The randomized Kaczmarz method is a method for solving systems of linear equations:
(1) ![\[\text{Find $x$ such that } Ax = b. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-29d9a4727a905120c7e471f5f6d88048_l3.png "Rendered by QuickLaTeX.com")
 will have dimensions
will have dimensions  . Beginning from an initial iterate
. Beginning from an initial iterate  , randomized Kaczmarz works as follows. For
, randomized Kaczmarz works as follows. For  :
:
- Sample a random row index
 with probability
with probability  .
. - Update to enforce the equation
 holds exactly:
holds exactly:
Throughout this post,![\[x_{t+1} \coloneqq x_t + \frac{b_{i_t} - a_{i_t}^\top x_t}{\norm{a_{i_t}}^2} a_{i_t}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-99cc99e6de2ca367d24ee6f20e610735_l3.png "Rendered by QuickLaTeX.com")
 denotes the
denotes the  th row of .
th row of .
What selection probabilities  should we use? The answer to this question may depend on whether the system (1) is consistent, i.e., whether it possesses a solution
should we use? The answer to this question may depend on whether the system (1) is consistent, i.e., whether it possesses a solution  . For this post, we assume (1) is consistent; see this previous post for a discussion of the inconsistent case.
. For this post, we assume (1) is consistent; see this previous post for a discussion of the inconsistent case.
The classical selection probabilities for randomized Kaczmarz were proposed by Strohmer and Vershynin in their seminal paper:
(1) ![\[p_j = \frac{\norm{a_j}^2}{\norm{A}_{\rm F}^2} \quad \text{for } j = 1,2,\ldots,n. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c0282178b77487afd710ad66bb50707b_l3.png "Rendered by QuickLaTeX.com")
(2) ![\[p_j = \frac{1}{n} \quad \text{for } j = 1,2,\ldots,n. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b0a9325d8b121aaab8d4547fa378ffed_l3.png "Rendered by QuickLaTeX.com")
Surprisingly, to me at least, the simpler strategy (2) often works better than (1). Here is a simple example. Define a matrix  with entries
with entries  , and choose the right-hand side
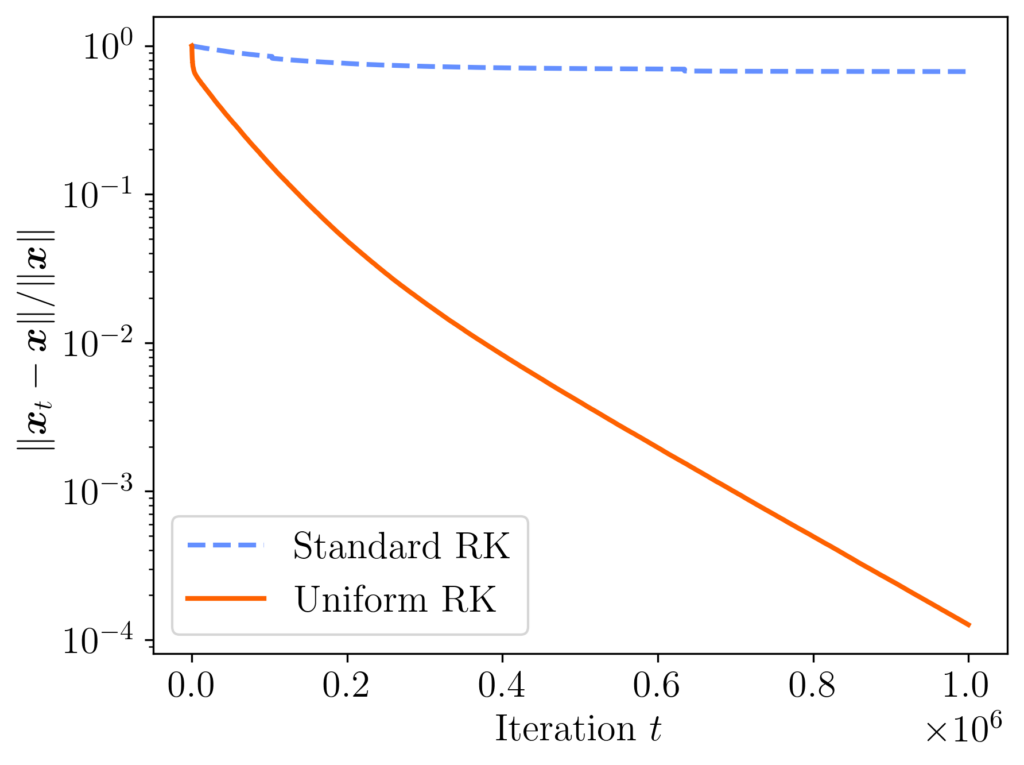
, and choose the right-hand side  with standard Gaussian random entries. The convergence of standard RK with sampling rule (1) and uniform RK with sampling rule (2) is shown in the plot below. After a million iterations, the difference in final accuracy is dramatic: the final relative error 0.00012 was uniform RK and 0.67 for standard RK!
with standard Gaussian random entries. The convergence of standard RK with sampling rule (1) and uniform RK with sampling rule (2) is shown in the plot below. After a million iterations, the difference in final accuracy is dramatic: the final relative error 0.00012 was uniform RK and 0.67 for standard RK!
