + \sum_{n=2}^\infty \prob\{x_n = j, n_{\rm ret} > n\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1f62dfb50726f4884c2cb790970d1a75_l3.png "Rendered by QuickLaTeX.com")
 . For the second term, break into cases depending on the value of the chain at time
. For the second term, break into cases depending on the value of the chain at time  :
:
![\[a_j = P_{ij} + \sum_{n=2}^\infty \sum_{k\ne i} \prob\{x_{n-1} = k, n_{\rm ret} > n-1 \} P_{kj}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f243b52714b96a419b94980a12f078ee_l3.png "Rendered by QuickLaTeX.com")
 to
to  and exchange the order of summation to obtain
and exchange the order of summation to obtain![\[a_j = P_{ij} + \sum_{k\ne i} \left(\sum_{n=1}^\infty \prob\{x_n = k, n_{\rm ret} > n \}\right) P_{kj}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cad1677f621e66a91f850ab352cedce0_l3.png "Rendered by QuickLaTeX.com")
 . Thus, since
. Thus, since  , we have
, we have![\[a_j = a_iP_{ij} + \sum_{k\ne i} a_k P_{kj} = \sum_{k=1}^m a_k P_{kj},\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cecaa5c06b9ce9d9c3f4aa814dfc2323_l3.png "Rendered by QuickLaTeX.com")