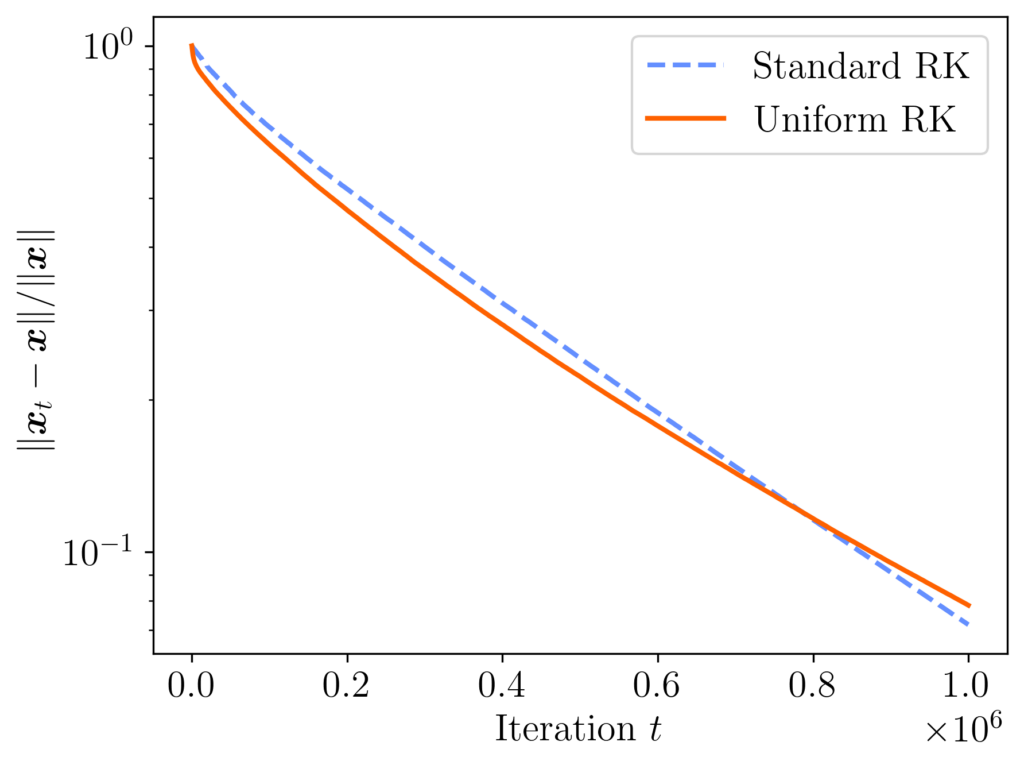
In fairness, uniform RK does not always outperform standard RK. If we change the matrix entries to  , then the performance of both methods is similar, with both methods ending with a relative error of about 0.07.
, then the performance of both methods is similar, with both methods ending with a relative error of about 0.07.
Another experiment, presented in section 4.1 of Strohmer and Vershynin’s original paper, provides an example where standard RK converges a bit more than twice as fast as uniform RK (called “simple RK” in their paper). Still, taken all together, these experiments demonstrate that standard RK (sampling probabilities (1)) is often not dramatically better than uniform RK (sampling probabilities (2)), and uniform RK can be much better than standard RK.
Randomized Kaczmarz Error Bounds
Why does uniform RK often outperform standard RK? To answer these questions, let’s look at the error bounds for the RK method.
The classical analysis of standard RK shows the method is geometrically convergent
(3) ![\[\expect\left[ \norm{x_t - x_\star}^2 \right] \le (1 - \kappa_{\rm dem}(A)^{-2})^t \norm{x_\star}^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1f788737bb459ed2beaab020bca517c2_l3.png "Rendered by QuickLaTeX.com")
(4) ![\[\kappa_{\rm dem}(A) = \frac{\norm{A}_{\rm F}}{\sigma_{\rm min}(A)} = \sqrt{\sum_i \left(\frac{\sigma_i(A)}{\sigma_{\rm min}(A)}\right)^2} \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-824557fbf90de5be0f9756f9089728aa_l3.png "Rendered by QuickLaTeX.com")
 are the singular values of . Recall that we have assumed the system
are the singular values of . Recall that we have assumed the system  is consistent, possessing a solution
is consistent, possessing a solution  . If there are multiple solutions, we let denote the solution of minimum norm.
. If there are multiple solutions, we let denote the solution of minimum norm.
What about uniform RK? Let  denote a diagonal matrix containing the inverse row norms, and introduce the row-equilibrated matrix
denote a diagonal matrix containing the inverse row norms, and introduce the row-equilibrated matrix  . The row-equilibrated matrix has been obtained from by rescaling each of its rows to have unit norm.
. The row-equilibrated matrix has been obtained from by rescaling each of its rows to have unit norm.
Uniform RK can then be related to standard RK run on the row-equilibrated matrix:
Fact (uniform sampling and row equilibration): Uniform RK on the system
as standard RK applied to the row-equilibrated system
.
Therefore, by (3), the iterates of uniform RK satisfy the bound
(5) ![\[\expect\left[ \norm{\hat{x}_t - x_\star}^2 \right] \le (1 - \kappa_{\rm dem}(D_A A)^{-2})^t \norm{x_\star}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3fc6402842af70a33954d0133066a5e3_l3.png "Rendered by QuickLaTeX.com")
or .
Row Equilibration and the Condition Number
Does row equilibration increase or decrease its condition number? What is the optimal way of scaling the rows of a matrix to minimize its condition number? These are classical questions in numerical linear algebra, and they were addressed in a classical 1969 paper of van der Sluis. These results were then summarized and generalized in Higham’s delightful monograph Accuracy and Stability of Numerical Algorithms. Here, we present answers to these questions using a variant of van der Sluis’ argument.
First, let’s introduce some more concepts and notation. Define the spectral norm condition number
![\[\kappa(A) \coloneqq \frac{\sigma_{\rm max}(A)}{\sigma_{\rm min}(A)}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3fb2bba4d99c34bc055f7043fccfe19c_l3.png "Rendered by QuickLaTeX.com")
 . Also, let
. Also, let  denote the set of all (nonsingular) diagonal matrices.
denote the set of all (nonsingular) diagonal matrices.
Our first result shows us that row equilibration never hurts the Demmel condition number by much. In fact, the row-equilibrated matrix produces a nearly optimal Demmel condition number when compared to any row scaling:
Theorem 1 (Row equilibration is a nearly optimal row scaling). Let
be wide
and full-rank, and let
denote the row-scaling of
![\[\kappa_{\rm dem}(D_AA) \le \sqrt{n}\cdot \min_{D \in \mathrm{Diag}} \kappa (DA) \le \sqrt{n}\cdot \min_{D \in \mathrm{Diag}} \kappa_{\rm dem} (DA).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ec117b2c8c81cbcfc88eeae87eac0aaa_l3.png "Rendered by QuickLaTeX.com")
By scaling the rows of a square or wide matrix to have unit norm, we bring the Demmel condition number to within a  factor of the optimal row scaling. In fact, we even bring the Demmel condition number to within a factor of the optimal spectral norm condition number for any row scaling.
factor of the optimal row scaling. In fact, we even bring the Demmel condition number to within a factor of the optimal spectral norm condition number for any row scaling.
Since the convergence rate for randomized Kaczmarz is  , this result shows that implementing randomized Kaczmarz with uniform sampling yields to a convergence rate that is within a factor of
, this result shows that implementing randomized Kaczmarz with uniform sampling yields to a convergence rate that is within a factor of  of the optimal convergence rate using any possible sampling distribution.
of the optimal convergence rate using any possible sampling distribution.
This result shows us that row equilibration can’t hurt the Demmel condition number by much. But can it help? The following proposition shows that it can help a lot for some problems.
Proposition 2 (Row equilibration can help a lot). Let
denote the maximum ratio between two row norms:
Then the Demmel condition number of the original matrix
Moreover, for every
, there exists a matrix
where this bound is nearly attained:
![\[\gamma \coloneqq \frac{ \max_i \norm{a_i}}{\min_i \norm{a_i}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9289f9e9a0f729efb516fbda78ac3453_l3.png "Rendered by QuickLaTeX.com")
Taken together, Theorem 1 and Proposition 2 show that row equilibration often improves the Demmel condition number, and never increases it by that much. Consequently, uniform RK often converges faster than standard RK for square (or short wide) linear systems, and it never converges much slower.
Proof of Theorem 1
We follow Higham’s approach. Each of the rows of each have unit norm, so
(7) ![\[\norm{D_AA}_{\rm F} = \sqrt{n}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-dc083ac4d61189b0851e1495ff99f25d_l3.png "Rendered by QuickLaTeX.com")
can be written in terms of the Moore–Penrose pseudoinverse  as follows
as follows ![\[\frac{1}{\sigma_{\rm min}(D_A A)} = \norm{A^\dagger D_A^{-1}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c96cc4653bb180133ed40dd1c84687fd_l3.png "Rendered by QuickLaTeX.com")
 denotes the spectral norm. Then for any nonsingular diagonal matrix
denotes the spectral norm. Then for any nonsingular diagonal matrix  , we have
, we have (8) ![\[\frac{1}{\sigma_{\rm min}(D_A A)} = \norm{A^\dagger D^{-1} (DD_A^{-1})} \le \norm{A^\dagger D^{-1}} \norm{DD_A^{-1}} = \frac{\norm{DD_A^{-1}}}{\sigma_{\rm min}(DA)}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a65986b5ef3ac5975280bffcd2fcb927_l3.png "Rendered by QuickLaTeX.com")
 is diagonal its spectral norm is
is diagonal its spectral norm is ![\[\norm{DD_A^{-1}} = \max \left\{ \frac{|D_{ii}|}{|(D_A)_{ii}|} : 1\le i \le n \right\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-705ca33a5372c0bdf858770f9d204436_l3.png "Rendered by QuickLaTeX.com")
 are
are  , so
, so ![\[\norm{DD_A^{-1}} = \max \left\{ |D_{ii}|\norm{a_i} : 1\le i\le n \right\}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b8026880c5418d6aac0894b839079753_l3.png "Rendered by QuickLaTeX.com")
 . The maximum row norm is always less than the largest singular value of , so
. The maximum row norm is always less than the largest singular value of , so  . Therefore, combining this result, (7), and (9), we obtain
. Therefore, combining this result, (7), and (9), we obtain ![\[\kappa_{\rm dem}(D_AA) \le \sqrt{n} \cdot \frac{\sigma_{\rm max}(DA)}{\sigma_{\rm min}(DA)} = \sqrt{n}\cdot \kappa (DA).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9e73680b6f4fe21817d43adb57a457ff_l3.png "Rendered by QuickLaTeX.com")
 , we are free to minimize over , leading to the first inequality in the theorem:
, we are free to minimize over , leading to the first inequality in the theorem: ![\[\kappa_{\rm dem}(D_AA) \le \sqrt{n}\cdot \min_{D \in \mathrm{Diag}} \kappa (DA).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e18d74284219efc70ced6833db98a733_l3.png "Rendered by QuickLaTeX.com")
Proof of Proposition 2
Write  . Using the Moore–Penrose pseudoinverse again, write
. Using the Moore–Penrose pseudoinverse again, write
(10) ![\[\kappa_{\rm dem}(A) = \norm{D_A^{-1}(D_AA)}_{\rm F} \norm{(D_A A)^\dagger D_A}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-50cf827241cc20f905230e4a51946d0b_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{BC}_{\rm F} \le \norm{B}\norm{C}_{\rm F}, \quad \norm{BC} \le\norm{B}\norm{C}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-051f8f43c351dcc02a4d3342d55b5455_l3.png "Rendered by QuickLaTeX.com")
![\[\kappa_{\rm dem}(A) \le \norm{D_A^{-1}}\norm{D_AA}_{\rm F} \norm{(D_A A)^\dagger} \norm{D_A}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1d3aa06275558feecad7fe4a38c3f64a_l3.png "Rendered by QuickLaTeX.com")
 and
and  . We conclude
. We conclude ![\[\kappa_{\rm dem}(A) \le \gamma \cdot \kappa_{\rm dem}(D_A A).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d842439abf3ace1c3c590d983ec36107_l3.png "Rendered by QuickLaTeX.com")
To show this bound is nearly obtained, introduce  . Then
. Then  with
with  and
and
![\[\kappa_{\rm dem}(A_\gamma) = \frac{\norm{A_{\gamma}}_{\rm F}}{\sigma_{\rm min}(A_\gamma)} = \frac{\sqrt{(n-1)\gamma^2+1}}{1} \ge \sqrt{n} \cdot \sqrt{1-\frac{1}{n}} \cdot \gamma.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0216b29d23ab394e7040423bd9a13ebe_l3.png "Rendered by QuickLaTeX.com")
![\[\kappa_{\rm dem}(A_\gamma) \ge \sqrt{1-\frac{1}{n}} \cdot \gamma \cdot \kappa_{\rm dem}(D_{A_\gamma}A_\gamma).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9ff68e369e8f22f56563fdc443894ce4_l3.png "Rendered by QuickLaTeX.com")
Practical Guidance
What does this theory mean for practice? Ultimately, single-row randomized Kaczmarz is often not the best algorithm for the job for ordinary square (or short–wide) linear systems, anyway—block Kaczmarz or (preconditioned) Krylov methods have been faster in my experience. But, supposing that we have locked in (single-row) randomized Kaczmarz as our algorithm, how should we implement it?
This question is hard to answer, because there are examples where standard RK and uniform RK both converge faster than the other. Theorem 1 suggests uniform RK can require as many as  more iterations than standard RK on a worst-case example, which can be a big difference for large problems. But, particularly for badly row-scaled problems, Proposition 2 shows that uniform RK can dramatically outcompete standard RK. Ultimately, I would give two answers.
more iterations than standard RK on a worst-case example, which can be a big difference for large problems. But, particularly for badly row-scaled problems, Proposition 2 shows that uniform RK can dramatically outcompete standard RK. Ultimately, I would give two answers.
First, if the matrix has already been carefully designed to be well-conditioned and computing the row norms is not computationally burdensome, then standard RK may be worth the effort. Despite this theory suggesting it can do quite badly, it took a bit of effort to construct a simple example of a “bad” matrix where uniform RK significantly outcompeted standard RK. (On most examples I constructed, the rate of convergence of the two methods were similar.)
Second, particularly for the largest systems where you only want to make a small number of total passes over the matrix, expending a full pass over the matrix to compute the row norms is a significant expense. And, for poorly row-scaled matrices, sampling using the squared row norms can hurt the convergence rate. Based on these observations, given a matrix of unknown row scaling and conditioning or given a small budget of passes over the matrix, I would use the uniform RK method over the standard RK method.
Finally, let me again emphasize that the theoretical results Theorem 1 and Proposition 2 only apply to square or wide matrices . Uniform RK also appears to work for consistent systems with a tall matrix, but I am unaware of a theoretical result comparing the Demmel condition numbers of and that applies to tall matrices. And for inconsistent systems of equations, it’s a whole different story.
Edit: After initial publication of this post, Mark Schmidt shared that the observation that uniform RK can outperform standard RK was made nearly ten years ago in section 4.2 of the following paper. They support this observation with a different mathematical justification
 , the method works by repeating the following two steps for
, the method works by repeating the following two steps for ![\[\prob\{ i_t = j\} = \frac{\norm{a_j}^2}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-81c1ff56386b62fc105c714e21f13f5c_l3.png "Rendered by QuickLaTeX.com")
 onto the solution space of the equation
onto the solution space of the equation  .
. ), RK is
), RK is ![\[\expect\left[ \norm{x_t - x_\star}^2 \right] \le (1 - \kappa_{\rm dem}^{-2})^t \norm{x_\star}^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-02d23e54a2a02cf261b7ab8afc0f4b90_l3.png "Rendered by QuickLaTeX.com")
![\[\kappa_{\rm dem} = \frac{\norm{A}_{\rm F}}{\sigma_{\rm min}(A)} = \sqrt{\sum_i \left(\frac{\sigma_i(A)}{\sigma_{\rm min}(A)}\right)^2} \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0a01bce740f28deced2d1a8b4e6e1002_l3.png "Rendered by QuickLaTeX.com")
 , where
, where  is the
is the  is the
is the  , so it takes roughly
, so it takes roughly  row accesses to reduce the error by a constant factor. Compare this to gradient descent, which requires
row accesses to reduce the error by a constant factor. Compare this to gradient descent, which requires  row accesses.
row accesses. , which can be expressed using the
, which can be expressed using the  .
.![\[x_\star = \operatorname{argmin}_{x \in \real^d} \norm{b - Ax}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9052e54b28c6061d7a56c05ca254f154_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\mathbb{E}[x_t] - x_\star}^2 \le (1 - \kappa_{\rm dem}^{-2})^{2t} \norm{x_\star}^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a54409c570b03a8e2e3607c316004f4d_l3.png "Rendered by QuickLaTeX.com")
 .
. which could then be averaged together. This approach is inefficient as each solution
which could then be averaged together. This approach is inefficient as each solution  is computed separately.
is computed separately. , chosen so that the bias
, chosen so that the bias ![\norm{\expect[x_{t_{\rm b}}] - x_\star}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-03b1f60b09d6e66904287aa5e6cd6009_l3.png "Rendered by QuickLaTeX.com") is small. For each
is small. For each  ,
,  is a nearly unbiased approximation to the least-squares solution
is a nearly unbiased approximation to the least-squares solution ![\[\overline{x}_t = \frac{x_{t_{\rm b} +1} + x_{t_{\rm b}+2} + \cdots + x_t}{t-t_{\rm b}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-53375d695acfc74d6ea111d3a1b32d29_l3.png "Rendered by QuickLaTeX.com")
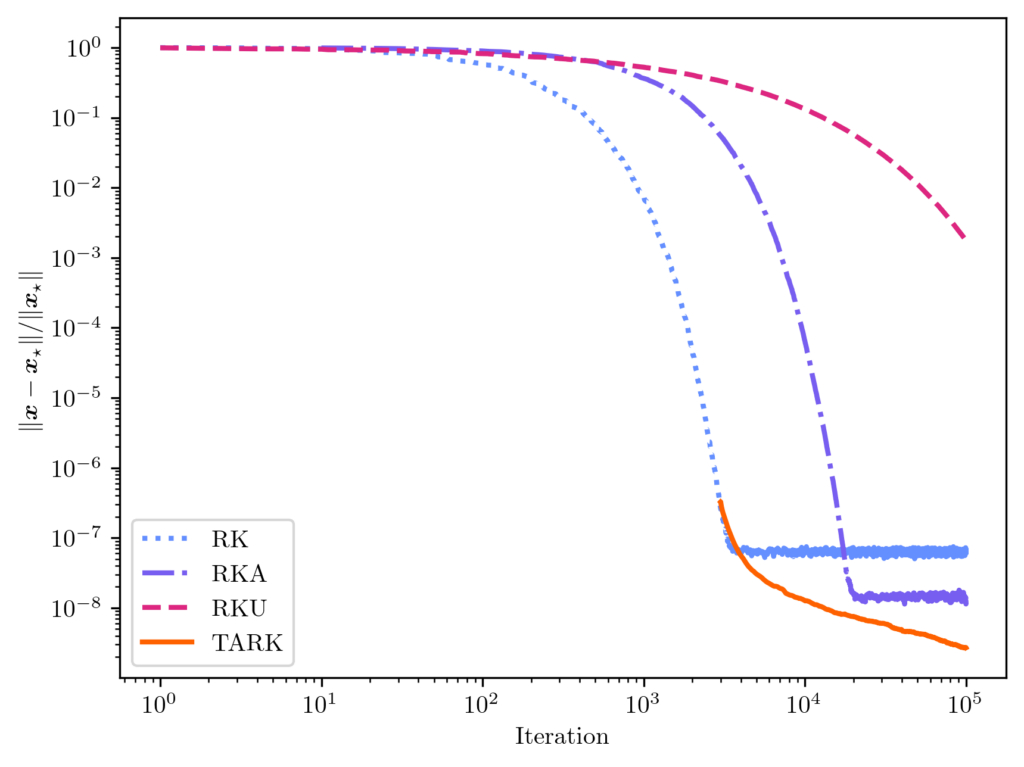
 is the tail-averaged randomized Kaczmarz (TARK) estimator. By Theorem 1, we know the TARK estimator has an exponentially small bias:
is the tail-averaged randomized Kaczmarz (TARK) estimator. By Theorem 1, we know the TARK estimator has an exponentially small bias: ![\[\norm{\expect[\overline{x}_t] - x_\star} \le (1 - \kappa_{\rm dem}^{-2})^{2(t_{\rm b}+1)} \norm{x_\star}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-89806db87c210bfdd9cbd0e800d65e85_l3.png "Rendered by QuickLaTeX.com")
![\[\expect [\norm{\overline{x}_t - x_\star}^2] \le (1-\kappa_{\rm dem}^{-2})^{t_{\rm b}+1} \norm{x_\star}^2 + \frac{2\kappa_{\rm dem}^4}{t-t_{\rm b}} \frac{\norm{b-Ax_\star}^2}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d30cb224e4284f0840a46a9757196abf_l3.png "Rendered by QuickLaTeX.com")
 . While the Monte Carlo rate of convergence may be unappealing,
. While the Monte Carlo rate of convergence may be unappealing,  ;
;  . We found this underrelaxation parameter to lead to a smaller error than the other popular underrelaxation parameter schedule
. We found this underrelaxation parameter to lead to a smaller error than the other popular underrelaxation parameter schedule  .
.
![\[\prob \{ i_t = j \} = \frac{\norm{a_j}^2}{\norm{A}_{\rm F}^2} \eqqcolon p^{\rm RK}_j.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-072dd81a7e854128bf0258a1836003de_l3.png "Rendered by QuickLaTeX.com")
 .
.
 .
.![\[\prob \{i_t = j\} = p_j.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-95b2f6411ef8d9b8c9b5b61acf6bc928_l3.png "Rendered by QuickLaTeX.com")
![\[D \coloneqq \diag\left( \sqrt{\frac{p_j}{p_j^{\rm RK}}} : j =1,\ldots,n\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bc930770f7b4e20afffe903a4ab372ba_l3.png "Rendered by QuickLaTeX.com")
 is equivalent to the standard RK algorithm run on the diagonally reweighted least-squares problem
is equivalent to the standard RK algorithm run on the diagonally reweighted least-squares problem ![\[x_{\rm weighted} = \argmin_{x\in\real^d} \norm{Db-(DA)x}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3e1818420a485f35a47361344560d2b1_l3.png "Rendered by QuickLaTeX.com")
 rather than the original least-squares solution
rather than the original least-squares solution  [mfn}Note that, for this experiment we represent the polynomial
[mfn}Note that, for this experiment we represent the polynomial  using its monomial coefficients
using its monomial coefficients  , which has
, which has  equispaced points. We compare the unweighted least-squares solution (orange solid curve) to the weighted least-squares solution using uniform RK weights
equispaced points. We compare the unweighted least-squares solution (orange solid curve) to the weighted least-squares solution using uniform RK weights  (blue dash-dotted curve). These two curves differ meaningfully, with the weighted least-squares solution having higher error at the ends of the interval but more accuracy in the middle. These differences can be explained looking at the weights (diagonal entries of
(blue dash-dotted curve). These two curves differ meaningfully, with the weighted least-squares solution having higher error at the ends of the interval but more accuracy in the middle. These differences can be explained looking at the weights (diagonal entries of 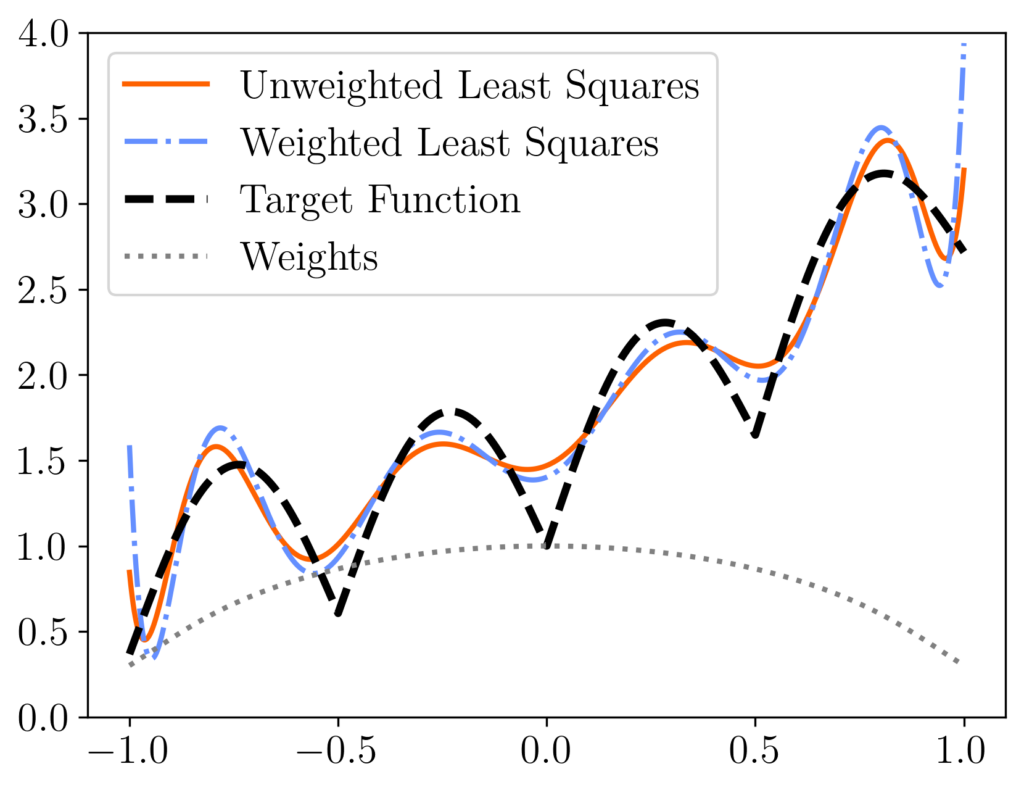
![\[x_{t+1} = \left( I - \frac{a_{i_t}^{\vphantom{\top}}a_{i_t}^\top}{\norm{a_{i_t}}^2} \right)x_t + \frac{b_{i_t}a_{i_t}}{\norm{a_{i_t}}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cccfb54762bb990499c96331e7019309_l3.png "Rendered by QuickLaTeX.com")
 denote the
denote the ![\begin{align*}\expect_{i_t}[x_{t+1}] &= \sum_{j=1}^n \left[\left( I - \frac{a_j^{\vphantom{\top}} a_j^\top}{\norm{a_j}^2} \right)x_t + \frac{b_ja_j}{\norm{a_j}^2}\right] \prob\{i_t=j\}\\ &=\sum_{j=1}^n \left[\left( \frac{\norm{a_j}^2}{\norm{A}_{\rm F}^2}I - \frac{a_j^{\vphantom{\top}} a_j^\top}{\norm{A}_{\rm F}^2} \right)x_t + \frac{b_ja_j}{\norm{A}_{\rm F}^2}\right].\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0a7f7b3bfad51b7094348db94d2d4254_l3.png "Rendered by QuickLaTeX.com")
 and
and  directly. Therefore, we obtain
directly. Therefore, we obtain ![\[\expect_{i_t}[x_{t+1}] = \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right) x_t + \frac{A^\top b}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-de4ded17daf001dde92c26025e9c14f3_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[x_{t+1}] = \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right) \expect[x_t] + \frac{A^\top b}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-24c5bfe6c1ea70293055deb68a3df117_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[x_t] = \left[\sum_{i=0}^{t-1} \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i \right]\cdot\frac{A^\top b}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-eb47c96091b1187b53c318589b696693_l3.png "Rendered by QuickLaTeX.com")
![\expect[x_t]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fa98c6708608ae4bf5513cf53e74597c_l3.png "Rendered by QuickLaTeX.com") using a matrix
using a matrix  satisfies the formula
satisfies the formula ![\[\sum_{i=0}^\infty y^i = (1-y)^{-1}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2d95246c2816e550018d080c58c60240_l3.png "Rendered by QuickLaTeX.com")
 , we get
, we get ![\[\sum_{i=0}^\infty (1-x)^i = x^{-1}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-726e8fae76877e0ec1f03efab333ec2e_l3.png "Rendered by QuickLaTeX.com")
 . With a little effort, one can check that the same formula
. With a little effort, one can check that the same formula![\[\sum_{i=0}^\infty (I-X)^i = X^{-1}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1389cddfba9ee14bcbf4293f018c78c9_l3.png "Rendered by QuickLaTeX.com")
 satisfying
satisfying  . These conditions hold for the matrix
. These conditions hold for the matrix  since
since ![\[\left(\frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^{-1} = \sum_{i=0}^\infty \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8d1be156303c168d2de83dbde76e44d6_l3.png "Rendered by QuickLaTeX.com")
![\[\left(\frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^{-1} = \sum_{i=0}^{t-1} \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i + \sum_{i=t}^\infty \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-08f4b1a705439315fe0fc038e059d01c_l3.png "Rendered by QuickLaTeX.com")
 , we obtain
, we obtain ![\[\expect[x_t] = x_\star - \left[\sum_{i=t}^\infty \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i \right]\cdot\frac{A^\top b}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d973041dba49ba471bbfb6b3d4c2b463_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[x_t] - x_\star = - \left(I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^t \left[\sum_{i=0}^\infty \left( I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^i \right]\cdot\frac{A^\top b}{\norm{A}_{\rm F}^2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8238e65e7b7df2013504f2a6f71799e6_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[x_t] - x_\star = - \left(I - \frac{A^\top A}{\norm{A}_{\rm F}^2}\right)^t x_\star.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3cbe72663f8ef13c762213b5592bb5d2_l3.png "Rendered by QuickLaTeX.com")
![\[\norm{\expect[x_t] - x_\star}^2 \le \norm{I - \frac{A^\top A}{\norm{A}_{\rm F}^2}}^{2t} \norm{x}_\star^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e663370119bd02900da0aa4f7b6faf03_l3.png "Rendered by QuickLaTeX.com")
 . Let
. Let  be a (
be a ( . Then
. Then ![\[I - \frac{A^\top A}{\norm{A}_{\rm F}^2} = I - V \cdot\frac{\Sigma^2}{\norm{A}_{\rm F}^2} \cdot V^\top = V \left( I - \frac{\Sigma^2}{\norm{A}_{\rm F}^2}\right)V^\top.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-468566feb9b39f9e0dd616b47f324ad5_l3.png "Rendered by QuickLaTeX.com")
 and whose eigenvalues are the diagonal entries of the matrix
and whose eigenvalues are the diagonal entries of the matrix ![\[I - \Sigma^2/\norm{A}_{\rm F}^2 = \diag(1 - \sigma^2_{\rm max}(A)/\norm{A}_{\rm F}^2,\ldots,1-\sigma_{\rm min}^2(A)/\norm{A}_{\rm F}^2).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4bc7dac794d8913157b82fd0df23e41d_l3.png "Rendered by QuickLaTeX.com")
 . We have invoked the definition of the Demmel condition number (2). Therefore, plugging into (7), we obtain
. We have invoked the definition of the Demmel condition number (2). Therefore, plugging into (7), we obtain ![\[\norm{\expect[x_t] - x_\star}^2 \le \left(1-\kappa_{\rm dem}^{-2}\right)^{2t} \norm{x}_\star^2,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7c29ce0386ec23c163afab561f181af1_l3.png "Rendered by QuickLaTeX.com")